X$. За почеток, да се потсетиме на следнава дефиниција:
Дефиниција 1
Популација- збир на случајно избрани објекти од даден тип, над кои се вршат набљудувања за да се добијат специфични вредности на случајна променлива, извршени во постојани услови при проучување на една случајна променлива од даден тип.
Дефиниција 2
Општа варијанса- аритметичката средина на квадратните отстапувања на вредностите на популацијата варира од нивната средна вредност.
Нека вредностите на опцијата $x_1,\ x_2,\dots, x_k$ имаат, соодветно, фреквенции $n_1,\ n_2,\dots ,n_k$. Потоа, општата варијанса се пресметува со формулата:
Да разгледаме посебен случај. Сите опции $x_1,\ x_2,\dots, x_k$ нека бидат различни. Во овој случај $n_1,\ n_2,\dots ,n_k=1$. Откривме дека во овој случај општата варијанса се пресметува со помош на формулата:
Овој концепт е исто така поврзан со концептот на општо стандардно отстапување.
Дефиниција 3
Општо стандардно отстапување
\[(\sigma )_g=\sqrt(D_g)\]
Примерок варијанса
Дозволете ни да ни се даде примерок популација во однос на случајна променлива $X$. За почеток, да се потсетиме на следнава дефиниција:
Дефиниција 4
Популација на примерок-- дел од избрани објекти од општата популација.
Дефиниција 5
Примерок варијанса-- аритметичка средина на вредностите на популацијата на примерокот.
Нека вредностите на опцијата $x_1,\ x_2,\dots, x_k$ имаат, соодветно, фреквенции $n_1,\ n_2,\dots ,n_k$. Потоа варијансата на примерокот се пресметува со формулата:
Да разгледаме посебен случај. Сите опции $x_1,\ x_2,\dots, x_k$ нека бидат различни. Во овој случај $n_1,\ n_2,\dots ,n_k=1$. Откривме дека во овој случај варијансата на примерокот се пресметува со помош на формулата:
Исто така поврзан со овој концепт е концептот на стандардна девијација на примерокот.
Дефиниција 6
Примерок на стандардна девијација-- квадратен корен на општата варијанса:
\[(\sigma )_в=\sqrt(D_в)\]
Поправена варијанса
За да се најде коригираната варијанса $S^2$ потребно е да се помножи варијансата на примерокот со дропката $\frac(n)(n-1)$, т.е.
Овој концепт е исто така поврзан со концептот на коригирана стандардна девијација, која се наоѓа со формулата:
Во случај кога вредностите на варијантите не се дискретни, туку претставуваат интервали, тогаш во формулите за пресметување на општите или примерните варијанси, вредноста на $x_i$ се зема како вредност на средината на интервалот до кој $x_i.$ припаѓа.
Пример за проблем за наоѓање на варијансата и стандардното отстапување
Пример 1
Популацијата на примерокот е дефинирана со следната табела за дистрибуција:
Слика 1.
Дозволете ни да ја најдеме варијансата на примерокот, стандардната девијација на примерокот, коригирана варијанса и коригирана стандардна девијација.
За да го решиме овој проблем, прво правиме пресметковна табела:
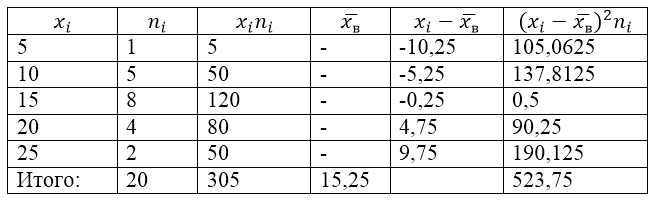
Слика 2.
Вредноста $\overline(x_в)$ (просек на примерок) во табелата се наоѓа со формулата:
\[\ overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\ overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Ајде да ја најдеме варијансата на примерокот користејќи ја формулата:
Примерок на стандардна девијација:
\[(\sigma )_в=\sqrt(D_в)\приближно 5,12\]
Поправена варијанса:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26.1875\приближно 27,57\]
Поправено стандардно отстапување.
Стандардна девијација(синоними: Стандардна девијација, Стандардна девијација, квадратна девијација; поврзани термини: Стандардна девијација, стандарден намаз) - во теоријата на веројатност и статистиката, најчестиот индикатор за дисперзија на вредностите на случајна променлива во однос на нејзиното математичко очекување. Со ограничени низи примероци на вредности, наместо математичкото очекување, се користи аритметичката средина на множеството примероци.
Енциклопедиски YouTube
-
1 / 5
Стандардното отстапување се мери во мерни единици на самата случајна променлива и се користи при пресметување на стандардната грешка на аритметичката средина, при конструирање интервали на доверба, при статистичко тестирање хипотези, при мерење на линеарната врска помеѓу случајните променливи. Дефиниран како квадратен корен на варијансата на случајна променлива.
Стандардна девијација:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\лево(x_(i)-(\бар (x))\десно)^(2)));)- Забелешка: Многу често има несовпаѓања во имињата на MSD (Root Mean Square Deviation) и STD (Standard Deviation) со нивните формули. На пример, во модулот numPy на програмскиот јазик Python, функцијата std() е опишана како „стандардна девијација“, додека формулата ја одразува стандардната девијација (поделба со коренот на примерокот). Во Excel, функцијата STANDARDEVAL() е различна (поделба со коренот на n-1).
