Den næstvigtigste egenskab ved en stokastisk variabel efter den matematiske forventning er dens spredning, defineret som den gennemsnitlige kvadratiske afvigelse fra middelværdien:
Hvis den angives inden da, vil variansen VX være den forventede værdi. Dette er en karakteristik af "spredningen" af fordelingen af X.
Som et simpelt eksempel på beregning af varians, lad os sige, at vi lige har fået et tilbud, vi ikke kan afslå: nogen gav os to certifikater for det samme lotteri. Lottoarrangørerne sælger 100 lodder hver uge og deltager i en særskilt lodtrækning. Tegningen udvælger en af disse billetter gennem en ensartet tilfældig proces - hver billet har lige stor chance for at blive udvalgt - og ejeren af den heldige billet modtager hundrede millioner dollars. De resterende 99 lottokuponer vinder intet.
Vi kan bruge gaven på to måder: Køb enten to lodder i ét lotteri, eller én hver for at deltage i to forskellige lotterier. Hvilken strategi er bedre? Lad os prøve at analysere det. For at gøre dette, lad os angive med tilfældige variabler, der repræsenterer størrelsen af vores gevinster på den første og anden billet. Den forventede værdi i millioner er
og det samme gælder for Forventede værdier er additive, så vores gennemsnitlige samlede udbytte vil være
uanset den vedtagne strategi.
De to strategier ser dog forskellige ud. Lad os gå ud over de forventede værdier og studere den fulde sandsynlighedsfordeling

Hvis vi køber to lodder i et lotteri, så vil vores chancer for at vinde ingenting være 98% og 2% - chancerne for at vinde 100 mio. Hvis vi køber lodder til forskellige trækninger, vil tallene være som følger: 98,01% - chancen for ikke at vinde noget, hvilket er lidt højere end før; 0,01% - chance for at vinde 200 millioner, også lidt mere end før; og chancen for at vinde 100 millioner er nu 1,98%. Således er størrelsesfordelingen i det andet tilfælde noget mere spredt; den mellemste værdi, $100 millioner, er lidt mindre sandsynlig, mens ekstremerne er mere sandsynlige.
Det er dette koncept om spredningen af en tilfældig variabel, som spredningen er beregnet til at afspejle. Vi måler spredningen gennem kvadratet af afvigelsen af en stokastisk variabel fra dens matematiske forventning. I tilfælde 1 vil variansen således være
i tilfælde 2 er variansen
Som forventet er sidstnævnte værdi lidt større, da fordelingen i tilfælde 2 er noget mere spredt.
Når vi arbejder med varianser, er alt i kvadrat, så resultatet kan blive ret store tal. (Multiplikatoren er en trillion, det burde være imponerende
selv spillere, der er vant til store indsatser.) For at konvertere værdier til en mere meningsfuld original skala, tages kvadratroden af variansen ofte. Det resulterende tal kaldes standardafvigelsen og betegnes normalt med det græske bogstav a:
Standardafvigelserne for vores to lotteristrategier er . På nogle måder er den anden mulighed omkring $71.247 mere risikabel.
Hvordan hjælper varians med at vælge en strategi? Det er ikke klart. En strategi med højere varians er mere risikabel; men hvad er bedre for vores pengepung - risiko eller sikkert spil? Lad os få mulighed for at købe ikke to billetter, men alle hundrede. Så kunne vi garantere at vinde et lotteri (og variansen ville være nul); eller du kan spille i hundrede forskellige træk uden at få noget med en sandsynlighed, men have en chance for at vinde op til dollars, der ikke er nul. At vælge et af disse alternativer ligger uden for denne bogs rammer; alt, hvad vi kan gøre her, er at forklare, hvordan man laver beregningerne.
Faktisk er der en enklere måde at beregne varians på end direkte ved at bruge definition (8.13). (Der er al mulig grund til at mistænke en form for skjult matematik her; hvorfor skulle variansen i lotterieksemplerne ellers vise sig at være et heltal? Vi har
siden - konstant; derfor,
"Varians er middelværdien af kvadratet minus kvadratet af middelværdien."
For eksempel, i lotteriproblemet, viser gennemsnitsværdien sig at være eller Subtraktion (kvadraten af gennemsnittet) giver resultater, som vi allerede har opnået tidligere på en mere vanskelig måde.
