Kolejną najważniejszą właściwością zmiennej losowej po oczekiwaniu matematycznym jest jej rozproszenie, definiowane jako średniokwadratowe odchylenie od średniej:
Jeśli zostanie to zaznaczone, wariancja VX będzie wartością oczekiwaną.Jest to cecha „rozrzutu” rozkładu X.
Jako prosty przykład obliczenia wariancji załóżmy, że właśnie otrzymaliśmy ofertę nie do odrzucenia: ktoś dał nam dwa certyfikaty na tę samą loterię. Organizatorzy loterii sprzedają co tydzień 100 losów, biorąc udział w osobnym losowaniu. Losowanie wybiera jeden z tych losów w jednolitym procesie losowym – każdy los ma taką samą szansę na wybranie, a właściciel tego szczęśliwego losu otrzymuje sto milionów dolarów. Pozostałych 99 posiadaczy losów na loterię nie wygrywa nic.
Prezent możemy wykorzystać na dwa sposoby: kupić albo dwa losy w jednej loterii, albo po jednym, aby wziąć udział w dwóch różnych loteriach. Która strategia jest lepsza? Spróbujmy to przeanalizować. W tym celu oznaczmy przez zmienne losowe wielkość naszej wygranej na pierwszym i drugim losie. Oczekiwana wartość w milionach wynosi
i to samo dotyczy wartości oczekiwanych, które się sumują, więc nasza średnia całkowita wypłata będzie wynosić
niezależnie od przyjętej strategii.
Jednak obie strategie wydają się różne. Wyjdźmy poza wartości oczekiwane i przestudiujmy pełny rozkład prawdopodobieństwa

Jeśli kupimy dwa losy w jednej loterii, to nasze szanse na wygranie niczego wyniosą 98% i 2% - szanse na wygranie 100 milionów. Jeśli kupimy losy na różne losowania, liczby będą przedstawiały się następująco: 98,01% - szansa, że nic nie wygramy, czyli nieco większa niż dotychczas; 0,01% - szansa na wygranie 200 milionów, także nieco więcej niż dotychczas; a szansa na wygranie 100 milionów wynosi obecnie 1,98%. Zatem w drugim przypadku rozkład wielkości jest nieco bardziej rozproszony; środkowa wartość, 100 milionów dolarów, jest nieco mniej prawdopodobna, podczas gdy wartości skrajne są bardziej prawdopodobne.
Rozproszenie ma odzwierciedlać właśnie tę koncepcję rozproszenia zmiennej losowej. Mierzymy rozrzut poprzez kwadrat odchylenia zmiennej losowej od jej oczekiwań matematycznych. Zatem w przypadku 1 wariancja będzie
w przypadku 2 wariancja wynosi
Jak się spodziewaliśmy, ta druga wartość jest nieco większa, gdyż rozkład w przypadku 2 jest nieco bardziej rozłożony.
Kiedy pracujemy z wariancjami, wszystko jest podnoszone do kwadratu, więc wynikiem mogą być całkiem duże liczby. (Mnożnik wynosi jeden bilion, to powinno robić wrażenie
nawet gracze przyzwyczajeni do dużych zakładów.) Aby przeliczyć wartości na bardziej znaczącą pierwotną skalę, często bierze się pierwiastek kwadratowy z wariancji. Wynikowa liczba nazywana jest odchyleniem standardowym i jest zwykle oznaczana grecką literą a:
Standardowe odchylenia wielkości dla naszych dwóch strategii loteryjnych wynoszą . Pod pewnymi względami druga opcja jest o około 71 247 dolarów bardziej ryzykowna.