Стандардна девијација(проценка на стандардното отстапување на случајна променлива xво однос на неговото математичко очекување засновано на непристрасна проценка на нејзината варијанса) s (\displaystyle s):
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\десно) ^ (2))))Каде σ 2 (\приказ стил \сигма ^(2))- дисперзија; x i (\displaystyle x_(i)) - јасти елемент од изборот; n (\displaystyle n)- големина на примерокот; - аритметичка средина на примерокот:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ldots +x_(n)).)Треба да се напомене дека и двете проценки се пристрасни. Во општиот случај, невозможно е да се изгради непристрасна проценка. Сепак, проценката заснована на непристрасна проценка на варијансата е конзистентна.
Во согласност со ГОСТ Р 8.736-2011, стандардното отстапување се пресметува со помош на втората формула од овој дел. Ве молиме проверете ги резултатите.
Правило три сигма
Правило три сигма (3 σ (\приказ стил 3\сигма)) - скоро сите вредности на нормално распределената случајна променлива лежат во интервалот (x ¯ − 3 σ ; x ¯ + 3 σ) (\дисплеј стил \лево((\лента (x))-3\сигма ;(\лента (x))+3\сигма \десно)). Построго - со приближна веројатност 0,9973, вредноста на нормално распределената случајна променлива лежи во наведениот интервал (под услов вредноста x ¯ (\приказ стил (\лента (x)))точно, а не се добиени како резултат на обработка на примерокот).
Ако вистинската вредност x ¯ (\приказ стил (\лента (x)))е непознат, тогаш не треба да го користите σ (\displaystyle \sigma), А с. Така, правилото на три сигма се трансформира во правило на три с .
Толкување на вредноста на стандардната девијација
Поголема стандардна вредност на отстапување покажува поголемо ширење на вредностите во презентираното множество со просечната вредност на множеството; помала вредност, соодветно, покажува дека вредностите во комплетот се групирани околу просечната вредност.
На пример, имаме три множества броеви: (0, 0, 14, 14), (0, 6, 8, 14) и (6, 6, 8, 8). Сите три сета имаат средни вредности еднакви на 7 и стандардни отстапувања, соодветно, еднакви на 7, 5 и 1. Последниот сет има мало стандардно отстапување, бидејќи вредностите во множеството се групирани околу средната вредност; првиот сет има најголема стандардна вредност на отстапување - вредностите во множеството значително се разликуваат од просечната вредност.
Во општа смисла, стандардното отстапување може да се смета за мерка на несигурност. На пример, во физиката, стандардното отстапување се користи за да се одреди грешката на серија последователни мерења на одредена количина. Оваа вредност е многу важна за одредување на веродостојноста на феноменот што се проучува во споредба со вредноста предвидена со теоријата: ако просечната вредност на мерењата во голема мера се разликува од вредностите предвидени од теоријата (големо стандардно отстапување), тогаш треба повторно да се проверат добиените вредности или начинот на нивно добивање. идентификувани со ризикот на портфолиото.
Климата
Да претпоставиме дека има два града со иста просечна максимална дневна температура, но едниот се наоѓа на брегот, а другиот на рамнината. Познато е дека градовите лоцирани на брегот имаат многу различни максимални дневни температури кои се пониски од градовите лоцирани во внатрешноста. Според тоа, стандардното отстапување на максималните дневни температури за еден крајбрежен град ќе биде помало отколку за вториот град, и покрај тоа што просечната вредност на оваа вредност е иста, што во пракса значи дека веројатноста максималната температура на воздухот на секој даден ден од годината ќе биде повисок за разлика од просечната вредност, повисок за град кој се наоѓа во внатрешноста.
Спорт
Да претпоставиме дека има неколку фудбалски тимови кои се оценети според одреден сет на параметри, на пример, бројот на постигнати и примени голови, шансите за постигнување гол, итн. Најверојатно е дека најдобриот тим во оваа група ќе има подобри вредности. на повеќе параметри. Колку е помало стандардното отстапување на тимот за секој од презентираните параметри, толку е попредвидлив резултатот на тимот; таквите тимови се избалансирани. Од друга страна, тим со големо стандардно отстапување е тешко да се предвиди резултатот, што пак се објаснува со нерамнотежа, на пример, силна одбрана, но слаб напад.
Користењето на стандардното отстапување на параметрите на тимот овозможува, до еден или друг степен, да се предвиди резултатот од натпреварот помеѓу два тима, проценувајќи ги силните и слабите страни на тимовите, а со тоа и избраните методи на борба.
Стандардна девијација
Најсовршената карактеристика на варијацијата е средната квадратна девијација, која се нарекува стандардна (или стандардна девијација). Стандардна девијација() е еднаков на квадратниот корен на просечното квадратно отстапување на поединечните вредности на атрибутот од аритметичката средина:
Стандардното отстапување е едноставно:


Пондерираната стандардна девијација се применува на групирани податоци:

Следниот сооднос се одвива помеѓу средните квадратни и средните линеарни отстапувања при нормални услови на дистрибуција: ~ 1,25.
Стандардната девијација, како главна апсолутна мерка за варијација, се користи при одредување на ординатни вредности на кривата на нормална дистрибуција, во пресметките поврзани со организацијата на набљудувањето на примерокот и утврдувањето на точноста на карактеристиките на примерокот, како и при проценката на граници на варијација на карактеристика во хомогена популација.
18. Варијанса, неговите типови, стандардна девијација.
Варијанса на случајна променлива- мерка за ширење на дадена случајна променлива, односно нејзино отстапување од математичкото очекување. Во статистиката, ознаката или често се користи. Квадратниот корен на варијансата обично се нарекува Стандардна девијација, Стандардна девијацијаили стандарден намаз.