Der er dog en endnu enklere formel, der er anvendelig, når vi beregner for uafhængige X og Y. Det har vi

da, som vi ved, for uafhængige stokastiske variabler derfor,

"Variansen af summen af uafhængige tilfældige variabler er lig med summen af deres varianser." Så for eksempel er variansen af det beløb, der kan vindes med en lotteriseddel lig med
Derfor vil spredningen af de samlede gevinster for to lotterisedler i to forskellige (uafhængige) lotterier være. Den tilsvarende spredningsværdi for uafhængige lotterisedler vil være
Variansen af summen af point kastet på to terninger kan opnås ved hjælp af den samme formel, da det er summen af to uafhængige stokastiske variable. Vi har
for den rigtige terning; derfor i tilfælde af et forskudt massecenter
derfor, hvis begge terninger har et forskudt massecenter. Bemærk, at i sidstnævnte tilfælde er variansen større, selvom den tager en middelværdi på 7 oftere end ved almindelige terninger. Hvis vores mål er at slå flere heldige syvere, så er varians ikke den bedste indikator for succes.
Okay, vi har fastlagt, hvordan man beregner varians. Men vi har endnu ikke givet svar på spørgsmålet om, hvorfor det er nødvendigt at beregne variansen. Alle gør det, men hvorfor? Hovedårsagen er Chebyshevs ulighed, som etablerer en vigtig egenskab ved spredning:
(Denne ulighed adskiller sig fra Chebyshev-ulighederne for summer, som vi stødte på i kapitel 2.) På et kvalitativt niveau angiver (8.17), at den stokastiske variabel X sjældent tager værdier langt fra sin middelværdi, hvis dens varians VX er lille. Bevis
ledelsen er ekstraordinær enkel. Virkelig,

division med fuldender beviset.
Hvis vi betegner den matematiske forventning med a og standardafvigelsen med a og erstatter i (8.17), så bliver betingelsen til derfor, får vi fra (8.17)
X vil således ligge inden for - gange standardafvigelsen af dens middelværdi undtagen i tilfælde, hvor sandsynligheden ikke overstiger Den stokastiske variabel vil ligge inden for 2a af mindst 75 % af forsøgene; spænder fra til - i hvert fald for 99%. Det er tilfælde af Chebyshevs ulighed.
Hvis du kaster et par terninger én gang, så vil den samlede sum af point i alle kast næsten altid være tæt på Årsagen til dette er følgende: variansen af uafhængige kast vil være Variansen i betyder standardafvigelsen for alting
Derfor får vi ud fra Chebyshevs ulighed, at summen af point vil ligge imellem
mindst for 99 % af alle kast med korrekte terninger. For eksempel vil resultatet af en million kast med en sandsynlighed på mere end 99% være mellem 6,976 millioner og 7,024 millioner.
Lad X generelt være enhver tilfældig variabel på sandsynlighedsrummet Π med en endelig matematisk forventning og en endelig standardafvigelse a. Derefter kan vi introducere sandsynlighedsrummet Pn i betragtning, hvis elementære hændelser er -sekvenser, hvor hver , og sandsynligheden er defineret som
Hvis vi nu definerer tilfældige variable ved formlen
derefter værdien
vil være summen af uafhængige stokastiske variable, som svarer til processen med at summere uafhængige realisationer af værdien X på P. Den matematiske forventning vil være lig med og standardafvigelsen - ; derfor den gennemsnitlige værdi af realisationer,
![]()
vil variere fra til i mindst 99 % af tidsperioden. Med andre ord, hvis du vælger en tilstrækkelig stor, vil den aritmetiske middelværdi af uafhængige test næsten altid være meget tæt på den forventede værdi (I sandsynlighedsteoretiske lærebøger er en endnu stærkere sætning bevist, kaldet den stærke lov om store tal; men for os den simple konsekvens af Chebyshevs ulighed, som vi lige har fjernet.)