Jak wariancja pomaga w wyborze strategii? To nie jest jasne. Strategia o większej wariancji jest bardziej ryzykowna; ale co jest lepsze dla naszego portfela – ryzyko czy bezpieczna gra? Dajmy sobie szansę na zakup nie dwóch biletów, ale wszystkich na sto. Wtedy moglibyśmy zagwarantować wygraną w jednej loterii (a wariancja wynosiłaby zero); albo możesz zagrać w stu różnych losowaniach, nie otrzymując nic z prawdopodobieństwem, ale mając niezerową szansę na wygranie aż do dolarów. Wybór jednej z tych alternatyw wykracza poza zakres tej książki; jedyne, co możemy tutaj zrobić, to wyjaśnić, jak wykonać obliczenia.
W rzeczywistości istnieje prostszy sposób obliczenia wariancji niż bezpośrednie użycie definicji (8.13). (Istnieją wszelkie powody, aby podejrzewać, że kryje się tu jakaś ukryta matematyka; w przeciwnym razie dlaczego wariancja w przykładach loterii okazałaby się całkowitą wielokrotnością? Mamy
ponieważ - stała; stąd,
„Wariancja to średnia kwadratu minus kwadrat średniej”.
Np. w zadaniu loteryjnym okazuje się, że średnia wynosi czyli Odejmowanie (kwadrat średniej) daje wyniki, które uzyskaliśmy już wcześniej w trudniejszy sposób.
Istnieje jednak jeszcze prostszy wzór, który można zastosować, gdy obliczamy dla niezależnych X i Y. Mamy

ponieważ, jak wiemy, dla niezależnych zmiennych losowych Zatem

„Wariancja sumy niezależnych zmiennych losowych jest równa sumie ich wariancji”.
Dlatego rozrzut całkowitych wygranych dla dwóch losów na loterię w dwóch różnych (niezależnych) loteriach będzie wynosić. Odpowiednia wartość rozrzutu dla niezależnych losów na loterię będzie wynosić
Wariancję sumy punktów wyrzuconych na dwóch kostkach można obliczyć za pomocą tego samego wzoru, ponieważ jest to suma dwóch niezależnych zmiennych losowych. Mamy
dla właściwej kostki; zatem w przypadku przesuniętego środka masy
dlatego też, jeśli obie kostki mają przesunięty środek masy. Należy zwrócić uwagę, że w tym drugim przypadku wariancja jest większa, choć częściej niż w przypadku zwykłej kostki przyjmuje wartość średnią 7. Jeśli naszym celem jest wyrzucenie większej liczby szczęśliwych siódemek, wariancja nie jest najlepszym wskaźnikiem sukcesu.
OK, ustaliliśmy, jak obliczyć wariancję. Ale nie daliśmy jeszcze odpowiedzi na pytanie, dlaczego konieczne jest obliczanie wariancji. Każdy to robi, ale dlaczego? Głównym powodem jest nierówność Czebyszewa, która ustanawia ważną właściwość dyspersji:
(Nierówność ta różni się od nierówności Czebyszewa dla sum, które napotkaliśmy w Rozdziale 2.) Na poziomie jakościowym (8.17) stwierdza, że zmienna losowa X rzadko przyjmuje wartości odległe od swojej średniej, jeśli jej wariancja VX jest mała. Dowód
zarządzanie jest niezwykle proste. Naprawdę,

dzielenie przez kończy dowód.
Jeżeli oznaczymy oczekiwanie matematyczne przez a i odchylenie standardowe przez a i zastąpimy w (8.17) wtedy warunek zmieni się w zatem, otrzymamy z (8.17)
Zatem X będzie mieścić się w - razy odchyleniu standardowym swojej średniej, z wyjątkiem przypadków, w których prawdopodobieństwo nie przekracza. Zmienna losowa będzie mieścić się w zakresie 2a co najmniej 75% prób; od do - przynajmniej na 99%. Są to przypadki nierówności Czebyszewa.