Вкупна варијанса (σ 2) ја мери варијацијата на особина во целост под влијание на сите фактори кои ја предизвикале оваа варијација. Во исто време, благодарение на методот на групирање, можно е да се идентификуваат и измерат варијациите поради карактеристиките на групирање и варијациите што произлегуваат под влијание на неоткриени фактори.
Интергрупна варијанса (σ 2 m.gr) карактеризира систематска варијација, односно разлики во вредноста на проучуваната особина што произлегуваат под влијание на особината - факторот што ја формира основата на групата.
Стандардна девијација(синоними: Стандардна девијација, Стандардна девијација, квадратна девијација; поврзани термини: Стандардна девијација, стандарден намаз) - во теоријата на веројатност и статистиката, најчестиот индикатор за дисперзија на вредностите на случајна променлива во однос на нејзиното математичко очекување. Со ограничени низи примероци на вредности, наместо математичкото очекување, се користи аритметичката средина на множеството примероци.
Стандардното отстапување се мери во мерни единици на самата случајна променлива и се користи при пресметување на стандардната грешка на аритметичката средина, при конструирање интервали на доверба, при статистичко тестирање хипотези, при мерење на линеарната врска помеѓу случајните променливи. Дефиниран како квадратен корен на варијансата на случајна променлива.
Стандардна девијација:

Стандардна девијација(проценка на стандардното отстапување на случајна променлива xво однос на неговото математичко очекување врз основа на непристрасна проценка на неговата варијанса):

каде е дисперзијата; - јасти елемент од изборот; - големина на примерокот; - аритметичка средина на примерокот:

Треба да се напомене дека и двете проценки се пристрасни. Во општиот случај, невозможно е да се изгради непристрасна проценка. Во овој случај, проценката заснована на непристрасна проценка на варијансата е конзистентна.
19. Суштина, обем и постапка за определување на режим и медијана.
Покрај просеците на моќноста во статистиката, за релативна карактеризација на вредноста на различна карактеристика и внатрешната структура на дистрибутивните серии, се користат структурни просеци, кои се претставени главно со мода и медијана.
Мода- Ова е најчестата варијанта на серијата. Модата се користи, на пример, при одредување на големината на облеката и обувките кои се најбарани кај клиентите. Режимот за дискретна серија е варијантата со најголема фреквенција. При пресметување на режимот за серија на варијации на интервали, исклучително е важно прво да се одреди модалниот интервал (по максимална фреквенција), а потоа - вредноста на модалната вредност на атрибутот со помош на формулата:

§ - значење на модата
§ - долна граница на модалниот интервал
§ - вредност на интервалот
§ - фреквенција на модален интервал
§ - фреквенција на интервалот што му претходи на модалот
§ - фреквенција на интервалот што го следи модалот
средна -оваа вредност на атрибутот, ĸᴏᴛᴏᴩᴏᴇ лежи во основата на рангираната серија и ја дели оваа серија на два дела еднакви по број.
За да се одреди медијаната во дискретна серијаако се достапни фреквенции, прво пресметајте го полузбирот на фреквенциите, а потоа определете која вредност на варијантата паѓа на неа. (Ако сортираната серија содржи непарен број карактеристики, тогаш средниот број се пресметува со формулата:
M e = (n (вкупно број на карактеристики) + 1)/2,
во случај на парен број карактеристики, медијаната ќе биде еднаква на просекот од двете карактеристики во средината на редот).
При пресметување на медијаната за серии на интервални варијацииПрво, определете го средниот интервал во кој се наоѓа медијаната, а потоа одредете ја вредноста на медијаната користејќи ја формулата:

§ - потребната медијана
§ - долна граница на интервалот што ја содржи медијаната
§ - вредност на интервалот
§ - збир на фреквенции или број на сериски поими
§ - збирот на акумулираните фреквенции на интервалите кои претходат на медијаната
§ - фреквенција на средниот интервал
Пример. Најдете го режимот и медијаната.
Решение: Во овој пример, модалниот интервал е во возрасната група од 25-30 години, бидејќи овој интервал има најголема фреквенција (1054).
Ајде да ја пресметаме големината на режимот:
Тоа значи дека модалната возраст на учениците е 27 години.
Да ја пресметаме медијаната. Средниот интервал е во возрасната група од 25-30 години, бидејќи во овој интервал постои опција͵ која го дели населението на два еднакви дела (Σf i /2 = 3462/2 = 1731). Следно, ги заменуваме потребните нумерички податоци во формулата и ја добиваме средната вредност:

Тоа значи дека едната половина од учениците се помлади од 27,4 години, а другата половина се постари од 27,4 години.
Покрај режимот и медијаната, се користат индикатори како квартили, кои ја делат рангираната серија на 4 еднакви делови, децили - 10 делови и перцентили - на 100 делови.
20. Концептот на набљудување примерок и неговиот опсег.
Селективно набљудувањесе применува кога употребата на континуиран надзор физички невозможнопоради голема количина на податоци или не е економски изводливо. Физичка неможност се јавува, на пример, кога се проучуваат тековите на патниците, пазарните цени и семејните буџети. Економската нецелисходност се јавува при проценка на квалитетот на стоката поврзана со нивното уништување, на пример, дегустација, тестирање на тули за јачина итн.
Статистичките единици избрани за набљудување се примерок популацијаили примери целата нивна низа - општата популација(ГС). При што број на единици во примерокотозначуваат n, и во целиот ГШ - Н. Став n/Nобично се нарекува релативна големинаили примерок удел.
