సగటు విలువలు గణాంకాలలో విస్తృతంగా ఉపయోగించబడతాయి. సగటు విలువ- ఇది అధ్యయనం చేయబడిన దృగ్విషయం యొక్క సాధారణ పరిస్థితులు మరియు నమూనాల ప్రభావాలను ప్రతిబింబించే సాధారణీకరణ సూచిక.
సగటు- ఇది సాధారణ సాధారణీకరణ పద్ధతుల్లో ఒకటి. సగటు యొక్క సారాంశం యొక్క సరైన అవగాహన మార్కెట్ ఆర్థిక వ్యవస్థలో దాని ప్రత్యేక ప్రాముఖ్యతను నిర్ణయిస్తుంది, సగటు, వ్యక్తిగత మరియు యాదృచ్ఛికంగా, ఆర్థిక అభివృద్ధి యొక్క నమూనాల ధోరణిని గుర్తించడానికి సాధారణ మరియు అవసరమైన వాటిని గుర్తించడానికి అనుమతిస్తుంది. సగటు విలువలు వర్ణించబడతాయి గుణాత్మక సూచికలువాణిజ్య కార్యకలాపాలు: పంపిణీ ఖర్చులు, లాభం, లాభదాయకత మొదలైనవి.
గణాంక సగటులు సరిగ్గా నిర్వహించబడిన సామూహిక పరిశీలన (నిరంతర మరియు ఎంపిక) నుండి డేటా ఆధారంగా లెక్కించబడతాయి. అయినప్పటికీ, గుణాత్మకంగా సజాతీయ జనాభా (సామూహిక దృగ్విషయాలు) కోసం ద్రవ్యరాశి డేటా నుండి లెక్కించినట్లయితే గణాంక సగటు లక్ష్యం మరియు విలక్షణమైనది. ఉదాహరణకు, మీరు సహకార సంస్థలు మరియు ప్రభుత్వ యాజమాన్యంలోని సంస్థలలో సగటు వేతనాన్ని లెక్కించి, మొత్తం జనాభాకు ఫలితాన్ని విస్తరింపజేస్తే, సగటు కల్పితం, ఎందుకంటే ఇది భిన్నమైన జనాభా కోసం లెక్కించబడుతుంది మరియు అటువంటి సగటు మొత్తం అర్థాన్ని కోల్పోతుంది.
సగటు సహాయంతో, వ్యక్తిగత పరిశీలన యూనిట్లలో ఒక కారణం లేదా మరొక కారణంగా ఉత్పన్నమయ్యే లక్షణం యొక్క విలువలో తేడాలు సున్నితంగా ఉంటాయి. అదే సమయంలో, జనాభా యొక్క సాధారణ ఆస్తిని సాధారణీకరించడం, సగటు కొన్ని సూచికలను (తక్కువగా) అస్పష్టం చేస్తుంది మరియు ఇతరులను ఎక్కువగా అంచనా వేస్తుంది.
ఉదాహరణకు, విక్రయదారుని సగటు ఉత్పాదకత అనేక కారణాలపై ఆధారపడి ఉంటుంది: అర్హతలు, సేవ యొక్క పొడవు, వయస్సు, సేవ యొక్క రూపం, ఆరోగ్యం మొదలైనవి.
సగటు ఉత్పత్తి మొత్తం జనాభా యొక్క సాధారణ ఆస్తిని ప్రతిబింబిస్తుంది.
సగటు విలువ అధ్యయనం చేయబడిన లక్షణం యొక్క విలువల ప్రతిబింబం, కాబట్టి, ఇది ఈ లక్షణం వలె అదే పరిమాణంలో కొలుస్తారు.
ప్రతి సగటు విలువ ఏదైనా ఒక లక్షణం ప్రకారం అధ్యయనంలో ఉన్న జనాభాను వర్గీకరిస్తుంది. మొత్తంగా అనేక ముఖ్యమైన లక్షణాల ఆధారంగా అధ్యయనంలో ఉన్న జనాభాపై పూర్తి మరియు సమగ్రమైన అవగాహనను పొందడానికి, వివిధ కోణాల నుండి దృగ్విషయాన్ని వివరించగల సగటు విలువల వ్యవస్థను కలిగి ఉండటం అవసరం.
సామాజిక దృగ్విషయం యొక్క గణాంక విశ్లేషణలో సగటు విలువల యొక్క శాస్త్రీయ ఉపయోగం కోసం అత్యంత ముఖ్యమైన షరతు జనాభా సజాతీయత, దీని కోసం సగటు లెక్కించబడుతుంది. రూపం మరియు గణన సాంకేతికతలో ఒకేలా ఉంటుంది, కొన్ని పరిస్థితులలో (వైవిధ్య జనాభా కోసం) సగటు కల్పితం అయితే, మరికొన్నింటిలో (సజాతీయ జనాభా కోసం) ఇది వాస్తవికతకు అనుగుణంగా ఉంటుంది. జనాభా యొక్క గుణాత్మక సజాతీయత దృగ్విషయం యొక్క సారాంశం యొక్క సమగ్ర సైద్ధాంతిక విశ్లేషణ ఆధారంగా నిర్ణయించబడుతుంది.
సాధారణ లేదా బరువున్న రూపంలో వివిధ రకాల సగటులు ఉన్నాయి:
- అంకగణిత సగటు
- రేఖాగణిత సగటు
- హార్మోనిక్ సగటు
- రూట్ అంటే చతురస్రం
- సగటు కాలక్రమానుసారం
- నిర్మాణాత్మక సాధనాలు (మోడ్, మధ్యస్థ)
సగటు విలువలను నిర్ణయించడానికి, క్రింది సూత్రాలు ఉపయోగించబడతాయి:
(క్లిక్ చేయగల)
మెజారిటీ పాలనసగటు: ఎక్కువ ఘాతాంకం m, ఎక్కువ సగటు విలువ.
అంకగణిత సగటు క్రింది లక్షణాలను కలిగి ఉంది:
- దాని సగటు విలువ నుండి ఒక లక్షణం యొక్క వ్యక్తిగత విలువల వ్యత్యాసాల మొత్తం సున్నాకి సమానం.
- లక్షణం యొక్క అన్ని విలువలు ఉంటే ( X) అదే సంఖ్యలో పెంచండి (తగ్గుతుంది). కె సార్లు, అప్పుడు సగటు పెరుగుతుంది (తగ్గుతుంది). కె ఒకసారి.
- లక్షణం యొక్క అన్ని విలువలు ఉంటే (x) అదే సంఖ్యలో పెంచండి (తగ్గుతుంది).ఎ, అప్పుడు సగటు అదే సంఖ్యలో పెరుగుతుంది (తగ్గుతుంది).ఎ.
- బరువుల యొక్క అన్ని విలువలు ఉంటే ( f) అదే సంఖ్యలో సార్లు పెంచండి లేదా తగ్గించండి, అప్పుడు సగటు మారదు.
- అంకగణిత సగటు నుండి ఒక లక్షణం యొక్క వ్యక్తిగత విలువల యొక్క స్క్వేర్డ్ విచలనాల మొత్తం ఇతర సంఖ్యల కంటే తక్కువగా ఉంటుంది. ఒక లక్షణం యొక్క వ్యక్తిగత విలువలను సగటు విలువతో భర్తీ చేసేటప్పుడు, అసలు విలువల యొక్క స్థిరమైన చతురస్రాల మొత్తాన్ని నిర్వహించడం అవసరం అయితే, సగటు చతురస్రాకార సగటు విలువ అవుతుంది.
నిర్దిష్ట లక్షణాల ఏకకాల ఉపయోగం అంకగణిత సగటు గణనను సులభతరం చేస్తుంది:మీరు అన్ని లక్షణ విలువల నుండి స్థిరమైన విలువను తీసివేయవచ్చుA,సాధారణ కారకం ద్వారా తేడాలను తగ్గించండికె, మరియు అన్ని బరువులు fఅదే సంఖ్యతో విభజించి, మార్చబడిన డేటాను ఉపయోగించి, సగటును లెక్కించండి. అప్పుడు, ఫలితంగా సగటు విలువ గుణిస్తేకె, మరియు ఉత్పత్తికి జోడించండిఎ, అప్పుడు మేము సూత్రాన్ని ఉపయోగించి అంకగణిత సగటు యొక్క కావలసిన విలువను పొందుతాము:

ఫలితంగా రూపాంతరం చెందిన సగటు అంటారు మొదటి ఆర్డర్ క్షణం, మరియు సగటును లెక్కించడానికి పై పద్ధతి క్షణాల మార్గం, లేదా షరతులతో కూడిన సున్నా నుండి లెక్కింపు.
గ్రూపింగ్ సమయంలో, సగటున ఉన్న లక్షణం యొక్క విలువలు విరామాలలో పేర్కొనబడినట్లయితే, అంకగణిత సగటును లెక్కించేటప్పుడు, ఈ విరామాల మధ్య బిందువులు సమూహాలలో లక్షణం యొక్క విలువగా తీసుకోబడతాయి, అనగా అవి వాటిపై ఆధారపడి ఉంటాయి లక్షణ విలువల వ్యవధిలో జనాభా యూనిట్ల ఏకరీతి పంపిణీ యొక్క ఊహ. మొదటి మరియు చివరి సమూహాలలో బహిరంగ విరామాల కోసం, ఏదైనా ఉంటే, లక్షణం మరియు జనాభా యొక్క లక్షణాల సారాంశం ఆధారంగా లక్షణం యొక్క విలువలు నైపుణ్యంగా నిర్ణయించబడాలి. నిపుణుల అంచనాకు అవకాశం లేనప్పుడు, బహిరంగ విరామాలలో ఒక లక్షణం యొక్క విలువ, బహిరంగ విరామం యొక్క తప్పిపోయిన సరిహద్దును కనుగొనడానికి, పరిధి (విరామం ముగింపు మరియు ప్రారంభం యొక్క విలువల మధ్య వ్యత్యాసం) ప్రక్కనే విరామం ("పొరుగు" సూత్రం) ఉపయోగించబడుతుంది. మరో మాటలో చెప్పాలంటే, బహిరంగ విరామం యొక్క వెడల్పు (దశ) ప్రక్కనే ఉన్న విరామం పరిమాణం ద్వారా నిర్ణయించబడుతుంది.
సగటుల గురించి మాట్లాడటం ప్రారంభించినప్పుడు, వారు పాఠశాల నుండి పట్టభద్రులయ్యారు మరియు విద్యా సంస్థలో ఎలా ప్రవేశించారో ప్రజలు చాలా తరచుగా గుర్తుంచుకుంటారు. అప్పుడు సర్టిఫికేట్ ఆధారంగా సగటు స్కోరు లెక్కించబడుతుంది: అన్ని గ్రేడ్లు (మంచివి మరియు అంత మంచివి కావు) జోడించబడ్డాయి, ఫలితంగా మొత్తం వారి సంఖ్యతో విభజించబడింది. ఈ విధంగా సరళమైన సగటు రకం లెక్కించబడుతుంది, దీనిని సాధారణ అంకగణిత సగటు అంటారు. ఆచరణలో, గణాంకాలలో వివిధ రకాల సగటులు ఉపయోగించబడతాయి: అంకగణితం, హార్మోనిక్, రేఖాగణితం, చతుర్భుజం, నిర్మాణ సగటులు. డేటా యొక్క స్వభావం మరియు అధ్యయనం యొక్క ప్రయోజనాలపై ఆధారపడి ఒకటి లేదా మరొక రకం ఉపయోగించబడుతుంది.
సగటు విలువఅనేది అత్యంత సాధారణ గణాంక సూచిక, దీని సహాయంతో సారూప్య దృగ్విషయాల సమితి యొక్క సాధారణ లక్షణం వివిధ లక్షణాలలో ఒకదాని ప్రకారం ఇవ్వబడుతుంది. ఇది జనాభా యూనిట్కు ఒక లక్షణం స్థాయిని చూపుతుంది. సగటు విలువల సహాయంతో, వివిధ జనాభా వివిధ లక్షణాల ప్రకారం పోల్చబడుతుంది మరియు సామాజిక జీవితం యొక్క దృగ్విషయం మరియు ప్రక్రియల అభివృద్ధి యొక్క నమూనాలు అధ్యయనం చేయబడతాయి.
గణాంకాలలో, రెండు తరగతుల సగటులు ఉపయోగించబడతాయి: శక్తి (విశ్లేషణాత్మక) మరియు నిర్మాణాత్మకం. వైవిధ్య శ్రేణి యొక్క నిర్మాణాన్ని వర్గీకరించడానికి రెండోవి ఉపయోగించబడతాయి మరియు అధ్యాయంలో మరింత చర్చించబడతాయి. 8.
శక్తి సగటుల సమూహంలో అంకగణితం, హార్మోనిక్, రేఖాగణిత మరియు చతుర్భుజ సగటులు ఉంటాయి. వారి గణన కోసం వ్యక్తిగత సూత్రాలు అన్ని శక్తి సగటులకు సాధారణ రూపానికి తగ్గించబడతాయి, అవి
ఇక్కడ m అనేది శక్తి సగటు యొక్క ఘాతాంకం: m = 1తో మేము అంకగణిత సగటును లెక్కించడానికి సూత్రాన్ని పొందుతాము, m = 0 తో - రేఖాగణిత సగటు, m = -1 - హార్మోనిక్ సగటు, m = 2 తో - చతుర్భుజ సగటు ;
x i - ఎంపికలు (లక్షణం తీసుకునే విలువలు);
f i - ఫ్రీక్వెన్సీలు.
గణాంక విశ్లేషణలో శక్తి సగటులను ఉపయోగించగల ప్రధాన పరిస్థితి జనాభా యొక్క సజాతీయత, ఇది వారి పరిమాణాత్మక విలువలో (సాహిత్యంలో వాటిని క్రమరహిత పరిశీలనలు అని పిలుస్తారు) తీవ్రంగా విభేదించే ప్రారంభ డేటాను కలిగి ఉండకూడదు.
కింది ఉదాహరణతో ఈ పరిస్థితి యొక్క ప్రాముఖ్యతను ప్రదర్శిస్తాము.
ఉదాహరణ 6.1. ఒక చిన్న సంస్థ యొక్క ఉద్యోగుల సగటు జీతం లెక్కిద్దాం.
| నం. | జీతం, రుద్దు. | నం. | జీతం, రుద్దు. |
|---|---|---|---|
| 1 | 5 950 | 11 | 7 000 |
| 2 | 6 790 | 12 | 5 950 |
| 3 | 6 790 | 13 | 6 790 |
| 4 | 5 950 | 14 | 5 950 |
| 5 | 7 000 | 5 | 6 790 |
| 6 | 6 790 | 16 | 7 000 |
| 7 | 5 950 | 17 | 6 790 |
| 8 | 7 000 | 18 | 7 000 |
| 9 | 6 790 | 19 | 7 000 |
| 10 | 6 790 | 20 | 5 950 |
సగటు వేతనాన్ని లెక్కించడానికి, సంస్థలోని ఉద్యోగులందరికీ (అనగా, వేతన నిధిని కనుగొనండి) మరియు ఉద్యోగుల సంఖ్యతో విభజించాల్సిన వేతనాలను సంగ్రహించడం అవసరం:
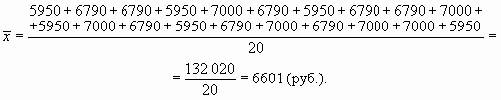
ఇప్పుడు మన మొత్తానికి కేవలం ఒక వ్యక్తిని (ఈ ఎంటర్ప్రైజ్ డైరెక్టర్) జోడిద్దాం, కానీ జీతం 50,000 రూబిళ్లు. ఈ సందర్భంలో, లెక్కించిన సగటు పూర్తిగా భిన్నంగా ఉంటుంది:
మేము చూడగలిగినట్లుగా, ఇది 7,000 రూబిళ్లు, మొదలైనవి మించిపోయింది. ఇది ఒకే ఒక్క పరిశీలన మినహా అన్ని లక్షణ విలువల కంటే ఎక్కువ.
అటువంటి సందర్భాలు ఆచరణలో జరగకుండా మరియు సగటు దాని అర్ధాన్ని కోల్పోకుండా చూసుకోవడానికి (ఉదాహరణకు 6.1 ఇది ఇకపై జనాభా యొక్క సాధారణీకరించే లక్షణం యొక్క పాత్రను పోషించదు), సగటు, క్రమరహిత, పదునుగా లెక్కించేటప్పుడు స్టాండింగ్ అవుట్ పరిశీలనలను విశ్లేషణ నుండి మినహాయించాలి మరియు అంశాలు జనాభాను సజాతీయంగా మార్చాలి, లేదా జనాభాను సజాతీయ సమూహాలుగా విభజించి, ప్రతి సమూహానికి సగటు విలువలను లెక్కించి మొత్తం సగటును కాకుండా సమూహ సగటు విలువలను విశ్లేషించాలి.
6.1 అంకగణిత సగటు మరియు దాని లక్షణాలు
అంకగణిత సగటు సాధారణ లేదా వెయిటెడ్ విలువగా గణించబడుతుంది.
పట్టిక ఉదాహరణ 6.1లోని డేటా ప్రకారం సగటు జీతం లెక్కించేటప్పుడు, మేము లక్షణం యొక్క అన్ని విలువలను జోడించాము మరియు వాటి సంఖ్యతో విభజించాము. మేము మా లెక్కల పురోగతిని సాధారణ అంకగణిత సగటు సూత్రం రూపంలో వ్రాస్తాము
ఇక్కడ x i - ఎంపికలు (లక్షణం యొక్క వ్యక్తిగత విలువలు);
n అనేది మొత్తంలో ఉన్న యూనిట్ల సంఖ్య.
ఉదాహరణ 6.2. ఇప్పుడు పట్టిక నుండి మన డేటాను ఉదాహరణ 6.1 మొదలైన వాటిలో సమూహపరుద్దాం. వేతన స్థాయి ద్వారా కార్మికుల పంపిణీ యొక్క వివిక్త వైవిధ్య శ్రేణిని నిర్మిస్తాము. సమూహ ఫలితాలు పట్టికలో ప్రదర్శించబడ్డాయి.
సగటు వేతన స్థాయిని మరింత కాంపాక్ట్ రూపంలో లెక్కించడానికి వ్యక్తీకరణను వ్రాస్దాం:
ఉదాహరణ 6.2లో, బరువున్న అంకగణిత సగటు సూత్రం వర్తించబడింది
ఇక్కడ f i అనేది జనాభా యూనిట్లలో లక్షణం x i y యొక్క విలువ ఎన్ని రెట్లు సంభవిస్తుందో చూపే ఫ్రీక్వెన్సీలు.
దిగువ చూపిన విధంగా (టేబుల్ 6.3) పట్టికలో అంకగణిత సగటును లెక్కించడం సౌకర్యంగా ఉంటుంది:
| ప్రారంభ డేటా | అంచనా సూచిక | |
| జీతం, రుద్దు. | ఉద్యోగుల సంఖ్య, ప్రజలు | వేతన నిధి, రుద్దు. |
| x i | f i | x i f i |
| 5 950 | 6 | 35 760 |
| 6 790 | 8 | 54 320 |
| 7 000 | 6 | 42 000 |
| మొత్తం | 20 | 132 080 |
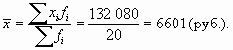
డేటా సమూహం చేయబడని లేదా సమూహం చేయబడని సందర్భాలలో సాధారణ అంకగణిత సగటు ఉపయోగించబడుతుందని గమనించాలి, అయితే అన్ని పౌనఃపున్యాలు సమానంగా ఉంటాయి.
తరచుగా, పరిశీలన ఫలితాలు విరామం పంపిణీ శ్రేణి రూపంలో ప్రదర్శించబడతాయి (ఉదాహరణ 6.4లో పట్టికను చూడండి). అప్పుడు, సగటును లెక్కించేటప్పుడు, విరామాల మధ్య బిందువులు x iగా తీసుకోబడతాయి. మొదటి మరియు చివరి విరామాలు తెరిచి ఉంటే (సరిహద్దులలో ఒకటి లేదు), అప్పుడు అవి షరతులతో “మూసివేయబడతాయి”, ప్రక్కనే ఉన్న విరామం యొక్క విలువను ఈ విరామం యొక్క విలువగా తీసుకుంటాయి. మొదటిది రెండవ విలువ ఆధారంగా మూసివేయబడుతుంది మరియు చివరిది - చివరి విలువ ప్రకారం.