Nogle gange kender vi ikke sandsynlighedsrummets karakteristika, men vi er nødt til at estimere den matematiske forventning til en stokastisk variabel X ved at bruge gentagne observationer af dens værdi. (Vi vil f.eks. gerne have den gennemsnitlige januar-middagstemperatur i San Francisco; eller vi vil måske vide den forventede levetid, som forsikringsagenter skal basere deres beregninger på.) Hvis vi har uafhængige empiriske observationer til rådighed, kan vi antage, at sande matematiske forventninger er omtrent lige store
![]()
Du kan også estimere variansen ved hjælp af formlen
Ser du på denne formel, tror du måske, at der er en typografisk fejl i den; Det ser ud til, at det skulle være der som i (8.19), eftersom den sande værdi af spredningen bestemmes i (8.15) gennem de forventede værdier. Men udskiftning her med giver os mulighed for at opnå et bedre skøn, da det følger af definition (8.20), at
![]()
Her er beviset:

(I denne beregning stoler vi på uafhængigheden af observationer, når vi erstatter med )
I praksis, for at vurdere resultaterne af et forsøg med en stokastisk variabel X, beregner man normalt det empiriske gennemsnit og den empiriske standardafvigelse og skriver derefter svaret på formen Her er f.eks. resultaterne af at kaste et par terninger, formentlig korrekt.
Tilfældige variable kan udover distributionslove også beskrives numeriske karakteristika .
Matematisk forventning M (x) af en stokastisk variabel kaldes dens middelværdi.
Den matematiske forventning til en diskret stokastisk variabel beregnes ved hjælp af formlen
Hvor – tilfældige variable værdier, s jeg- deres sandsynligheder.
Lad os overveje egenskaberne ved matematisk forventning:
1. Den matematiske forventning til en konstant er lig med konstanten selv
2. Hvis en stokastisk variabel ganges med et bestemt tal k, så vil den matematiske forventning blive ganget med det samme tal
M (kx) = kM (x)
3. Den matematiske forventning af summen af stokastiske variable er lig med summen af deres matematiske forventninger
M (x 1 + x 2 + … + x n) = M (x 1) + M (x 2) +…+ M (x n)
4. M (x 1 - x 2) = M (x 1) - M (x 2)
5. For uafhængige stokastiske variable x 1, x 2, … x n er den matematiske forventning af produktet lig med produktet af deres matematiske forventninger
M (x 1, x 2, ... x n) = M (x 1) M (x 2) ... M (x n)
6. M (x - M (x)) = M (x) - M (M (x)) = M (x) - M (x) = 0
Lad os beregne den matematiske forventning til den stokastiske variabel fra eksempel 11.
M(x) = = ![]() .
.
Eksempel 12. Lad de stokastiske variable x 1, x 2 specificeres i overensstemmelse hermed af fordelingslovene:
x 1 Tabel 2
x 2 Tabel 3
Lad os beregne M (x 1) og M (x 2)
M (x 1) = (- 0,1) 0,1 + (- 0,01) 0,2 + 0 0,4 + 0,01 0,2 + 0,1 0,1 = 0
M (x 2) = (- 20) 0,3 + (- 10) 0,1 + 0 0,2 + 10 0,1 + 20 0,3 = 0
De matematiske forventninger til begge stokastiske variable er de samme - de er lig med nul. Imidlertid er arten af deres fordeling anderledes. Hvis værdierne af x 1 afviger lidt fra deres matematiske forventning, så afviger værdierne af x 2 i vid udstrækning fra deres matematiske forventninger, og sandsynligheden for sådanne afvigelser er ikke små. Disse eksempler viser, at det er umuligt ud fra gennemsnitsværdien at afgøre, hvilke afvigelser derfra forekommer, både mindre og større. Så med samme gennemsnitlige årlige nedbør i to områder kan man ikke sige, at disse områder er lige gunstige for landbrugsarbejde. På samme måde er det ud fra gennemsnitslønindikatoren ikke muligt at bedømme andelen af højt- og lavtlønnede. Derfor introduceres en numerisk karakteristik - spredning D(x) , som karakteriserer graden af afvigelse af en stokastisk variabel fra dens gennemsnitlige værdi:
D(x) = M(x-M(x))2. (2)
Dispersion er den matematiske forventning af den kvadrerede afvigelse af en stokastisk variabel fra den matematiske forventning. For en diskret stokastisk variabel beregnes variansen ved hjælp af formlen:
D(x)= ![]() =
= ![]() (3)
(3)
Af definitionen af dispersion følger det, at D (x) 0.
Dispersionsegenskaber:
1. Variansen af konstanten er nul
2. Hvis en stokastisk variabel ganges med et bestemt tal k, så vil variansen blive ganget med kvadratet af dette tal
D (kx) = k 2 D (x)
3. D (x) = M (x 2) – M 2 (x)
4. For parvis uafhængige stokastiske variable x 1 , x 2 , … x n er variansen af summen lig med summen af varianserne.
D (x 1 + x 2 + … + x n) = D (x 1) + D (x 2) +…+ D (x n)
Lad os beregne variansen for den tilfældige variabel fra eksempel 11.