Квалитетот на резултатите од набљудувањето на примерокот зависи од репрезентативност на примерокот, односно за тоа колку е репрезентативен во ГШ. За да се обезбеди репрезентативност на примерокот, исклучително е важно да се усогласат принцип на случаен избор на единици, што претпоставува дека вклучувањето на единица HS во примерокот не може да биде под влијание на друг фактор освен случајноста.
Постои 4 начини на случаен изборза примерок:
- Всушност случајноизбор или „метод на лото“, кога на статистичките вредности им се доделуваат сериски броеви, се снимаат на одредени предмети (на пример, буриња), кои потоа се мешаат во контејнер (на пример, во кеса) и се избираат по случаен избор. Во пракса, овој метод се спроведува со помош на генератор на случаен број или математички табели со случајни броеви.
- Механичкиизбор според кој секој ( N/n)-та вредност на општата популација. На пример, ако содржи 100.000 вредности, а треба да изберете 1.000, тогаш секоја 100.000 / 1000 = 100-та вредност ќе биде вклучена во примерокот. Притоа, доколку не се рангирани, тогаш од првите сто се избира по случаен избор првиот, а бројот на останатите ќе биде за сто поголем. На пример, ако првата единица беше бр.19, тогаш следната треба да биде бр.119, па бр.219, па бр.319 итн. Ако се рангираат единиците на населението, тогаш прво се избира бр.50, па бр.150, па бр.250 итн.
- Се врши избор на вредности од хетерогена низа на податоци стратификуван(стратификуван) метод, кога населението прво се дели на хомогени групи на кои се применува случаен или механички избор.
- Посебен метод за земање примероци е серискиселекција, во која случајно или механички избираат не поединечни вредности, туку нивни серии (секвенци од некој број до некој број по ред), во рамките на кои се врши континуирано набљудување.
Квалитетот на набљудувањата на примерокот исто така зависи од тип на примерок: повториили неповторливи.На реизборСтатистичките вредности или нивните серии вклучени во примерокот се враќаат на општата популација по употребата, имајќи шанса да бидат вклучени во нов примерок. Покрај тоа, сите вредности во општата популација имаат иста веројатност за вклучување во примерокот. Селекција што не се повторувазначи дека статистичките вредности или нивните серии вклучени во примерокот не се враќаат во општата популација по употребата, и затоа за останатите вредности на второто се зголемува веројатноста да бидат вклучени во следниот примерок.
Неповторливото земање примероци дава попрецизни резултати и затоа се користи почесто. Но, постојат ситуации кога не може да се примени (проучување на тековите на патници, побарувачката на потрошувачите итн.) и потоа се врши повторена селекција.
21. Максимална грешка при земање мостри при набљудување, просечна грешка при земање примероци, постапка за нивна пресметка.
Да ги разгледаме детално методите наведени погоре за формирање на примерок од популација и грешките во репрезентативноста што се појавуваат. Правилно случајноземање примероци се заснова на избор на единици од популацијата по случаен избор без никакви систематски елементи. Технички, вистинскиот случаен избор се врши со ждрепка (на пример, лотарии) или со користење на табела со случајни броеви.
Правилната случаен избор „во својата чиста форма“ ретко се користи во практиката на селективно набљудување, но е првична меѓу другите видови на селекција, ги спроведува основните принципи на селективно набљудување. Да разгледаме некои прашања од теоријата на методот на земање примероци и формулата за грешка за едноставен случаен примерок.
Пристрасност за земање примероци- ϶ᴛᴏ разликата помеѓу вредноста на параметарот во општата популација и неговата вредност пресметана од резултатите од набљудувањето на примерокот. Важно е да се напомене дека за просечната квантитативна карактеристика грешката при земање мостри се одредува со
Индикаторот обично се нарекува максимална грешка при земање примероци. Средната вредност на примерокот е случајна променлива која може да добие различни вредности врз основа на тоа кои единици се вклучени во примерокот. Затоа, грешките при земање примероци се исто така случајни променливи и можат да добијат различни вредности. Поради оваа причина, се одредува просекот на можни грешки - просечна грешка при земање мостри, што зависи од:
· Големина на примерокот: колку е поголем бројот, толку е помала просечната грешка;
· степенот на промена на карактеристиката што се проучува: колку е помала варијацијата на карактеристиката и, следствено, дисперзијата, толку е помала просечната грешка при земање примероци.
На случаен повторен изборсе пресметува просечната грешка. Во практиката општата варијанса не е точно позната, но во теоријата на веројатност тоа е докажано
 . Бидејќи вредноста за доволно голем n е блиску до 1, можеме да претпоставиме дека . Тогаш треба да се пресмета просечната грешка при земање примероци: . Но, во случаи на мал примерок (со n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. Бидејќи вредноста за доволно голем n е блиску до 1, можеме да претпоставиме дека . Тогаш треба да се пресмета просечната грешка при земање примероци: . Но, во случаи на мал примерок (со n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.На случајно неповторливо земање примероцидадените формули се прилагодуваат со вредноста . Тогаш просечната грешка при земање примероци што не се повторува е:
 И
И  . Бидејќи е секогаш помал од , тогаш множителот () е секогаш помал од 1. Тоа значи дека просечната грешка со повторено избирање е секогаш помала отколку со повторено избирање. Механичко земање мострисе користи кога општата популација е на некој начин подредена (на пример, списоци на избирачи по азбучен ред, телефонски броеви, броеви на куќи и станови). Изборот на единици се врши на одреден интервал, што е еднакво на инверзната вредност на процентот на земање мостри. Значи, со примерок од 2%, се избираат секои 50 единици = 1/0,02, со примерок од 5%, секои 1/0,05 = 20 единици од општата популација.