ఉదాహరణ 6.3. జనాభా సమూహాలలో ఒకదాని యొక్క నమూనా సర్వే ఫలితాల ఆధారంగా, మేము సగటు తలసరి ద్రవ్య ఆదాయాన్ని గణిస్తాము.
పై పట్టికలో, మొదటి విరామం మధ్యలో 500. నిజానికి, రెండవ విరామం విలువ 1000 (2000-1000); అప్పుడు మొదటి యొక్క తక్కువ పరిమితి 0 (1000-1000), మరియు దాని మధ్య 500. మేము చివరి విరామంతో అదే చేస్తాము. మేము దాని మధ్యస్థంగా 25,000 తీసుకుంటాము: చివరి విరామం యొక్క విలువ 10,000 (20,000-10,000), అప్పుడు దాని ఎగువ పరిమితి 30,000 (20,000 + 10,000), మరియు మధ్యలో, తదనుగుణంగా, 25,000.
| సగటు తలసరి నగదు ఆదాయం, రుద్దు. ఒక నెలకి | మొత్తం జనాభా, % f i | విరామాల మధ్య బిందువులు x i | x i f i |
|---|---|---|---|
| 1,000 వరకు | 4,1 | 500 | 2 050 |
| 1 000-2 000 | 8,6 | 1 500 | 12 900 |
| 2 000-4 000 | 12,9 | 3 000 | 38 700 |
| 4 000-6 000 | 13,0 | 5 000 | 65 000 |
| 6 000-8 000 | 10,5 | 7 000 | 73 500 |
| 8 000-10 000 | 27,8 | 9 000 | 250 200 |
| 10 000-20 000 | 12,7 | 15 000 | 190 500 |
| 20,000 మరియు అంతకంటే ఎక్కువ | 10,4 | 25 000 | 260 000 |
| మొత్తం | 100,0 | - | 892 850 |
అప్పుడు సగటు తలసరి నెలవారీ ఆదాయం ఉంటుంది
ఈ అధ్యాయం సగటు విలువల ప్రయోజనాన్ని వివరిస్తుంది, వాటి ప్రధాన రకాలు మరియు రూపాలు మరియు గణన పద్ధతులను చర్చిస్తుంది. సమర్పించిన పదార్థాన్ని అధ్యయనం చేసేటప్పుడు, సగటు విలువలను నిర్మించడానికి అవసరమైన అవసరాలను అర్థం చేసుకోవడం అవసరం, ఎందుకంటే వాటితో సమ్మతి ఈ విలువలను సజాతీయ యూనిట్ల సమితి కోసం లక్షణ విలువల యొక్క విలక్షణమైన లక్షణాలుగా ఉపయోగించడానికి మిమ్మల్ని అనుమతిస్తుంది.
సగటుల రూపాలు మరియు రకాలు
సగటు విలువ లక్షణం విలువల స్థాయికి సాధారణీకరించబడిన లక్షణం, ఇది జనాభా యొక్క యూనిట్కు పొందబడుతుంది. సాపేక్ష విలువ వలె కాకుండా, సూచికల నిష్పత్తి యొక్క కొలత, సగటు విలువ జనాభా యొక్క యూనిట్కు లక్షణం యొక్క కొలతగా పనిచేస్తుంది.
సగటు విలువ యొక్క అతి ముఖ్యమైన ఆస్తి ఏమిటంటే, ఇది అధ్యయనంలో ఉన్న జనాభాలోని అన్ని యూనిట్లకు సాధారణమైనదిగా ప్రతిబింబిస్తుంది.
జనాభా యొక్క వ్యక్తిగత యూనిట్ల లక్షణాల విలువలు అనేక కారకాల ప్రభావంతో ఒక దిశలో లేదా మరొక దిశలో హెచ్చుతగ్గులకు గురవుతాయి, వాటిలో కొన్ని ముఖ్యమైనవి లేదా యాదృచ్ఛికంగా ఉండవచ్చు. ఉదాహరణకు, బ్యాంకు రుణాలపై వడ్డీ రేట్లు అన్ని క్రెడిట్ సంస్థల ప్రారంభ కారకాల ద్వారా నిర్ణయించబడతాయి (రిజర్వ్ అవసరాల స్థాయి మరియు సెంట్రల్ బ్యాంక్ వాణిజ్య బ్యాంకులకు అందించే రుణాలపై బేస్ వడ్డీ రేటు మొదలైనవి), అలాగే లక్షణాల ద్వారా ప్రతి నిర్దిష్ట లావాదేవీ, ఇచ్చిన రుణంలో అంతర్లీనంగా ఉన్న రిస్క్, దాని పరిమాణం మరియు తిరిగి చెల్లించే వ్యవధి, రుణాన్ని ప్రాసెస్ చేయడం మరియు దాని చెల్లింపును పర్యవేక్షించడం మొదలైన వాటిపై ఆధారపడి ఉంటుంది.
సగటు విలువ ఒక లక్షణం యొక్క వ్యక్తిగత విలువలను సంగ్రహిస్తుంది మరియు స్థలం మరియు సమయం యొక్క నిర్దిష్ట పరిస్థితులలో ఇచ్చిన జనాభా యొక్క అత్యంత లక్షణం అయిన సాధారణ పరిస్థితుల ప్రభావాన్ని ప్రతిబింబిస్తుంది. యాదృచ్ఛిక కారకాల చర్య వల్ల కలిగే జనాభా యొక్క వ్యక్తిగత యూనిట్ల లక్షణ విలువల విచలనాలను రద్దు చేస్తుంది మరియు ప్రధాన కారకాల చర్య వల్ల కలిగే మార్పులను పరిగణనలోకి తీసుకుంటుంది అనే వాస్తవం సగటు యొక్క సారాంశం. గుణాత్మకంగా సజాతీయ జనాభా నుండి లెక్కించబడినప్పుడు సగటు విలువ యూనిట్ల యొక్క ఇచ్చిన జనాభాలో లక్షణం యొక్క సాధారణ స్థాయిని ప్రతిబింబిస్తుంది. ఈ విషయంలో, సమూహ పద్ధతితో కలిపి సగటు పద్ధతి ఉపయోగించబడుతుంది.
మొత్తం జనాభాను వర్ణించే సగటు విలువలను అంటారు సాధారణ, మరియు సగటులు, సమూహం లేదా ఉప సమూహం యొక్క లక్షణాలను ప్రతిబింబిస్తాయి, - సమూహం.
సాధారణ మరియు సమూహ సగటుల కలయిక సమయం మరియు స్థలం అంతటా పోలికలను అనుమతిస్తుంది మరియు గణాంక విశ్లేషణ యొక్క సరిహద్దులను గణనీయంగా విస్తరిస్తుంది. ఉదాహరణకు, 2002 జనాభా లెక్కల ఫలితాలను సంగ్రహించినప్పుడు, చాలా యూరోపియన్ దేశాల మాదిరిగానే రష్యా కూడా వృద్ధాప్య జనాభాతో వర్గీకరించబడిందని కనుగొనబడింది. 1989 జనాభా లెక్కలతో పోలిస్తే, దేశంలోని నివాసితుల సగటు వయస్సు మూడు సంవత్సరాలు పెరిగింది మరియు 37.7 సంవత్సరాలు, పురుషులు - 35.2 సంవత్సరాలు, మహిళలు - 40.0 సంవత్సరాలు (1989 డేటా ప్రకారం, ఈ గణాంకాలు వరుసగా 34.7, 31,). .9 మరియు 37.2 సంవత్సరాలు). రోస్స్టాట్ ప్రకారం, పురుషులకు 2011 లో పుట్టినప్పుడు ఆయుర్దాయం 63 సంవత్సరాలు, మహిళలకు - 75.6 సంవత్సరాలు.
ప్రతి సగటు ఒక లక్షణం ప్రకారం అధ్యయనం చేయబడిన జనాభా యొక్క విశిష్టతను ప్రతిబింబిస్తుంది. ఆచరణాత్మక నిర్ణయాలు తీసుకోవడానికి, ఒక నియమం వలె, అనేక లక్షణాల ప్రకారం జనాభాను వర్గీకరించడం అవసరం. ఈ సందర్భంలో, సగటు వ్యవస్థ ఉపయోగించబడుతుంది.
ఉదాహరణకు, బ్యాంకింగ్ కార్యకలాపాలలో ఆమోదయోగ్యమైన రిస్క్ వద్ద కార్యకలాపాల లాభదాయకత యొక్క అవసరమైన స్థాయిని సాధించడానికి, డిపాజిట్లు మరియు ఇతర ఆర్థిక సాధనాలపై సగటు వడ్డీ రేట్లను పరిగణనలోకి తీసుకొని జారీ చేయబడిన రుణాలపై సగటు వడ్డీ రేట్లు సెట్ చేయబడతాయి.
సగటు విలువను లెక్కించే రూపం, రకం మరియు పద్ధతి అధ్యయనం యొక్క పేర్కొన్న ప్రయోజనం, అధ్యయనం చేయబడిన లక్షణాల రకం మరియు సంబంధం, అలాగే ప్రారంభ డేటా యొక్క స్వభావంపై ఆధారపడి ఉంటుంది. సగటులు రెండు ప్రధాన వర్గాలలోకి వస్తాయి:
- 1) శక్తి సగటులు;
- 2) నిర్మాణ సగటులు.
సగటు సూత్రం వర్తించే సగటు శక్తి యొక్క విలువ ద్వారా నిర్ణయించబడుతుంది. పెరుగుతున్న ఘాతాంకంతో కె సగటు విలువ తదనుగుణంగా పెరుగుతుంది.
చాలా సందర్భాలలో, డేటా కొంత కేంద్ర బిందువు చుట్టూ కేంద్రీకృతమై ఉంటుంది. అందువల్ల, ఏదైనా డేటా సమితిని వివరించడానికి, సగటు విలువను సూచించడానికి సరిపోతుంది. పంపిణీ యొక్క సగటు విలువను అంచనా వేయడానికి ఉపయోగించే మూడు సంఖ్యా లక్షణాలను వరుసగా పరిశీలిద్దాం: అంకగణిత సగటు, మధ్యస్థ మరియు మోడ్.
సగటు
అంకగణిత సగటు (తరచుగా సగటు అని పిలుస్తారు) అనేది పంపిణీ యొక్క సగటు యొక్క అత్యంత సాధారణ అంచనా. ఇది గమనించిన అన్ని సంఖ్యా విలువల మొత్తాన్ని వాటి సంఖ్యతో విభజించిన ఫలితం. సంఖ్యలతో కూడిన నమూనా కోసం X 1, X 2, ..., Xn, నమూనా సగటు (దీనిచే సూచించబడుతుంది ) సమానం = (X 1 + X 2 + … + Xn) / n, లేదా
నమూనా సగటు ఎక్కడ ఉంది, n- నమూనా పరిమాణం, Xi- నమూనా యొక్క i-వ మూలకం.
నోట్ని డౌన్లోడ్ చేయండి లేదా ఫార్మాట్లో, ఉదాహరణలు ఫార్మాట్లో
15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్స్ (మూర్తి 1) యొక్క ఐదు సంవత్సరాల సగటు వార్షిక రాబడి యొక్క అంకగణిత సగటును గణించడాన్ని పరిగణించండి.