Jeśli rzucisz raz kilkoma kostkami, całkowita suma punktów we wszystkich rzutach prawie zawsze będzie bliska.Powód tego jest następujący: wariancja niezależnych rzutów będzie wynosić Wariancja oznacza odchylenie standardowe wszystkiego
Zatem z nierówności Czebyszewa dowiadujemy się, że suma punktów będzie znajdować się pomiędzy
przynajmniej w 99% wszystkich rzutów poprawnymi kostkami. Na przykład wynik miliona rzutów z prawdopodobieństwem większym niż 99% będzie wynosić od 6,976 miliona do 7,024 miliona.
Ogólnie rzecz biorąc, niech X będzie dowolną zmienną losową w przestrzeni prawdopodobieństwa Π mającą skończone oczekiwanie matematyczne i skończone odchylenie standardowe a. Następnie możemy wprowadzić pod uwagę przestrzeń prawdopodobieństwa Pn, której zdarzenia elementarne są -ciągami, gdzie każdy , a prawdopodobieństwo definiuje się jako
Jeśli teraz zdefiniujemy zmienne losowe za pomocą wzoru
następnie wartość
będzie sumą niezależnych zmiennych losowych, co odpowiada procesowi sumowania niezależnych realizacji wartości X na P. Oczekiwanie matematyczne będzie równe, a odchylenie standardowe - ; dlatego też średnia wartość realizacji,
![]()
będzie się wahać od do przez co najmniej 99% okresu. Innymi słowy, jeśli wybierzesz wystarczająco duży, średnia arytmetyczna niezależnych testów będzie prawie zawsze bardzo bliska wartości oczekiwanej (w podręcznikach teorii prawdopodobieństwa udowadnia się jeszcze silniejsze twierdzenie, zwane mocnym prawem wielkich liczb; ale dla nas prosty wniosek z nierówności Czebyszewa, którą właśnie usunęliśmy.)
Czasami nie znamy charakterystyki przestrzeni prawdopodobieństwa, ale musimy oszacować matematyczne oczekiwanie zmiennej losowej X na podstawie powtarzanych obserwacji jej wartości. (Na przykład możemy chcieć średniej temperatury styczniowego południa w San Francisco lub możemy chcieć znać oczekiwaną długość życia, na której agenci ubezpieczeniowi powinni opierać swoje obliczenia.) Jeśli mamy do dyspozycji niezależne obserwacje empiryczne, możemy założyć, że prawdziwe oczekiwanie matematyczne jest w przybliżeniu równe
![]()
Możesz także oszacować wariancję za pomocą wzoru
Patrząc na tę formułę, można by pomyśleć, że zawiera ona błąd typograficzny; Wydawałoby się, że powinno być tak jak w (8.19), gdyż rzeczywistą wartość dyspersji wyznacza się w (8.15) poprzez wartości oczekiwane. Jednak zastąpienie tutaj przez pozwala nam uzyskać lepsze oszacowanie, gdyż z definicji (8.20) wynika, że
![]()
Oto dowód:

(W tych obliczeniach polegamy na niezależności obserwacji, gdy zastępujemy przez )
W praktyce, aby ocenić wyniki eksperymentu ze zmienną losową X, zwykle oblicza się średnią empiryczną i empiryczne odchylenie standardowe, a następnie zapisuje odpowiedź w postaci Tutaj są na przykład wyniki rzutu parą kostek, prawdopodobnie poprawne.
Oprócz praw dystrybucji można również opisać zmienne losowe charakterystyki numeryczne .
Oczekiwanie matematyczne M (x) zmiennej losowej nazywa się jej wartością średnią.
Matematyczne oczekiwanie dyskretnej zmiennej losowej oblicza się za pomocą wzoru
Gdzie – wartości zmiennych losowych, s. 23 I - ich prawdopodobieństwa.