. Бидејќи е секогаш помал од , тогаш множителот () е секогаш помал од 1. Тоа значи дека просечната грешка со повторено избирање е секогаш помала отколку со повторено избирање. Механичко земање мострисе користи кога општата популација е на некој начин подредена (на пример, списоци на избирачи по азбучен ред, телефонски броеви, броеви на куќи и станови). Изборот на единици се врши на одреден интервал, што е еднакво на инверзната вредност на процентот на земање мостри. Значи, со примерок од 2%, се избираат секои 50 единици = 1/0,02, со примерок од 5%, секои 1/0,05 = 20 единици од општата популација.Референтната точка се избира на различни начини: по случаен избор, од средината на интервалот, со промена на референтната точка. Главната работа е да се избегнат систематски грешки. На пример, со примерок од 5%, ако првата единица е 13-та, тогаш следните се 33, 53, 73 итн.
Во однос на точноста, механичката селекција е блиску до вистинското случајно земање примероци. Поради оваа причина, за да се одреди просечната грешка на механичкото земање примероци, се користат соодветни формули за случаен избор.
На типична селекцијанаселението што се истражува е прелиминарно поделено на хомогени, слични групи. На пример, кога се истражуваат претпријатијата, тоа се индустрии, потсектори; кога се проучува населението, тоа се региони, социјални или возрасни групи. Следно, независен избор од секоја група се прави механички или чисто случајно.
Типичното земање примероци дава попрецизни резултати од другите методи. Внесувањето на општата популација осигурува дека секоја типолошка група е претставена во примерокот, што овозможува да се елиминира влијанието на интергрупната варијанса врз просечната грешка при земање примероци. Затоа, при наоѓање на грешката на типичен примерок според правилото за додавање варијанси (), исклучително е важно да се земе предвид само просекот на групните варијанси. Потоа просечната грешка при земање примероци: со повторено земање примероци, со неповторливо земање примероци
 , Каде
, Каде  – просекот на варијансите во рамките на групата во примерокот.
– просекот на варијансите во рамките на групата во примерокот.Сериски (или гнездо) изборсе користи кога популацијата е поделена во серии или групи пред почетокот на истражувањето на примерокот. Овие серии вклучуваат пакување на готови производи, студентски групи и бригади. Сериите за испитување се избираат механички или чисто случајно, а во рамките на серијата се врши континуирано испитување на единиците. Поради оваа причина, просечната грешка при земање примероци зависи само од варијансата меѓу групите (меѓу сериите), која се пресметува со формулата:
 каде r е бројот на избраните серии; – просек од i-та серија. Просечната грешка на сериското земање примероци се пресметува: со повторено земање примероци, со неповторливо земање примероци
каде r е бројот на избраните серии; – просек од i-та серија. Просечната грешка на сериското земање примероци се пресметува: со повторено земање примероци, со неповторливо земање примероци  , каде што R е вкупниот број на серии. Комбинираниселекцијата е комбинација од разгледуваните методи на селекција.
, каде што R е вкупниот број на серии. Комбинираниселекцијата е комбинација од разгледуваните методи на селекција.Просечната грешка при земање мостри за кој било метод на земање мостри главно зависи од апсолутната големина на примерокот и, во помала мера, од процентот на примерокот. Да претпоставиме дека 225 набљудувања се направени во првиот случај од население од 4.500 единици и во вториот од население од 225.000 единици. Варијансите во двата случаи се еднакви на 25. Тогаш во првиот случај, со избор од 5%, грешката при земање примероци ќе биде:
 Во вториот случај, со 0,1% избор, ќе биде еднакво на:
Во вториот случај, со 0,1% избор, ќе биде еднакво на: Меѓутоа, кога процентот на земање примероци беше намален за 50 пати, грешката при земање мостри малку се зголеми, бидејќи големината на примерокот не се промени. Да претпоставиме дека големината на примерокот е зголемена на 625 набљудувања. Во овој случај, грешката при земање примероци е:
Меѓутоа, кога процентот на земање примероци беше намален за 50 пати, грешката при земање мостри малку се зголеми, бидејќи големината на примерокот не се промени. Да претпоставиме дека големината на примерокот е зголемена на 625 набљудувања. Во овој случај, грешката при земање примероци е:  Зголемувањето на примерокот за 2,8 пати со иста големина на популацијата ја намалува големината на грешката при земање примероци за повеќе од 1,6 пати.
Зголемувањето на примерокот за 2,8 пати со иста големина на популацијата ја намалува големината на грешката при земање примероци за повеќе од 1,6 пати.22.Методи и методи за формирање на примерок популација.
Во статистиката се користат различни методи за формирање на популации на примероци, што се одредува според целите на студијата и зависи од спецификите на предметот на проучување.
Главен услов за спроведување на примерок анкета е да се спречи појава на систематски грешки кои произлегуваат од прекршување на принципот на еднакви можности за секоја единица од општата популација да биде вклучена во примерокот. Спречувањето на систематските грешки се постигнува преку употреба на научно засновани методи за формирање на примерок од популација.
Постојат следниве методи за избор на единици од општата популација: 1) индивидуална селекција - за примерокот се избираат поединечни единици; 2) избор на група - примерокот вклучува квалитативно хомогени групи или серии на единици кои се проучуваат; 3) комбинираната селекција е комбинација на индивидуална и групна селекција. Методите на селекција се одредуваат со правилата за формирање на примерок популација.