అన్నం. 1. 15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్స్ యొక్క సగటు వార్షిక రాబడి
నమూనా సగటు ఈ క్రింది విధంగా లెక్కించబడుతుంది:

ప్రత్యేకించి అదే సమయంలో బ్యాంక్ లేదా క్రెడిట్ యూనియన్ డిపాజిటర్లు పొందిన 3-4% రాబడితో పోలిస్తే ఇది మంచి రాబడి. మేము రిటర్న్లను క్రమబద్ధీకరించినట్లయితే, ఎనిమిది ఫండ్లు సగటు కంటే ఎక్కువ మరియు ఏడు సగటు కంటే తక్కువ రాబడిని కలిగి ఉన్నాయని సులభంగా చూడవచ్చు. అంకగణిత సగటు సమతౌల్య బిందువుగా పనిచేస్తుంది, తద్వారా తక్కువ రాబడి ఉన్న ఫండ్లు అధిక రాబడి ఉన్న ఫండ్లను బ్యాలెన్స్ చేస్తాయి. నమూనా యొక్క అన్ని అంశాలు సగటును లెక్కించడంలో పాల్గొంటాయి. పంపిణీ సగటు యొక్క ఇతర అంచనాలు ఏవీ ఈ ఆస్తిని కలిగి లేవు.
మీరు అంకగణిత సగటును ఎప్పుడు లెక్కించాలి?అంకగణిత సగటు నమూనాలోని అన్ని అంశాలపై ఆధారపడి ఉంటుంది కాబట్టి, విపరీతమైన విలువల ఉనికి ఫలితాన్ని గణనీయంగా ప్రభావితం చేస్తుంది. అటువంటి పరిస్థితులలో, అంకగణిత సగటు సంఖ్యా డేటా యొక్క అర్ధాన్ని వక్రీకరించవచ్చు. అందువల్ల, విపరీతమైన విలువలను కలిగి ఉన్న డేటా సెట్ను వివరించేటప్పుడు, మధ్యస్థ లేదా అంకగణిత సగటు మరియు మధ్యస్థాన్ని సూచించడం అవసరం. ఉదాహరణకు, మేము నమూనా నుండి RS ఎమర్జింగ్ గ్రోత్ ఫండ్ యొక్క రాబడిని తీసివేస్తే, 14 ఫండ్ల రాబడి యొక్క నమూనా సగటు దాదాపు 1% నుండి 5.19% వరకు తగ్గుతుంది.
మధ్యస్థ
మధ్యస్థం అనేది ఆర్డర్ చేయబడిన సంఖ్యల శ్రేణి యొక్క మధ్య విలువను సూచిస్తుంది. శ్రేణి పునరావృత సంఖ్యలను కలిగి ఉండకపోతే, దాని మూలకాలలో సగం కంటే తక్కువగా ఉంటుంది మరియు సగం మధ్యస్థం కంటే ఎక్కువగా ఉంటుంది. నమూనా విపరీతమైన విలువలను కలిగి ఉన్నట్లయితే, సగటును అంచనా వేయడానికి అంకగణిత సగటు కంటే మధ్యస్థాన్ని ఉపయోగించడం ఉత్తమం. నమూనా యొక్క మధ్యస్థాన్ని లెక్కించడానికి, దానిని ముందుగా ఆదేశించాలి.
ఈ ఫార్ములా అస్పష్టంగా ఉంది. దాని ఫలితం సంఖ్య సరి లేదా బేసి అనే దానిపై ఆధారపడి ఉంటుంది n:
- నమూనా బేసి సంఖ్యలో మూలకాలను కలిగి ఉంటే, మధ్యస్థం (n+1)/2-వ మూలకం.
- నమూనా మూలకాల సంఖ్యను కలిగి ఉంటే, మధ్యస్థం నమూనా యొక్క రెండు మధ్య మూలకాల మధ్య ఉంటుంది మరియు ఈ రెండు మూలకాలపై లెక్కించిన అంకగణిత సగటుకు సమానంగా ఉంటుంది.
15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్ల రాబడిని కలిగి ఉన్న నమూనా యొక్క మధ్యస్థాన్ని లెక్కించడానికి, మీరు ముందుగా ముడి డేటాను క్రమబద్ధీకరించాలి (మూర్తి 2). అప్పుడు మధ్యస్థం నమూనా యొక్క మధ్య మూలకం సంఖ్యకు ఎదురుగా ఉంటుంది; మా ఉదాహరణ నం. 8లో. Excel ఒక ప్రత్యేక ఫంక్షన్ =MEDIAN()ని కలిగి ఉంది, అది క్రమం చేయని శ్రేణులతో కూడా పనిచేస్తుంది.

అన్నం. 2. మధ్యస్థ 15 నిధులు
అందువలన, మధ్యస్థం 6.5. అంటే చాలా ఎక్కువ రిస్క్ ఫండ్స్లో ఒక సగంపై వచ్చే రాబడి 6.5కి మించదు మరియు మిగిలిన సగం రిటర్న్ అది మించిపోయింది. 6.5 మధ్యస్థం 6.08 సగటు కంటే పెద్దది కాదని గమనించండి.
మేము నమూనా నుండి RS ఎమర్జింగ్ గ్రోత్ ఫండ్ యొక్క రిటర్న్ను తీసివేస్తే, మిగిలిన 14 ఫండ్ల మధ్యస్థం 6.2%కి తగ్గుతుంది, అంటే అంకగణిత సగటు (మూర్తి 3) వలె గణనీయంగా ఉండదు.

అన్నం. 3. మధ్యస్థ 14 నిధులు
ఫ్యాషన్
ఈ పదాన్ని మొదటిసారిగా 1894లో పియర్సన్ రూపొందించారు. ఫ్యాషన్ అనేది నమూనాలో చాలా తరచుగా కనిపించే సంఖ్య (అత్యంత ఫ్యాషన్). ఫ్యాషన్ బాగా వివరిస్తుంది, ఉదాహరణకు, కదలకుండా ఆపడానికి ట్రాఫిక్ లైట్ సిగ్నల్కు డ్రైవర్ల యొక్క సాధారణ ప్రతిచర్య. ఫ్యాషన్ ఉపయోగం యొక్క ఒక క్లాసిక్ ఉదాహరణ షూ పరిమాణం లేదా వాల్పేపర్ రంగు ఎంపిక. పంపిణీకి అనేక మోడ్లు ఉంటే, అది మల్టీమోడల్ లేదా మల్టీమోడల్ అని చెప్పబడుతుంది (రెండు లేదా అంతకంటే ఎక్కువ "శిఖరాలు" కలిగి ఉంటుంది). పంపిణీ యొక్క మల్టీమోడాలిటీ అధ్యయనం చేయబడుతున్న వేరియబుల్ యొక్క స్వభావం గురించి ముఖ్యమైన సమాచారాన్ని అందిస్తుంది. ఉదాహరణకు, సామాజిక శాస్త్ర సర్వేలలో, వేరియబుల్ ఏదైనా పట్ల ప్రాధాన్యత లేదా వైఖరిని సూచిస్తే, మల్టీమోడాలిటీ అంటే అనేక విభిన్న అభిప్రాయాలు ఉన్నాయని అర్థం. మల్టీమోడాలిటీ కూడా నమూనా సజాతీయమైనది కాదని సూచికగా పనిచేస్తుంది మరియు పరిశీలనలు రెండు లేదా అంతకంటే ఎక్కువ "అతివ్యాప్తి చెందుతున్న" పంపిణీల ద్వారా రూపొందించబడవచ్చు. అంకగణిత సగటు వలె కాకుండా, అవుట్లియర్లు మోడ్ను ప్రభావితం చేయవు. మ్యూచువల్ ఫండ్ల సగటు వార్షిక రాబడి వంటి నిరంతరంగా పంపిణీ చేయబడిన యాదృచ్ఛిక వేరియబుల్స్ కోసం, మోడ్ కొన్నిసార్లు ఉనికిలో ఉండదు (లేదా అర్ధమే లేదు). ఈ సూచికలు చాలా భిన్నమైన విలువలను తీసుకోగలవు కాబట్టి, పునరావృతమయ్యే విలువలు చాలా అరుదు.
క్వార్టైల్స్
క్వార్టైల్లు పెద్ద సంఖ్యా నమూనాల లక్షణాలను వివరించేటప్పుడు డేటా పంపిణీని మూల్యాంకనం చేయడానికి తరచుగా ఉపయోగించే కొలమానాలు. మధ్యస్థం ఆర్డర్ చేసిన శ్రేణిని సగానికి విభజిస్తుంది (50% శ్రేణి యొక్క మూలకాలు మధ్యస్థం కంటే తక్కువ మరియు 50% ఎక్కువ), క్వార్టైల్స్ ఆర్డర్ చేసిన డేటా సెట్ను నాలుగు భాగాలుగా విభజిస్తాయి. Q 1 , మధ్యస్థ మరియు Q 3 విలువలు వరుసగా 25వ, 50వ మరియు 75వ శాతాలు. మొదటి క్వార్టైల్ Q 1 అనేది నమూనాను రెండు భాగాలుగా విభజించే సంఖ్య: 25% మూలకాలు మొదటి క్వార్టైల్ కంటే తక్కువ మరియు 75% ఎక్కువ.
మూడవ క్వార్టైల్ Q 3 అనేది నమూనాను రెండు భాగాలుగా విభజించే సంఖ్య: 75% మూలకాలు మూడవ క్వార్టైల్ కంటే తక్కువగా ఉంటాయి మరియు 25% ఎక్కువ.
2007కి ముందు Excel సంస్కరణల్లో క్వార్టైల్లను లెక్కించేందుకు, =QUARTILE(array,part) ఫంక్షన్ని ఉపయోగించండి. Excel 2010 నుండి ప్రారంభించి, రెండు విధులు ఉపయోగించబడతాయి:
- =QUARTILE.ON(శ్రేణి, భాగం)
- =QUARTILE.EXC(శ్రేణి, భాగం)
ఈ రెండు విధులు కొద్దిగా భిన్నమైన విలువలను ఇస్తాయి (మూర్తి 4). ఉదాహరణకు, 15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్ల సగటు వార్షిక రాబడిని కలిగి ఉన్న నమూనా యొక్క క్వార్టైల్లను లెక్కించేటప్పుడు, QUARTILE.IN మరియు QUARTILE.EX కోసం Q 1 = 1.8 లేదా –0.7. మార్గం ద్వారా, మునుపు ఉపయోగించిన QUARTILE ఫంక్షన్, ఆధునిక QUARTILE.ON ఫంక్షన్కు అనుగుణంగా ఉంటుంది. పై సూత్రాలను ఉపయోగించి Excelలో క్వార్టైల్లను లెక్కించడానికి, డేటా శ్రేణిని ఆర్డర్ చేయవలసిన అవసరం లేదు.

అన్నం. 4. ఎక్సెల్లో క్వార్టైల్లను లెక్కించడం
మనం మళ్ళీ నొక్కి చెబుతాము. Excel ఏకరూపం కోసం క్వార్టైల్లను లెక్కించగలదు వివిక్త సిరీస్, యాదృచ్ఛిక వేరియబుల్ యొక్క విలువలను కలిగి ఉంటుంది. ఫ్రీక్వెన్సీ-ఆధారిత పంపిణీ కోసం క్వార్టైల్ల గణన విభాగంలో క్రింద ఇవ్వబడింది.
రేఖాగణిత సగటు
అంకగణిత సగటు వలె కాకుండా, రేఖాగణిత సగటు కాలక్రమేణా వేరియబుల్లో మార్పు స్థాయిని అంచనా వేయడానికి మిమ్మల్ని అనుమతిస్తుంది. రేఖాగణిత సగటు మూలం nపని నుండి వ డిగ్రీ nపరిమాణాలు (Excelలో =SRGEOM ఫంక్షన్ ఉపయోగించబడుతుంది):
జి= (X 1 * X 2 * … * X n) 1/n
ఇదే విధమైన పరామితి - లాభం రేటు యొక్క రేఖాగణిత సగటు విలువ - సూత్రం ద్వారా నిర్ణయించబడుతుంది:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
ఎక్కడ ఆర్ ఐ- కోసం లాభం రేటు iవ కాల వ్యవధి.
ఉదాహరణకు, ప్రారంభ పెట్టుబడి $100,000 అనుకుందాం. మొదటి సంవత్సరం ముగిసే సమయానికి, అది $50,000కి పడిపోయింది మరియు రెండవ సంవత్సరం చివరి నాటికి $100,000 ప్రారంభ స్థాయికి తిరిగి వస్తుంది. ఈ పెట్టుబడిపై రాబడి రేటు రెండు -సంవత్సరం కాలం 0కి సమానం, ఎందుకంటే ఫండ్ల ప్రారంభ మరియు చివరి మొత్తాలు ఒకదానికొకటి సమానంగా ఉంటాయి. అయితే, మొదటి సంవత్సరంలో రాబడి రేటు R 1 = (50,000 – 100,000) / 100,000 = –0.5 , కాబట్టి, వార్షిక రాబడి రేట్ల అంకగణిత సగటు = (–0.5 + 1) / 2 = 0.25 లేదా 25% మరియు రెండవ R 2 = (100,000 – 50,000) / 50,000 = 1. అదే సమయంలో, రెండు సంవత్సరాలకు లాభం రేటు యొక్క రేఖాగణిత సగటు విలువ దీనికి సమానంగా ఉంటుంది: G = [(1–0.5) * (1+ 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. కాబట్టి, రేఖాగణిత సగటు రెండు సంవత్సరాల వ్యవధి కంటే పెట్టుబడి పరిమాణంలో మార్పును (మరింత ఖచ్చితంగా, మార్పులు లేకపోవడం) ప్రతిబింబిస్తుంది. అంకగణిత సగటు.
ఆసక్తికరమైన నిజాలు.ముందుగా, రేఖాగణిత సగటు ఎల్లప్పుడూ అదే సంఖ్యల అంకగణిత సగటు కంటే తక్కువగా ఉంటుంది. తీసుకున్న అన్ని సంఖ్యలు ఒకదానికొకటి సమానంగా ఉన్నప్పుడు మినహా. రెండవది, లంబ త్రిభుజం యొక్క లక్షణాలను పరిగణనలోకి తీసుకోవడం ద్వారా, సగటును రేఖాగణితం అని ఎందుకు పిలుస్తారో మీరు అర్థం చేసుకోవచ్చు. కుడి త్రిభుజం యొక్క ఎత్తు, హైపోటెన్యూస్కు తగ్గించబడుతుంది, ఇది హైపోటెన్యూస్పై కాళ్ల అంచనాల మధ్య సగటు అనుపాతం, మరియు ప్రతి కాలు హైపోటెన్యూస్ మరియు హైపోటెన్యూస్పై దాని ప్రొజెక్షన్ మధ్య సగటు అనుపాతం (Fig. 5). ఇది రెండు (పొడవుల) విభాగాల రేఖాగణిత సగటును నిర్మించడానికి ఒక రేఖాగణిత మార్గాన్ని ఇస్తుంది: మీరు ఈ రెండు విభాగాల మొత్తంపై ఒక వ్యాసంగా ఒక వృత్తాన్ని నిర్మించాలి, ఆపై వాటి కనెక్షన్ పాయింట్ నుండి సర్కిల్తో ఖండనకు ఎత్తు పునరుద్ధరించబడుతుంది. కావలసిన విలువను ఇస్తుంది:

అన్నం. 5. రేఖాగణిత సగటు యొక్క రేఖాగణిత స్వభావం (వికీపీడియా నుండి చిత్రం)
సంఖ్యా డేటా యొక్క రెండవ ముఖ్యమైన ఆస్తి వారిది వైవిధ్యం, డేటా వ్యాప్తి స్థాయిని వర్గీకరిస్తుంది. రెండు వేర్వేరు నమూనాలు సాధనాలు మరియు వ్యత్యాసాలు రెండింటిలోనూ విభిన్నంగా ఉండవచ్చు. అయితే, అంజీర్లో చూపిన విధంగా. 6 మరియు 7, రెండు నమూనాలు ఒకే విధమైన వైవిధ్యాలను కలిగి ఉండవచ్చు కానీ వేర్వేరు మార్గాలను కలిగి ఉండవచ్చు లేదా అదే సాధనాలు మరియు పూర్తిగా భిన్నమైన వైవిధ్యాలు. అంజీర్లోని బహుభుజి Bకి అనుగుణంగా ఉన్న డేటా. 7, బహుభుజి A నిర్మించబడిన డేటా కంటే చాలా తక్కువగా మార్చండి.

అన్నం. 6. ఒకే స్ప్రెడ్ మరియు విభిన్న సగటు విలువలతో రెండు సుష్ట బెల్-ఆకారపు పంపిణీలు

అన్నం. 7. ఒకే సగటు విలువలు మరియు విభిన్న స్ప్రెడ్లతో రెండు సుష్ట బెల్-ఆకారపు పంపిణీలు
డేటా వైవిధ్యానికి ఐదు అంచనాలు ఉన్నాయి:
- పరిధి,
- ఇంటర్క్వార్టైల్ పరిధి,
- చెదరగొట్టడం,
- ప్రామాణిక విచలనం,
- వైవిధ్యం యొక్క గుణకం.
పరిధి
పరిధి అనేది నమూనా యొక్క అతి పెద్ద మరియు చిన్న మూలకాల మధ్య వ్యత్యాసం:
పరిధి = Xగరిష్టం - Xకనిష్ట
15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్ల సగటు వార్షిక రాబడిని కలిగి ఉన్న నమూనా పరిధిని ఆర్డర్ చేసిన శ్రేణిని ఉపయోగించి లెక్కించవచ్చు (మూర్తి 4 చూడండి): రేంజ్ = 18.5 – (–6.1) = 24.6. అంటే చాలా ఎక్కువ రిస్క్ ఫండ్స్ యొక్క అత్యధిక మరియు అత్యల్ప సగటు వార్షిక రాబడి మధ్య వ్యత్యాసం 24.6%.
పరిధి మొత్తం డేటా వ్యాప్తిని కొలుస్తుంది. నమూనా పరిధి డేటా యొక్క మొత్తం వ్యాప్తికి చాలా సులభమైన అంచనా అయినప్పటికీ, దాని బలహీనత ఏమిటంటే, కనిష్ట మరియు గరిష్ట మూలకాల మధ్య డేటా ఎలా పంపిణీ చేయబడుతుందో ఖచ్చితంగా పరిగణనలోకి తీసుకోదు. ఈ ప్రభావం అంజీర్లో స్పష్టంగా కనిపిస్తుంది. 8, ఇది ఒకే పరిధిని కలిగి ఉన్న నమూనాలను వివరిస్తుంది. స్కేల్ B ఒక నమూనా కనీసం ఒక విపరీతమైన విలువను కలిగి ఉన్నట్లయితే, నమూనా పరిధి డేటా వ్యాప్తికి సంబంధించిన చాలా ఖచ్చితమైన అంచనా.

అన్నం. 8. ఒకే శ్రేణితో మూడు నమూనాల పోలిక; త్రిభుజం స్కేల్ యొక్క మద్దతును సూచిస్తుంది మరియు దాని స్థానం నమూనా సగటుకు అనుగుణంగా ఉంటుంది
ఇంటర్క్వార్టైల్ పరిధి
ఇంటర్క్వార్టైల్ లేదా సగటు పరిధి అనేది నమూనా యొక్క మూడవ మరియు మొదటి క్వార్టైల్ల మధ్య వ్యత్యాసం:
ఇంటర్క్వార్టైల్ పరిధి = Q 3 – Q 1
ఈ విలువ 50% మూలకాల యొక్క స్కాటర్ను అంచనా వేయడానికి అనుమతిస్తుంది మరియు తీవ్రమైన మూలకాల ప్రభావాన్ని పరిగణనలోకి తీసుకోదు. 15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్ల సగటు వార్షిక రాబడిని కలిగి ఉన్న నమూనా యొక్క ఇంటర్క్వార్టైల్ పరిధిని అంజీర్లోని డేటాను ఉపయోగించి లెక్కించవచ్చు. 4 (ఉదాహరణకు, QUARTILE.EXC ఫంక్షన్ కోసం): ఇంటర్క్వార్టైల్ పరిధి = 9.8 – (–0.7) = 10.5. 9.8 మరియు -0.7 సంఖ్యలచే పరిమితం చేయబడిన విరామాన్ని తరచుగా మధ్య సగం అని పిలుస్తారు.
Q 1 మరియు Q 3 యొక్క విలువలు మరియు అందువల్ల ఇంటర్క్వార్టైల్ పరిధి, అవుట్లయర్ల ఉనికిపై ఆధారపడి ఉండదని గమనించాలి, ఎందుకంటే వాటి గణన Q 1 కంటే తక్కువ లేదా అంతకంటే ఎక్కువ ఉండే ఏ విలువను పరిగణనలోకి తీసుకోదు. Q 3 కంటే. మధ్యస్థ, మొదటి మరియు మూడవ త్రైమాసికాలు మరియు అంతర్క్వార్టైల్ పరిధి వంటి సారాంశ కొలతలు బయటివారిచే ప్రభావితం చేయబడని వాటిని బలమైన చర్యలు అంటారు.
పరిధి మరియు ఇంటర్క్వార్టైల్ పరిధి వరుసగా ఒక నమూనా యొక్క మొత్తం మరియు సగటు వ్యాప్తి యొక్క అంచనాలను అందించినప్పటికీ, ఈ అంచనాలు ఏవీ డేటా ఎలా పంపిణీ చేయబడతాయో పరిగణనలోకి తీసుకోలేదు. వైవిధ్యం మరియు ప్రామాణిక విచలనంఈ లోపం లేనివి. ఈ సూచికలు సగటు విలువ చుట్టూ డేటా హెచ్చుతగ్గుల స్థాయిని అంచనా వేయడానికి మిమ్మల్ని అనుమతిస్తాయి. నమూనా వైవిధ్యంప్రతి నమూనా మూలకం మరియు నమూనా సగటు మధ్య వ్యత్యాసాల చతురస్రాల నుండి లెక్కించబడిన అంకగణిత సగటు యొక్క ఉజ్జాయింపు. నమూనా X 1, X 2, ... X n కోసం, నమూనా వ్యత్యాసం (S 2 గుర్తుతో సూచించబడుతుంది, ఇది క్రింది ఫార్ములా ద్వారా ఇవ్వబడుతుంది:

సాధారణంగా, నమూనా వ్యత్యాసం అనేది నమూనా మూలకాలు మరియు నమూనా సగటు మధ్య వ్యత్యాసాల చతురస్రాల మొత్తం, నమూనా పరిమాణం మైనస్ ఒకటికి సమానమైన విలువతో విభజించబడింది:

ఎక్కడ - అంకగణిత సగటు, n- నమూనా పరిమాణం, X i - iవ ఎంపిక మూలకం X. వెర్షన్ 2007కి ముందు Excelలో, నమూనా వ్యత్యాసాన్ని లెక్కించడానికి =VARIN() ఫంక్షన్ ఉపయోగించబడింది; వెర్షన్ 2010 నుండి, =VARIAN() ఫంక్షన్ ఉపయోగించబడుతుంది.
డేటా వ్యాప్తికి సంబంధించిన అత్యంత ఆచరణాత్మకమైన మరియు విస్తృతంగా ఆమోదించబడిన అంచనా నమూనా ప్రామాణిక విచలనం. ఈ సూచిక S గుర్తుతో సూచించబడుతుంది మరియు నమూనా వ్యత్యాసం యొక్క వర్గమూలానికి సమానం:

వెర్షన్ 2007కి ముందు Excelలో, ప్రామాణిక నమూనా విచలనాన్ని లెక్కించడానికి ఫంక్షన్ =STDEV.() ఉపయోగించబడింది; వెర్షన్ 2010 నుండి, ఫంక్షన్ =STDEV.V() ఉపయోగించబడుతుంది. ఈ ఫంక్షన్లను గణించడానికి, డేటా శ్రేణి క్రమం లేకుండా ఉండవచ్చు.
నమూనా వ్యత్యాసం లేదా నమూనా ప్రామాణిక విచలనం ప్రతికూలంగా ఉండకూడదు. నమూనాలోని అన్ని అంశాలు ఒకదానికొకటి సమానంగా ఉంటే, S 2 మరియు S సూచికలు సున్నాగా ఉండే ఏకైక పరిస్థితి. పూర్తిగా అసంభవమైన ఈ సందర్భంలో, పరిధి మరియు ఇంటర్క్వార్టైల్ పరిధి కూడా సున్నా.
సంఖ్యా డేటా అంతర్గతంగా అస్థిరమైనది. ఏదైనా వేరియబుల్ అనేక విభిన్న విలువలను తీసుకోవచ్చు. ఉదాహరణకు, వివిధ మ్యూచువల్ ఫండ్లు వేర్వేరు రాబడి మరియు నష్టాలను కలిగి ఉంటాయి. సంఖ్యా డేటా యొక్క వైవిధ్యం కారణంగా, ప్రకృతిలో సారాంశం ఉన్న సగటు యొక్క అంచనాలను మాత్రమే కాకుండా, డేటా యొక్క వ్యాప్తిని వర్గీకరించే వ్యత్యాసం యొక్క అంచనాలను కూడా అధ్యయనం చేయడం చాలా ముఖ్యం.
చెదరగొట్టడం మరియు ప్రామాణిక విచలనం సగటు విలువ చుట్టూ డేటా వ్యాప్తిని అంచనా వేయడానికి మిమ్మల్ని అనుమతిస్తాయి, మరో మాటలో చెప్పాలంటే, సగటు కంటే ఎన్ని నమూనా అంశాలు తక్కువగా ఉన్నాయి మరియు ఎన్ని ఎక్కువ ఉన్నాయో నిర్ణయించండి. విక్షేపణ కొన్ని విలువైన గణిత లక్షణాలను కలిగి ఉంది. అయితే, దాని విలువ కొలత యూనిట్ యొక్క చదరపు - చదరపు శాతం, చదరపు డాలర్, చదరపు అంగుళం మొదలైనవి. అందువల్ల, వ్యాప్తి యొక్క సహజ కొలత ప్రామాణిక విచలనం, ఇది ఆదాయ శాతం, డాలర్లు లేదా అంగుళాల సాధారణ యూనిట్లలో వ్యక్తీకరించబడుతుంది.
ప్రామాణిక విచలనం సగటు విలువ చుట్టూ నమూనా మూలకాల యొక్క వైవిధ్యం మొత్తాన్ని అంచనా వేయడానికి మిమ్మల్ని అనుమతిస్తుంది. దాదాపు అన్ని పరిస్థితులలో, గమనించిన చాలా విలువలు సగటు నుండి ప్లస్ లేదా మైనస్ ఒక ప్రామాణిక విచలనం పరిధిలో ఉంటాయి. పర్యవసానంగా, నమూనా మూలకాల యొక్క అంకగణిత సగటు మరియు ప్రామాణిక నమూనా విచలనాన్ని తెలుసుకోవడం, డేటాలో ఎక్కువ భాగం చెందిన విరామాన్ని నిర్ణయించడం సాధ్యమవుతుంది.
15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్లకు రాబడి యొక్క ప్రామాణిక విచలనం 6.6 (మూర్తి 9). దీనర్థం నిధులలో ఎక్కువ భాగం యొక్క లాభదాయకత సగటు విలువ నుండి 6.6% కంటే ఎక్కువ తేడా లేకుండా ఉంటుంది (అనగా, ఇది నుండి పరిధిలో హెచ్చుతగ్గులకు గురవుతుంది – ఎస్= 6.2 – 6.6 = –0.4 వరకు +S= 12.8). వాస్తవానికి, ఐదు సంవత్సరాల సగటు వార్షిక రాబడి 53.3% (15లో 8) ఈ పరిధిలోనే ఉంటుంది.

అన్నం. 9. నమూనా ప్రామాణిక విచలనం
స్క్వేర్డ్ తేడాలను సంక్షిప్తీకరించేటప్పుడు, సగటు నుండి మరింత దూరంగా ఉన్న నమూనా అంశాలు సగటుకు దగ్గరగా ఉన్న అంశాల కంటే ఎక్కువ బరువు కలిగి ఉన్నాయని గమనించండి. పంపిణీ యొక్క సగటును అంచనా వేయడానికి అంకగణిత సగటు ఎక్కువగా ఉపయోగించబడటానికి ఈ లక్షణం ప్రధాన కారణం.
వైవిధ్యం యొక్క గుణకం
స్కాటర్ యొక్క మునుపటి అంచనాల వలె కాకుండా, వైవిధ్యం యొక్క గుణకం సాపేక్ష అంచనా. ఇది ఎల్లప్పుడూ శాతంగా కొలుస్తారు మరియు అసలు డేటా యూనిట్లలో కాదు. వైవిధ్యం యొక్క గుణకం, CV చిహ్నాలచే సూచించబడుతుంది, సగటు చుట్టూ ఉన్న డేటా యొక్క వ్యాప్తిని కొలుస్తుంది. వైవిధ్యం యొక్క గుణకం ప్రామాణిక విచలనానికి సమానం, ఇది అంకగణిత సగటుతో విభజించబడింది మరియు 100% గుణించబడుతుంది:

ఎక్కడ ఎస్- ప్రామాణిక నమూనా విచలనం, - నమూనా సగటు.
వైవిధ్యం యొక్క గుణకం రెండు నమూనాలను పోల్చడానికి మిమ్మల్ని అనుమతిస్తుంది, దీని మూలకాలు వేర్వేరు కొలత యూనిట్లలో వ్యక్తీకరించబడతాయి. ఉదాహరణకు, మెయిల్ డెలివరీ సర్వీస్ మేనేజర్ తన ట్రక్కుల సముదాయాన్ని పునరుద్ధరించాలని భావిస్తాడు. ప్యాకేజీలను లోడ్ చేస్తున్నప్పుడు, పరిగణించవలసిన రెండు పరిమితులు ఉన్నాయి: ప్రతి ప్యాకేజీ యొక్క బరువు (పౌండ్లలో) మరియు వాల్యూమ్ (క్యూబిక్ అడుగులలో). 200 బ్యాగ్లను కలిగి ఉన్న నమూనాలో, సగటు బరువు 26.0 పౌండ్లు, బరువు యొక్క ప్రామాణిక విచలనం 3.9 పౌండ్లు, సగటు బ్యాగ్ వాల్యూమ్ 8.8 క్యూబిక్ అడుగులు మరియు వాల్యూమ్ యొక్క ప్రామాణిక విచలనం 2.2 క్యూబిక్ అడుగులు అని అనుకుందాం. ప్యాకేజీల బరువు మరియు వాల్యూమ్లో వైవిధ్యాన్ని ఎలా పోల్చాలి?
బరువు మరియు వాల్యూమ్ యొక్క కొలత యూనిట్లు ఒకదానికొకటి భిన్నంగా ఉంటాయి కాబట్టి, మేనేజర్ ఈ పరిమాణాల సాపేక్ష వ్యాప్తిని సరిపోల్చాలి. బరువు యొక్క వైవిధ్యం యొక్క గుణకం CV W = 3.9 / 26.0 * 100% = 15%, మరియు వాల్యూమ్ యొక్క వైవిధ్యం యొక్క గుణకం CV V = 2.2 / 8.8 * 100% = 25%. అందువల్ల, ప్యాకెట్ల పరిమాణంలో సాపేక్ష వైవిధ్యం వాటి బరువులో సాపేక్ష వైవిధ్యం కంటే చాలా ఎక్కువగా ఉంటుంది.
పంపిణీ రూపం
నమూనా యొక్క మూడవ ముఖ్యమైన లక్షణం దాని పంపిణీ ఆకారం. ఈ పంపిణీ సుష్ట లేదా అసమానంగా ఉండవచ్చు. పంపిణీ ఆకారాన్ని వివరించడానికి, దాని సగటు మరియు మధ్యస్థాన్ని లెక్కించడం అవసరం. రెండూ ఒకేలా ఉంటే, వేరియబుల్ సుష్టంగా పంపిణీ చేయబడినదిగా పరిగణించబడుతుంది. వేరియబుల్ యొక్క సగటు విలువ మధ్యస్థం కంటే ఎక్కువగా ఉంటే, దాని పంపిణీ సానుకూల వక్రతను కలిగి ఉంటుంది (Fig. 10). మధ్యస్థం సగటు కంటే ఎక్కువగా ఉంటే, వేరియబుల్ పంపిణీ ప్రతికూలంగా వక్రంగా ఉంటుంది. సగటు అసాధారణంగా అధిక విలువలకు పెరిగినప్పుడు సానుకూల వక్రత ఏర్పడుతుంది. సగటు అసాధారణంగా చిన్న విలువలకు తగ్గినప్పుడు ప్రతికూల వక్రత ఏర్పడుతుంది. వేరియబుల్ ఇరువైపులా ఎటువంటి విపరీతమైన విలువలను తీసుకోనట్లయితే అది సుష్టంగా పంపిణీ చేయబడుతుంది, తద్వారా వేరియబుల్ యొక్క పెద్ద మరియు చిన్న విలువలు ఒకదానికొకటి రద్దు చేయబడతాయి.

అన్నం. 10. మూడు రకాల పంపిణీలు
A స్కేల్పై చూపబడిన డేటా ప్రతికూలంగా వక్రీకరించబడింది. ఈ సంఖ్య అసాధారణంగా చిన్న విలువలు ఉండటం వల్ల పొడవాటి తోక మరియు ఎడమవైపు వక్రతను చూపుతుంది. ఈ చాలా చిన్న విలువలు సగటు విలువను ఎడమవైపుకు మారుస్తాయి, ఇది మధ్యస్థం కంటే తక్కువగా ఉంటుంది. స్కేల్ Bపై చూపబడిన డేటా సుష్టంగా పంపిణీ చేయబడుతుంది. పంపిణీ యొక్క ఎడమ మరియు కుడి భాగాలు తమకు తాము ప్రతిబింబించే ప్రతిబింబాలు. పెద్ద మరియు చిన్న విలువలు ఒకదానికొకటి సమతుల్యం చేస్తాయి మరియు సగటు మరియు మధ్యస్థం సమానంగా ఉంటాయి. స్కేల్ Bపై చూపబడిన డేటా సానుకూలంగా వక్రంగా ఉంది. ఈ సంఖ్య అసాధారణంగా అధిక విలువలు ఉండటం వల్ల పొడవాటి తోక మరియు కుడి వైపున వక్రంగా చూపిస్తుంది. ఈ చాలా పెద్ద విలువలు సగటును కుడివైపుకి మారుస్తాయి, ఇది మధ్యస్థం కంటే పెద్దదిగా చేస్తుంది.
Excelలో, యాడ్-ఇన్ ఉపయోగించి వివరణాత్మక గణాంకాలను పొందవచ్చు విశ్లేషణ ప్యాకేజీ. మెను ద్వారా వెళ్ళండి సమాచారం → డేటా విశ్లేషణ, తెరుచుకునే విండోలో, లైన్ ఎంచుకోండి వివరణాత్మక గణాంకాలుమరియు క్లిక్ చేయండి అలాగే. కిటికీలో వివరణాత్మక గణాంకాలుతప్పకుండా సూచించండి ఇన్పుట్ విరామం(Fig. 11). మీరు అసలు డేటా వలె అదే షీట్లో వివరణాత్మక గణాంకాలను చూడాలనుకుంటే, రేడియో బటన్ను ఎంచుకోండి అవుట్పుట్ విరామంమరియు ప్రదర్శించబడే గణాంకాల యొక్క ఎగువ ఎడమ మూలలో ఉంచవలసిన సెల్ను పేర్కొనండి (మా ఉదాహరణలో, $C$1). మీరు కొత్త షీట్ లేదా కొత్త వర్క్బుక్కి డేటాను అవుట్పుట్ చేయాలనుకుంటే, మీరు తగిన రేడియో బటన్ను ఎంచుకోవాలి. పక్కన ఉన్న పెట్టెను చెక్ చేయండి సారాంశం గణాంకాలు. కావాలనుకుంటే, మీరు కూడా ఎంచుకోవచ్చు కష్టం స్థాయి,kth చిన్నది మరియుkth అతిపెద్ద.
డిపాజిట్లో ఉంటే సమాచారంప్రాంతంలో విశ్లేషణమీకు చిహ్నం కనిపించదు డేటా విశ్లేషణ, మీరు ముందుగా యాడ్-ఆన్ని ఇన్స్టాల్ చేయాలి విశ్లేషణ ప్యాకేజీ(చూడండి, ఉదాహరణకు,).