Matematisk forventning M (x) = 1. Derfor har vi ifølge formel (3):
D (x) = (0 – 1) 2 1/4 + (1 – 1) 2 1/2 + (2 – 1) 2 1/4 =1 1/4 +1 1/4= 1/2
Bemærk, at det er lettere at beregne varians, hvis du bruger egenskab 3:
D (x) = M (x 2) – M 2 (x).
Lad os beregne varianserne for de tilfældige variable x 1 , x 2 fra eksempel 12 ved hjælp af denne formel. De matematiske forventninger til begge stokastiske variable er nul.
D (x 1) = 0,01 0,1 + 0,0001 0,2 + 0,0001 0,2 + 0,01 0,1 = 0,001 + 0,00002 + 0,00002 + 0,001 = 0,00204
D (x 2) = (-20) 2 0,3 + (-10) 2 0,1 + 10 2 0,1 + 20 2 0,3 = 240 +20 = 260
Jo tættere variansværdien er på nul, jo mindre er spredningen af den stokastiske variabel i forhold til middelværdien.
Mængden kaldes standardafvigelse. Tilfældig variabel tilstand x diskret type Md Værdien af en tilfældig variabel, der har størst sandsynlighed kaldes.
Tilfældig variabel tilstand x kontinuerlig type Md, er et reelt tal defineret som maksimumspunktet for sandsynlighedsfordelingstætheden f(x).
Medianen af en tilfældig variabel x kontinuerlig type Mn er et reelt tal, der opfylder ligningen
Forventet værdiSpredning kontinuerlig tilfældig variabel X, hvis mulige værdier hører til hele Ox-aksen, bestemmes af ligheden: ![]()
Formålet med tjenesten. Online-beregneren er designet til at løse problemer, hvor enten fordelingstæthed f(x) eller fordelingsfunktion F(x) (se eksempel). Normalt i sådanne opgaver skal du finde matematisk forventning, standardafvigelse, plotfunktioner f(x) og F(x).
Instruktioner. Vælg typen af kildedata: fordelingstæthed f(x) eller fordelingsfunktion F(x).
Fordelingstætheden f(x) er givet: 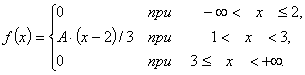
Fordelingsfunktionen F(x) er givet: 
En kontinuert stokastisk variabel er specificeret ved en sandsynlighedstæthed 
(Rayleigh distributionslov - bruges i radioteknik). Find M(x), D(x) .
Den stokastiske variabel X kaldes sammenhængende
, hvis dens fordelingsfunktion F(X)=P(X< x) непрерывна и имеет производную.
Fordelingsfunktionen af en kontinuert stokastisk variabel bruges til at beregne sandsynligheden for, at en stokastisk variabel falder ind i et givet interval:
P(α< X < β)=F(β) - F(α)
For en kontinuert stokastisk variabel er det desuden ligegyldigt, om dens grænser er inkluderet i dette interval eller ej:
P(α< X < β) = P(α ≤ X < β) = P(α ≤ X ≤ β)
Fordelingstæthed
en kontinuert stokastisk variabel kaldes en funktion
f(x)=F’(x) , afledt af fordelingsfunktionen.
Egenskaber for distributionstæthed
1. Fordelingstætheden af den stokastiske variabel er ikke-negativ (f(x) ≥ 0) for alle værdier af x.2. Normaliseringstilstand:
Den geometriske betydning af normaliseringsbetingelsen: arealet under fordelingsdensitetskurven er lig med enhed.
3. Sandsynligheden for, at en stokastisk variabel X falder ind i intervallet fra α til β kan beregnes ved hjælp af formlen
Geometrisk er sandsynligheden for, at en kontinuert stokastisk variabel X falder ind i intervallet (α, β) lig med arealet af den krumlinede trapez under fordelingsdensitetskurven baseret på dette interval.
4. Fordelingsfunktionen udtrykkes i form af tæthed som følger:
Værdien af fordelingstætheden ved punkt x er ikke lig med sandsynligheden for at acceptere denne værdi; for en kontinuert stokastisk variabel kan vi kun tale om sandsynligheden for at falde ind i et givet interval. lad)