Примерокот треба да биде:
- всушност случајносе состои во тоа што популацијата на примерокот е формирана како резултат на случаен (ненамерен) избор на поединечни единици од општата популација. Во овој случај, бројот на избрани единици во популацијата на примерокот обично се одредува врз основа на прифатената пропорција на примерокот. Пропорцијата на примерокот е односот на бројот на единици во примерокот популација n до бројот на единици во општата популација N, ᴛ.ᴇ.
- механичкисе состои во тоа што изборот на единици во популацијата на примерокот е направен од општата популација, поделена на еднакви интервали (групи). Во овој случај, големината на интервалот во популацијата е еднаква на реципрочното учество на примерокот. Значи, со примерок од 2% се избира секоја 50-та единица (1:0,02), со примерок од 5%, секоја 20-та единица (1:0,05) итн. Меѓутоа, во согласност со прифатената пропорција на селекција, општата популација е, како што беше, механички поделена на еднакви групи. Од секоја група се избира само една единица за примерокот.
- типично -во кои општата популација прво се дели на хомогени типични групи. Следно, од секоја типична група, чисто случаен или механички примерок се користи за поединечно избирање единици во популацијата на примерокот. Важна карактеристика на типичен примерок е тоа што дава попрецизни резултати во споредба со другите методи за избор на единици во популацијата на примерокот;
- сериски- во која општата популација е поделена на групи со еднаква големина - серии. Сериите се избрани во популацијата на примерокот. Во рамките на серијата се врши континуирано набљудување на единиците вклучени во серијата;
- комбинирано- земање мостри треба да биде двостепено. Во овој случај, населението прво се дели во групи. Следно, се избираат групи, а во рамките на вторите се избираат поединечни единици.
Во статистиката, се разликуваат следниве методи за избор на единици во примерок од популација:
- единечна фазаземање примероци - секоја избрана единица веднаш се подложува на проучување според даден критериум (правилно случајно и сериско земање примероци);
- повеќестепенземање примероци - се врши избор од општата популација на поединечни групи, а поединечните единици се избираат од групите (типично земање примероци со механички метод за избор на единици во популацијата на примерокот).
Покрај тоа, постојат:
- реизбор- според шемата на вратената топка. Во овој случај, секоја единица или серија вклучени во примерокот се враќаат на општата популација и затоа има шанса повторно да биде вклучена во примерокот;
- повторете го изборот- според шемата за невратена топка. Има попрецизни резултати со иста големина на примерокот.
23. Определување на исклучително важната големина на примерокот (со користење на Студентската t-табела).
Еден од научните принципи во теоријата за земање примероци е да се осигура дека се избрани доволен број единици. Теоретски, екстремната важност на набљудувањето на овој принцип е претставена во доказите за граничните теореми во теоријата на веројатност, кои овозможуваат да се утврди колкав волумен на единици треба да се избере од популацијата за да биде доволен и да обезбеди репрезентативност на примерокот.
Намалувањето на стандардната грешка при земање примероци, а со тоа и зголемувањето на точноста на проценката, секогаш е поврзано со зголемување на големината на примерокот; затоа, веќе во фазата на организирање на набљудување примерок, неопходно е да се одлучи која е големината од популацијата на примерокот треба да биде со цел да се обезбеди потребната точност на резултатите од набљудувањето. Пресметката на исклучително важниот волумен на примерокот се конструира со користење на формули добиени од формулите за максималните грешки при земање примероци (А), што одговараат на одреден тип и метод на селекција. Значи, за случајна повторена големина на примерокот (n) имаме:

Суштината на оваа формула е дека со случајно повторено земање примероци од исклучително важни броеви, големината на примерокот е директно пропорционална со квадратот на коефициентот на доверба (t2)и варијанса на варијациската карактеристика (?2) и е обратно пропорционална на квадратот на максималната грешка при земање примероци (?2). Особено, со зголемување на максималната грешка за фактор два, потребната големина на примерокот треба да се намали за фактор четири. Од трите параметри, два (t и?) се поставени од истражувачот. Во исто време, истражувачот, врз основа на целта
а проблемите на примерок анкета мора да го решат прашањето: во која квантитативна комбинација е подобро да се вклучат овие параметри за да се обезбеди оптимална опција? Во еден случај, тој може да биде позадоволен од веродостојноста на добиените резултати (t) отколку од мерката за точност (?), во друг - обратно. Потешко е да се реши прашањето во врска со вредноста на максималната грешка при земање примероци, бидејќи истражувачот го нема овој индикатор во фазата на дизајнирање на набљудувањето на примерокот; затоа, во пракса вообичаено е да се постави вредноста на максималната грешка при земање примероци , обично во рамките на 10% од очекуваното просечно ниво на атрибутот . Кон утврдувањето на проценетиот просек може да се пристапи на различни начини: користење податоци од слични претходни истражувања или користење податоци од рамката за земање примероци и спроведување на мал пилот примерок.
Најтешкото нешто што се утврдува при дизајнирање на набљудување на примерокот е третиот параметар во формулата (5.2) - варијансата на популацијата на примерокот. Во овој случај, исклучително е важно да се искористат сите информации што му се достапни на истражувачот, добиени во претходни слични и пилот анкети.