అన్నం. 11. యాడ్-ఇన్ ఉపయోగించి గణించబడిన చాలా ఎక్కువ స్థాయి రిస్క్ ఉన్న నిధుల యొక్క ఐదు సంవత్సరాల సగటు వార్షిక రాబడి యొక్క వివరణాత్మక గణాంకాలు డేటా విశ్లేషణఎక్సెల్ ప్రోగ్రామ్లు
Excel పైన చర్చించిన అనేక గణాంకాలను గణిస్తుంది: సగటు, మధ్యస్థ, మోడ్, ప్రామాణిక విచలనం, వ్యత్యాసం, పరిధి ( విరామం), కనిష్ట, గరిష్ట మరియు నమూనా పరిమాణం ( తనిఖీ) Excel మనకు కొత్తగా ఉన్న కొన్ని గణాంకాలను కూడా లెక్కిస్తుంది: ప్రామాణిక లోపం, కుర్టోసిస్ మరియు వక్రత. ప్రామాణిక లోపంనమూనా పరిమాణం యొక్క వర్గమూలంతో విభజించబడిన ప్రామాణిక విచలనానికి సమానం. అసమానతపంపిణీ యొక్క సమరూపత నుండి విచలనాన్ని వర్ణిస్తుంది మరియు ఇది నమూనా మూలకాలు మరియు సగటు విలువ మధ్య వ్యత్యాసాల క్యూబ్పై ఆధారపడి ఉండే ఫంక్షన్. కర్టోసిస్ అనేది పంపిణీ యొక్క టెయిల్లతో పోలిస్తే సగటు చుట్టూ ఉన్న డేటా యొక్క సాపేక్ష సాంద్రత యొక్క కొలత మరియు నమూనా మూలకాలు మరియు నాల్గవ శక్తికి పెంచబడిన సగటు మధ్య తేడాలపై ఆధారపడి ఉంటుంది.
జనాభా కోసం వివరణాత్మక గణాంకాలను గణించడం
పైన చర్చించిన పంపిణీ యొక్క సగటు, వ్యాప్తి మరియు ఆకృతి నమూనా నుండి నిర్ణయించబడిన లక్షణాలు. అయినప్పటికీ, డేటా సెట్ మొత్తం జనాభా యొక్క సంఖ్యా కొలతలను కలిగి ఉంటే, దాని పారామితులను లెక్కించవచ్చు. ఇటువంటి పారామితులలో జనాభా యొక్క అంచనా విలువ, వ్యాప్తి మరియు ప్రామాణిక విచలనం ఉన్నాయి.
ఆశించిన విలువజనాభా పరిమాణంతో భాగించబడిన జనాభాలోని అన్ని విలువల మొత్తానికి సమానం:

ఎక్కడ µ - అంచనా విలువ, Xi- iవేరియబుల్ యొక్క పరిశీలన X, ఎన్- సాధారణ జనాభా పరిమాణం. Excelలో, గణిత నిరీక్షణను లెక్కించడానికి, అంకగణిత సగటు కోసం అదే ఫంక్షన్ ఉపయోగించబడుతుంది: = AVERAGE().
జనాభా వ్యత్యాసంసాధారణ జనాభా మరియు మత్ మూలకాల మధ్య వ్యత్యాసాల చతురస్రాల మొత్తానికి సమానం. అంచనా జనాభా పరిమాణంతో విభజించబడింది:

ఎక్కడ σ 2- సాధారణ జనాభా చెదరగొట్టడం. వెర్షన్ 2007కి ముందు Excelలో, వెర్షన్ 2010 =VARP()తో ప్రారంభించి, జనాభా యొక్క వ్యత్యాసాన్ని గణించడానికి ఫంక్షన్ =VARP() ఉపయోగించబడుతుంది.
జనాభా ప్రామాణిక విచలనంజనాభా వ్యత్యాసం యొక్క వర్గమూలానికి సమానం:

వెర్షన్ 2007కి ముందు Excelలో, జనాభా యొక్క ప్రామాణిక విచలనాన్ని లెక్కించేందుకు =STDEV() ఫంక్షన్ ఉపయోగించబడుతుంది, ఇది వెర్షన్ 2010 =STDEV.Y()తో ప్రారంభమవుతుంది. జనాభా వ్యత్యాసం మరియు ప్రామాణిక విచలనం యొక్క సూత్రాలు నమూనా వ్యత్యాసం మరియు ప్రామాణిక విచలనాన్ని లెక్కించే సూత్రాల నుండి భిన్నంగా ఉన్నాయని గమనించండి. నమూనా గణాంకాలను లెక్కించేటప్పుడు S 2మరియు ఎస్భిన్నం యొక్క హారం n – 1, మరియు పారామితులను లెక్కించేటప్పుడు σ 2మరియు σ - సాధారణ జనాభా పరిమాణం ఎన్.
ముఖ్యనియమంగా
చాలా సందర్భాలలో, పెద్ద సంఖ్యలో పరిశీలనలు మధ్యస్థం చుట్టూ కేంద్రీకృతమై, క్లస్టర్గా ఏర్పడతాయి. సానుకూల వక్రతతో ఉన్న డేటా సెట్లలో, ఈ క్లస్టర్ గణిత నిరీక్షణకు ఎడమవైపు (అనగా, దిగువన) ఉంటుంది మరియు ప్రతికూల వక్రత ఉన్న సెట్లలో, ఈ క్లస్టర్ గణిత నిరీక్షణకు కుడి వైపున (అంటే, పైన) ఉంటుంది. సిమెట్రిక్ డేటా కోసం, సగటు మరియు మధ్యస్థం ఒకేలా ఉంటాయి మరియు సగటు చుట్టూ పరిశీలనల సమూహం, గంట ఆకారపు పంపిణీని ఏర్పరుస్తుంది. పంపిణీ స్పష్టంగా వక్రీకరించబడకపోతే మరియు డేటా గురుత్వాకర్షణ కేంద్రం చుట్టూ కేంద్రీకృతమై ఉంటే, వేరియబిలిటీని అంచనా వేయడానికి ఉపయోగించే ప్రాథమిక నియమం ఏమిటంటే, డేటా బెల్ ఆకారపు పంపిణీని కలిగి ఉంటే, సుమారుగా 68% పరిశీలనలు లోపలే ఉంటాయి. అంచనా విలువ యొక్క ఒక ప్రామాణిక విచలనం.సుమారుగా 95% పరిశీలనలు గణిత నిరీక్షణ నుండి రెండు ప్రామాణిక విచలనాల కంటే ఎక్కువ దూరంలో లేవు మరియు 99.7% పరిశీలనలు గణిత నిరీక్షణ నుండి మూడు ప్రామాణిక విచలనాల కంటే ఎక్కువ దూరంలో లేవు.
అందువలన, ప్రామాణిక విచలనం, ఇది అంచనా విలువ చుట్టూ సగటు వైవిధ్యం యొక్క అంచనా, పరిశీలనలు ఎలా పంపిణీ చేయబడతాయో అర్థం చేసుకోవడానికి మరియు అవుట్లయర్లను గుర్తించడానికి సహాయపడుతుంది. బొటనవేలు నియమం ఏమిటంటే, బెల్-ఆకారపు పంపిణీల కోసం, ఇరవైలో ఒక విలువ మాత్రమే గణిత అంచనా నుండి రెండు కంటే ఎక్కువ ప్రామాణిక విచలనాల ద్వారా భిన్నంగా ఉంటుంది. అందువలన, విరామం వెలుపల విలువలు µ ± 2σ, అవుట్లెర్స్గా పరిగణించవచ్చు. అదనంగా, 1000 పరిశీలనలలో మూడు మాత్రమే గణిత అంచనా నుండి మూడు కంటే ఎక్కువ ప్రామాణిక విచలనాల ద్వారా భిన్నంగా ఉంటాయి. అందువలన, విరామం వెలుపల విలువలు µ ± 3σదాదాపు ఎల్లప్పుడూ బయటి వ్యక్తులు. బాగా వక్రంగా ఉన్న లేదా బెల్ ఆకారంలో లేని పంపిణీల కోసం, Bienamay-Chebishev సూత్రం వర్తించవచ్చు.
వంద సంవత్సరాల క్రితం, గణిత శాస్త్రజ్ఞులు Bienamay మరియు Chebyshev స్వతంత్రంగా ప్రామాణిక విచలనం యొక్క ఉపయోగకరమైన ఆస్తిని కనుగొన్నారు. పంపిణీ ఆకారంతో సంబంధం లేకుండా, ఏదైనా డేటా సెట్ కోసం, దూరం లోపల ఉండే పరిశీలనల శాతం అని వారు కనుగొన్నారు కెగణిత నిరీక్షణ నుండి ప్రామాణిక విచలనాలు, తక్కువ కాదు (1 – 1/ k 2)*100%.
ఉదాహరణకు, ఉంటే కె= 2, Bienname-Chebishev నియమం ప్రకారం కనీసం (1 – (1/2) 2) x 100% = 75% పరిశీలనలు తప్పనిసరిగా విరామంలో ఉండాలి µ ± 2σ. ఈ నియమం ఎవరికైనా వర్తిస్తుంది కె, ఒకటి మించిపోయింది. Bienamay-Chebishev నియమం చాలా సాధారణమైనది మరియు ఏ రకమైన పంపిణీకి అయినా చెల్లుబాటు అవుతుంది. ఇది కనీస పరిశీలనల సంఖ్యను నిర్దేశిస్తుంది, దీని నుండి గణిత అంచనాకు దూరం పేర్కొన్న విలువను మించదు. అయినప్పటికీ, పంపిణీ గంట ఆకారంలో ఉంటే, అంచనా విలువ చుట్టూ ఉన్న డేటా ఏకాగ్రతను బొటనవేలు నియమం మరింత ఖచ్చితంగా అంచనా వేస్తుంది.
ఫ్రీక్వెన్సీ-బేస్డ్ డిస్ట్రిబ్యూషన్ కోసం వివరణాత్మక గణాంకాలను గణించడం
అసలు డేటా అందుబాటులో లేకుంటే, ఫ్రీక్వెన్సీ పంపిణీ మాత్రమే సమాచార వనరుగా మారుతుంది. అటువంటి పరిస్థితులలో, అంకగణిత సగటు, ప్రామాణిక విచలనం మరియు క్వార్టైల్స్ వంటి పంపిణీ యొక్క పరిమాణాత్మక సూచికల యొక్క సుమారు విలువలను లెక్కించడం సాధ్యమవుతుంది.
నమూనా డేటా ఫ్రీక్వెన్సీ పంపిణీగా సూచించబడితే, ప్రతి తరగతిలోని అన్ని విలువలు తరగతి మధ్య బిందువు వద్ద కేంద్రీకృతమై ఉన్నాయని భావించడం ద్వారా అంకగణిత సగటు యొక్క ఉజ్జాయింపును లెక్కించవచ్చు:

ఎక్కడ - నమూనా సగటు, n- పరిశీలనల సంఖ్య, లేదా నమూనా పరిమాణం, తో- ఫ్రీక్వెన్సీ పంపిణీలో తరగతుల సంఖ్య, m j- మధ్య బిందువు జెవ తరగతి, fజె- ఫ్రీక్వెన్సీ సంబంధిత జె-వ తరగతి.
ఫ్రీక్వెన్సీ పంపిణీ నుండి ప్రామాణిక విచలనాన్ని లెక్కించడానికి, ప్రతి తరగతిలోని అన్ని విలువలు తరగతి మధ్య బిందువు వద్ద కేంద్రీకృతమై ఉన్నాయని కూడా భావించబడుతుంది.