Rozważmy właściwości oczekiwań matematycznych:
1. Matematyczne oczekiwanie na stałą jest równe samej stałej
2. Jeżeli zmienną losową pomnożymy przez pewną liczbę k, wówczas oczekiwanie matematyczne zostanie pomnożone przez tę samą liczbę
M (kx) = kM (x)
3. Oczekiwanie matematyczne sumy zmiennych losowych jest równe sumie ich oczekiwań matematycznych
M (x 1 + x 2 + … + x n) = M (x 1) + M (x 2) +…+ M (x n)
4. M (x 1 - x 2) = M (x 1) - M (x 2)
5. Dla niezależnych zmiennych losowych x 1, x 2, … x n, matematyczne oczekiwanie iloczynu jest równe iloczynowi ich matematycznych oczekiwań
M (x 1, x 2, ... x n) = M (x 1) M (x 2) ... M (x n)
6. M (x - M (x)) = M (x) - M (M (x)) = M (x) - M (x) = 0
Obliczmy oczekiwanie matematyczne dla zmiennej losowej z Przykładu 11.
M(x) = = ![]() .
.
Przykład 12. Niech zmienne losowe x 1, x 2 zostaną odpowiednio określone przez prawa rozkładu:
x 1 Tabela 2
x 2 Tabela 3
Obliczmy M (x 1) i M (x 2)
M (x 1) = (- 0,1) 0,1 + (- 0,01) 0,2 + 0 0,4 + 0,01 0,2 + 0,1 0,1 = 0
M (x 2) = (- 20) 0,3 + (- 10) 0,1 + 0 0,2 + 10 0,1 + 20 0,3 = 0
Oczekiwania matematyczne obu zmiennych losowych są takie same – są równe zeru. Różny jest jednak charakter ich dystrybucji. Jeśli wartości x 1 niewiele różnią się od ich matematycznych oczekiwań, to wartości x 2 różnią się w dużym stopniu od ich matematycznych oczekiwań, a prawdopodobieństwa takich odchyleń nie są małe. Przykłady te pokazują, że na podstawie wartości średniej nie da się określić, jakie odchylenia od niej występują, zarówno mniejsze, jak i większe. Zatem przy tych samych średnich rocznych opadach na dwóch obszarach nie można powiedzieć, że obszary te są równie korzystne dla prac rolniczych. Podobnie na podstawie wskaźnika przeciętnego wynagrodzenia nie można ocenić udziału pracowników wysoko i nisko opłacanych. Dlatego wprowadzono charakterystykę numeryczną - dyspersja D(x) , który charakteryzuje stopień odchylenia zmiennej losowej od jej wartości średniej:
re (x) = M (x - M (x)) 2 . (2)
Dyspersja to matematyczne oczekiwanie kwadratu odchylenia zmiennej losowej od oczekiwań matematycznych. Dla dyskretnej zmiennej losowej wariancję oblicza się ze wzoru:
D(x)= ![]() =
= ![]() (3)
(3)
Z definicji dyspersji wynika, że D (x) 0.
Właściwości dyspersji:
1. Wariancja stałej wynosi zero
2. Jeżeli zmienną losową pomnożymy przez pewną liczbę k, to wariancja zostanie pomnożona przez kwadrat tej liczby
D (kx) = k 2 D (x)
3. D (x) = M (x 2) – M 2 (x)
4. Dla parami niezależnych zmiennych losowych x 1 , x 2 , … x n wariancja sumy jest równa sumie wariancji.
re (x 1 + x 2 + … + x n) = re (x 1) + re (x 2) +…+ re (x n)
Obliczmy wariancję dla zmiennej losowej z Przykładu 11.
Oczekiwanie matematyczne M (x) = 1. Zatem zgodnie ze wzorem (3) mamy:
re (x) = (0 – 1) 2 1/4 + (1 – 1) 2 1/2 + (2 – 1) 2 1/4 =1 1/4 +1 1/4= 1/2
Pamiętaj, że łatwiej jest obliczyć wariancję, jeśli użyjesz właściwości 3:
D (x) = M (x 2) – M 2 (x).