Прашањето за одредување на исклучително важната големина на примерокот станува покомплицирано ако анкетата на примерокот вклучува проучување на неколку карактеристики на единиците за примерок. Во овој случај, просечните нивоа на секоја од карактеристиките и нивната варијација, по правило, се различни, и во овој поглед, одлучувањето на која варијанса на која од карактеристиките да се даде предност е можно само земајќи ги предвид целта и целите. на анкетата.
При дизајнирање на набљудување примерок, се претпоставува однапред одредена вредност на дозволената грешка при земање мостри во согласност со целите на одредена студија и веројатноста за заклучоци врз основа на резултатите од набљудувањето.
Генерално, формулата за максимална грешка на просекот на примерокот ни овозможува да одредиме:
‣‣‣ големината на можните отстапувања на индикаторите на општата популација од индикаторите на популацијата на примерокот;
‣‣‣ потребната големина на примерокот за да се обезбеди потребната точност, при која границите на можна грешка не надминуваат одредена одредена вредност;
‣‣‣ веројатноста дека грешката во примерокот ќе има одредена граница.
Студентска распределбаво теоријата на веројатност, тоа е еднопараметарско семејство на апсолутно континуирани распределби.
24. Динамична серија (интервал, момент), динамична серија за затворање.
Динамика серија- ова се вредностите на статистичките показатели кои се прикажани во одредена хронолошка низа.
Секоја временска серија содржи две компоненти:
1) индикатори за временски периоди(години, четвртини, месеци, денови или датуми);
2) индикатори кои го карактеризираат предметот што се проучуваза временски периоди или на соодветни датуми, кои се нарекуваат сериски нивоа.
Нивоата на сериите се изразуваат и во апсолутни и во просечни или релативни вредности. Земајќи ја предвид зависноста од природата на индикаторите, се градат динамични серии на апсолутни, релативни и просечни вредности. Динамичните серии на релативни и просечни вредности се конструирани врз основа на изведени серии на апсолутни вредности. Постојат интервални и моментални серии на динамика.
Динамична интервал серијаги содржи вредностите на индикаторите за одредени временски периоди. Во интервалните серии, нивоата може да се сумираат за да се добие обемот на феноменот во подолг период, или таканаречените акумулирани збирки.
Динамична моментна серијаги одразува вредностите на индикаторите во одреден временски момент (датум на време). Во моменталните серии, истражувачот може да биде заинтересиран само за разликата во појавите што ја одразуваат промената на нивото на серијата помеѓу одредени датуми, бидејќи збирот на нивоата овде нема вистинска содржина. Кумулативните вкупни суми не се пресметуваат овде.
Најважен услов за правилна конструкција на временските серии е споредливост на сериските нивоакои припаѓаат на различни периоди. Нивоата мора да бидат претставени во хомогени количини и мора да има еднаква комплетност на опфатот на различни делови од феноменот.
За да се избегне нарушување на реалната динамика, во статистичкото истражување се вршат прелиминарни пресметки (затворање на динамичката серија), кои претходат на статистичката анализа на временските серии. Под затворање на серијата на динамикаОпшто е прифатено да се разбере комбинацијата во една серија од две или повеќе серии, чии нивоа се пресметуваат со различна методологија или не одговараат на територијалните граници итн. Затворањето на динамичките серии може да значи и доведување на апсолутните нивоа на динамичката серија на заедничка основа, што ја неутрализира неспоредливоста на нивоата на динамичките серии.
25. Концептот на споредливост на динамички серии, коефициенти, раст и стапки на раст.
Динамика серија- ова се низа статистички показатели кои го карактеризираат развојот на природните и општествените појави со текот на времето. Статистичките збирки објавени од Државниот комитет за статистика на Русија содржат голем број динамички серии во табеларна форма. Динамичките серии овозможуваат да се идентификуваат моделите на развој на феномените што се проучуваат.
Серијата Dynamics содржи два вида индикатори. Временски индикатори(години, квартали, месеци итн.) или временски точки (на почетокот на годината, на почетокот на секој месец итн.). Индикатори за ниво на ред. Индикаторите на нивоата на сериите на динамика може да се изразат во апсолутни вредности (производство на производи во тони или рубли), релативни вредности (удел на урбаното население во %) и просечни вредности (просечна плата на работниците во индустријата по година итн.). Во табеларна форма, временската серија содржи две колони или два реда.
Правилната конструкција на временските серии бара исполнување на голем број барања:
- сите показатели за голем број динамики мора да бидат научно поткрепени и сигурни;
- индикаторите за низа динамики мора да бидат споредливи со текот на времето, ᴛ.ᴇ. мора да се пресметаат за истите временски периоди или на истите датуми;
- индикаторите за голем број динамики мора да бидат споредливи низ целата територија;
- индикаторите за низа динамики мора да бидат споредливи по содржина, ᴛ.ᴇ. пресметано според единствена методологија, на ист начин;
- индикаторите за одреден број динамики треба да бидат споредливи низ опсегот на фарми земени предвид. Сите показатели за низа динамика мора да бидат дадени во исти мерни единици.
Статистичките показатели можат да ги карактеризираат или резултатите од процесот што се проучува во одреден временски период, или состојбата на феноменот што се проучува во одреден временски период, ᴛ.ᴇ. индикаторите можат да бидат интервални (периодични) и моментални. Според тоа, првично сериите на динамиката се или интервал или момент. Сериите за динамика на моментот, пак, доаѓаат со еднакви и нееднакви временски интервали.
Оригиналната динамичка серија може да се трансформира во низа просечни вредности и низа релативни вредности (синџир и основни). Таквите временски серии се нарекуваат изведени временски серии.