పౌనఃపున్యాల ఆధారంగా శ్రేణి యొక్క క్వార్టైల్లు ఎలా నిర్ణయించబడతాయో అర్థం చేసుకోవడానికి, సగటు తలసరి ద్రవ్య ఆదాయం (Fig. 12) ద్వారా రష్యన్ జనాభా పంపిణీపై 2013కి సంబంధించిన డేటా ఆధారంగా తక్కువ క్వార్టైల్ యొక్క గణనను పరిగణించండి.

అన్నం. 12. నెలకు సగటు తలసరి నగదు ఆదాయంతో రష్యన్ జనాభా వాటా, రూబిళ్లు
విరామ వైవిధ్య శ్రేణి యొక్క మొదటి క్వార్టైల్ను లెక్కించడానికి, మీరు సూత్రాన్ని ఉపయోగించవచ్చు:

ఇక్కడ Q1 అనేది మొదటి త్రైమాసికం యొక్క విలువ, xQ1 అనేది మొదటి క్వార్టైల్ను కలిగి ఉన్న విరామం యొక్క దిగువ పరిమితి (విరామం మొదట 25% కంటే ఎక్కువ సంచిత పౌనఃపున్యం ద్వారా నిర్ణయించబడుతుంది); i - విరామం విలువ; Σf - మొత్తం నమూనా యొక్క ఫ్రీక్వెన్సీల మొత్తం; బహుశా ఎల్లప్పుడూ 100%కి సమానం; SQ1-1 - తక్కువ క్వార్టైల్ కలిగి ఉన్న విరామానికి ముందు విరామం యొక్క సంచిత ఫ్రీక్వెన్సీ; fQ1 - తక్కువ క్వార్టైల్ కలిగి ఉన్న విరామం యొక్క ఫ్రీక్వెన్సీ. మూడవ త్రైమాసికం యొక్క సూత్రం భిన్నంగా ఉంటుంది, అన్ని ప్రదేశాలలో మీరు Q1కి బదులుగా Q3ని ఉపయోగించాలి మరియు ¼కి బదులుగా ¾ని ప్రత్యామ్నాయం చేయాలి.
మా ఉదాహరణలో (Fig. 12), దిగువ క్వార్టైల్ 7000.1 - 10,000 పరిధిలో ఉంటుంది, దీని యొక్క సంచిత ఫ్రీక్వెన్సీ 26.4%. ఈ విరామం యొక్క దిగువ పరిమితి 7000 రూబిళ్లు, విరామం యొక్క విలువ 3000 రూబిళ్లు, తక్కువ క్వార్టైల్ను కలిగి ఉన్న విరామం కంటే ముందు ఉన్న విరామం యొక్క సంచిత ఫ్రీక్వెన్సీ 13.4%, తక్కువ క్వార్టైల్ను కలిగి ఉన్న విరామం యొక్క ఫ్రీక్వెన్సీ 13.0%. అందువలన: Q1 = 7000 + 3000 * (¼ * 100 - 13.4) / 13 = 9677 రబ్.
వివరణాత్మక గణాంకాలతో అనుబంధించబడిన ఆపదలు
ఈ పోస్ట్లో, డేటా సెట్ని దాని సగటు, వ్యాప్తి మరియు పంపిణీని అంచనా వేసే వివిధ గణాంకాలను ఉపయోగించి ఎలా వివరించాలో మేము చూశాము. తదుపరి దశ డేటా విశ్లేషణ మరియు వివరణ. ఇప్పటి వరకు, మేము డేటా యొక్క ఆబ్జెక్టివ్ లక్షణాలను అధ్యయనం చేసాము మరియు ఇప్పుడు మేము వారి ఆత్మాశ్రయ వివరణకు వెళ్తాము. పరిశోధకుడు రెండు తప్పులను ఎదుర్కొంటాడు: తప్పుగా ఎంచుకున్న విశ్లేషణ విషయం మరియు ఫలితాల యొక్క తప్పు వివరణ.
15 అధిక-రిస్క్ మ్యూచువల్ ఫండ్స్ యొక్క రాబడి యొక్క విశ్లేషణ చాలా నిష్పాక్షికమైనది. అతను పూర్తిగా ఆబ్జెక్టివ్ ముగింపులకు దారితీసాడు: అన్ని మ్యూచువల్ ఫండ్లు వేర్వేరు రాబడిని కలిగి ఉంటాయి, ఫండ్ రిటర్న్ల వ్యాప్తి -6.1 నుండి 18.5 వరకు ఉంటుంది మరియు సగటు రాబడి 6.08. పంపిణీ యొక్క సారాంశ పరిమాణాత్మక సూచికల సరైన ఎంపిక ద్వారా డేటా విశ్లేషణ యొక్క నిష్పాక్షికత నిర్ధారించబడుతుంది. డేటా యొక్క సగటు మరియు స్కాటర్ను అంచనా వేయడానికి అనేక పద్ధతులు పరిగణించబడ్డాయి మరియు వాటి ప్రయోజనాలు మరియు అప్రయోజనాలు సూచించబడ్డాయి. లక్ష్యం మరియు నిష్పాక్షిక విశ్లేషణను అందించడానికి మీరు సరైన గణాంకాలను ఎలా ఎంచుకుంటారు? డేటా పంపిణీ కొద్దిగా వక్రంగా ఉంటే, మీరు సగటు కంటే మధ్యస్థాన్ని ఎంచుకోవాలా? డేటా వ్యాప్తిని ఏ సూచిక మరింత ఖచ్చితంగా వర్ణిస్తుంది: ప్రామాణిక విచలనం లేదా పరిధి? పంపిణీ సానుకూలంగా వక్రంగా ఉందని మేము ఎత్తి చూపాలా?
మరోవైపు, డేటా ఇంటర్ప్రెటేషన్ అనేది ఆత్మాశ్రయ ప్రక్రియ. ఒకే ఫలితాలను వివరించేటప్పుడు వేర్వేరు వ్యక్తులు వేర్వేరు నిర్ధారణలకు వస్తారు. ప్రతి ఒక్కరికి వారి స్వంత దృక్కోణం ఉంటుంది. ఎవరైనా చాలా ఎక్కువ రిస్క్తో 15 ఫండ్ల మొత్తం సగటు వార్షిక రాబడిని మంచిగా భావిస్తారు మరియు అందుకున్న ఆదాయంతో చాలా సంతృప్తి చెందారు. ఈ ఫండ్స్ చాలా తక్కువ రాబడిని కలిగి ఉన్నాయని ఇతరులు భావించవచ్చు. అందువల్ల, ఆత్మాశ్రయత నిజాయితీ, తటస్థత మరియు ముగింపుల స్పష్టత ద్వారా భర్తీ చేయబడాలి.
నైతిక సమస్యలు
డేటా విశ్లేషణ నైతిక సమస్యలతో విడదీయరాని విధంగా ముడిపడి ఉంది. వార్తాపత్రికలు, రేడియో, టెలివిజన్ మరియు ఇంటర్నెట్ ద్వారా ప్రసారం చేయబడిన సమాచారాన్ని మీరు విమర్శించాలి. కాలక్రమేణా, మీరు ఫలితాలపై మాత్రమే కాకుండా, పరిశోధన యొక్క లక్ష్యాలు, విషయం మరియు నిష్పాక్షికతపై కూడా సందేహాస్పదంగా ఉండటం నేర్చుకుంటారు. ప్రసిద్ధ బ్రిటీష్ రాజకీయవేత్త బెంజమిన్ డిస్రేలీ ఇలా అన్నాడు: "మూడు రకాల అబద్ధాలు ఉన్నాయి: అబద్ధాలు, హేయమైన అబద్ధాలు మరియు గణాంకాలు."
నోట్లో పేర్కొన్నట్లుగా, నివేదికలో సమర్పించాల్సిన ఫలితాలను ఎంచుకునేటప్పుడు నైతిక సమస్యలు తలెత్తుతాయి. సానుకూల మరియు ప్రతికూల ఫలితాలు రెండూ ప్రచురించబడాలి. అదనంగా, నివేదిక లేదా వ్రాతపూర్వక నివేదికను రూపొందించేటప్పుడు, ఫలితాలను నిజాయితీగా, తటస్థంగా మరియు నిష్పాక్షికంగా సమర్పించాలి. విజయవంతం కాని మరియు నిజాయితీ లేని ప్రెజెంటేషన్ల మధ్య వ్యత్యాసం ఉంటుంది. దీన్ని చేయడానికి, స్పీకర్ యొక్క ఉద్దేశాలు ఏమిటో గుర్తించడం అవసరం. కొన్నిసార్లు స్పీకర్ అజ్ఞానం కారణంగా ముఖ్యమైన సమాచారాన్ని విస్మరిస్తాడు మరియు కొన్నిసార్లు అది ఉద్దేశపూర్వకంగా ఉంటుంది (ఉదాహరణకు, అతను ఆశించిన ఫలితాన్ని పొందడానికి స్పష్టంగా వక్రీకరించిన డేటా సగటును అంచనా వేయడానికి అంకగణిత సగటును ఉపయోగిస్తే). పరిశోధకుడి దృక్కోణానికి అనుగుణంగా లేని ఫలితాలను అణచివేయడం కూడా నిజాయితీ లేనిది.
లెవిన్ మరియు ఇతరులు పుస్తకంలోని మెటీరియల్లు. మేనేజర్ల కోసం గణాంకాలు ఉపయోగించబడతాయి. – M.: విలియమ్స్, 2004. – p. 178–209
Excel యొక్క మునుపటి సంస్కరణలతో అనుకూలత కోసం QUARTILE ఫంక్షన్ అలాగే ఉంచబడింది.