Obliczmy wariancje dla zmiennych losowych x 1 , x 2 z Przykładu 12, korzystając z tego wzoru. Oczekiwania matematyczne obu zmiennych losowych wynoszą zero.
D (x 1) = 0,01 0,1 + 0,0001 0,2 + 0,0001 0,2 + 0,01 0,1 = 0,001 + 0,00002 + 0,00002 + 0,001 = 0,00204
D (x 2) = (-20) 2 0,3 + (-10) 2 0,1 + 10 2 0,1 + 20 2 0,3 = 240 +20 = 260
Im wartość wariancji jest bliższa zeru, tym mniejszy jest rozrzut zmiennej losowej w stosunku do wartości średniej.
Ilość nazywa się odchylenie standardowe. Tryb zmiennej losowej X dyskretny typ Md Nazywa się wartość zmiennej losowej, która ma największe prawdopodobieństwo.
Tryb zmiennej losowej X typ ciągły Md, jest liczbą rzeczywistą zdefiniowaną jako punkt maksimum gęstości rozkładu prawdopodobieństwa f(x).
Mediana zmiennej losowej X typ ciągły Mn jest liczbą rzeczywistą spełniającą równanie
Wartość oczekiwanaDyspersja ciągła zmienna losowa X, której możliwe wartości należą do całej osi Wółu, jest określona przez równość: ![]()
Cel usługi. Kalkulator online przeznaczony jest do rozwiązywania problemów, w których: gęstość dystrybucji f(x) lub dystrybuantę F(x) (patrz przykład). Zwykle w takich zadaniach musisz znaleźć oczekiwanie matematyczne, odchylenie standardowe, funkcje wykresu f(x) i F(x).
Instrukcje. Wybierz typ danych źródłowych: gęstość rozkładu f(x) lub funkcja rozkładu F(x).
Gęstość rozkładu f(x) jest dana: 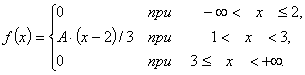
Dana jest funkcja rozkładu F(x): 
Ciągła zmienna losowa jest określona przez gęstość prawdopodobieństwa 
(Prawo dystrybucji Rayleigha - stosowane w radiotechnice). Znajdź M(x) , D(x) .
Nazywa się zmienną losową X ciągły
, jeśli jego funkcja dystrybucji F(X)=P(X< x) непрерывна и имеет производную.
Funkcja rozkładu ciągłej zmiennej losowej służy do obliczenia prawdopodobieństwa, że zmienna losowa znajdzie się w zadanym przedziale:
P(α< X < β)=F(β) - F(α)
Co więcej, dla ciągłej zmiennej losowej nie ma znaczenia, czy jej granice mieszczą się w tym przedziale, czy nie:
P(α< X < β) = P(α ≤ X < β) = P(α ≤ X ≤ β)
Gęstość dystrybucji
ciągła zmienna losowa nazywana jest funkcją
f(x)=F’(x) , pochodna funkcji rozkładu.
Właściwości gęstości rozkładu
1. Gęstość rozkładu zmiennej losowej jest nieujemna (f(x) ≥ 0) dla wszystkich wartości x.2. Warunek normalizacji:
Znaczenie geometryczne warunku normalizacji: pole pod krzywą gęstości rozkładu jest równe jedności.
3. Prawdopodobieństwo, że zmienna losowa X znajdzie się w przedziale od α do β, można obliczyć ze wzoru
Geometrycznie prawdopodobieństwo, że ciągła zmienna losowa X wpadnie w przedział (α, β) jest równe polu trapezu krzywoliniowego pod krzywą gęstości rozkładu opartą na tym przedziale.
4. Dystrybuantę wyraża się w gęstości w następujący sposób:
Wartość gęstości rozkładu w punkcie x nie jest równa prawdopodobieństwu przyjęcia tej wartości, dla ciągłej zmiennej losowej możemy mówić jedynie o prawdopodobieństwie wpadnięcia w dany przedział. Pozwalać )