Методологијата за пресметување на просечното ниво во динамичката серија е различна, во зависност од видот на динамичката серија. Користејќи примери, ќе ги разгледаме видовите динамички серии и формули за пресметување на просечното ниво.
Апсолутни зголемувања (Δy) покаже колку единици е променето следното ниво на серијата во однос на претходното (гр. 3. - синџирно апсолутни зголемувања) или во споредба со почетното ниво (гр. 4. - основни апсолутни зголемувања). Формулите за пресметка може да се напишат на следниов начин:

Кога апсолутните вредности на серијата се намалуваат, ќе има „намалување“ или „намалување“, соодветно.
Апсолутните показатели за раст укажуваат дека, на пример, во 1998 г. производството на производот „А“ е зголемено во однос на 1997 година. за 4 илјади тони, а во споредба со 1994 година ᴦ. - за 34 илјади тони; за други години, видете ја табелата. 11,5 гр.
Објавено на ref.rf
3 и 4.Стапка на растпокажува колку пати нивото на серијата е променето во однос на претходното (гр. 5 - верижни коефициенти на раст или пад) или во споредба со почетното ниво (гр. 6 - основни коефициенти на раст или пад). Формулите за пресметка може да се напишат на следниов начин:

Стапки на растпокажете колкав процент е следното ниво од серијата споредено со претходното (колона 7 - стапки на раст на синџирот) или во споредба со почетното ниво (гр. 8 - основни стапки на раст). Формулите за пресметка може да се напишат на следниов начин:

Така, на пример, во 1997 г. обем на производство на производот „А“ во споредба со 1996 година ᴦ. изнесуваше 105,5% (
Стапка на растпокажете за колкав процент е зголемено нивото на извештајниот период во однос на претходниот (колона 9 - стапки на раст на синџирот) или во однос на почетното ниво (колона 10 - основни стапки на раст). Формулите за пресметка може да се напишат на следниов начин:
T pr = T r - 100% или T pr = апсолутен раст / ниво од претходниот период * 100%
Така, на пример, во 1996 г. во споредба со 1995 година ᴦ. Производот „А“ е произведен повеќе за 3,8% (103,8% - 100%) или (8:210) x 100%, а во споредба со 1994 година ᴦ. - за 9% (109% - 100%).
Ако апсолутните нивоа во серијата се намалат, тогаш стапката ќе биде помала од 100% и, соодветно, ќе има стапка на намалување (стапката на зголемување со знак минус).
Апсолутна вредност од 1% зголемување(гр.
Објавено на ref.rf
11) покажува колку единици треба да се произведат во даден период за да се зголеми нивото од претходниот период за 1%. Во нашиот пример, во 1995 година ᴦ. беше потребно да се произведат 2,0 илјади тони, а во 1998 година ᴦ. - 2,3 илјади тони, ᴛ.ᴇ. многу поголем.Апсолутната вредност на растот од 1% може да се одреди на два начина:
§ нивото од претходниот период поделено со 100;
§ апсолутните зголемувања на синџирот се поделени со соодветните стапки на раст на синџирот.
Апсолутна вредност од 1% зголемување =

Во динамиката, особено во подолг период, важна е заедничка анализа на стапката на раст со содржината на секој процент на зголемување или намалување.
Имајте предвид дека разгледаната методологија за анализа на временски серии е применлива и за временски серии, чии нивоа се изразени во апсолутни вредности (т, илјади рубли, број на вработени итн.), така и за временски серии, чии нивоа се изразени во релативни показатели (% од дефекти, % содржина на пепел на јаглен итн.) или просечни вредности (просечен принос во c/ha, просечна плата итн.).
Заедно со разгледуваните аналитички показатели, пресметани за секоја година во споредба со претходното или почетното ниво, кога се анализираат сериите на динамика, исклучително е важно да се пресметаат просечните аналитички показатели за периодот: просечното ниво на серијата, просечната годишна апсолутна зголемување (намалување) и просечна годишна стапка на раст и стапка на раст .
Методите за пресметување на просечното ниво на серија динамики беа дискутирани погоре. Во серијата за динамика на интервал што ја разгледуваме, просечното ниво на серијата се пресметува со помош на едноставната аритметичка средна формула:
Просечен годишен обем на производство на производот за 1994-1998 година. изнесуваше 218,4 илјади тони.
Просечниот годишен апсолутен раст исто така се пресметува со аритметичка средна формула
Стандардна девијација - концепт и типови. Класификација и карактеристики на категоријата „Средно отстапување на квадрат“ 2017, 2018 година.
Лекција бр. 4
Тема: „Описна статистика. Индикатори за разновидност на особини во агрегат“
Главните критериуми за различноста на една карактеристика во статистичката популација се: граница, амплитуда, стандардна девијација, коефициент на осцилација и коефициент на варијација. Во претходната лекција, беше дискутирано дека просечните вредности обезбедуваат само генерализирана карактеристика на карактеристиката што се проучува збирно и не ги земаат предвид вредностите на нејзините поединечни варијанти: минимални и максимални вредности, над просекот, под просек, итн.
Пример. Просечни вредности на две различни секвенци на броеви: -100; -20; 100; 20 и 0,1; -0,2; 0,1 се апсолутно идентични и еднаквиЗА.Сепак, опсегот на расејување на овие податоци за релативна средна низа се многу различни.
Утврдувањето на наведените критериуми за различноста на една карактеристика првенствено се врши земајќи ја предвид нејзината вредност во поединечни елементи од статистичката популација.
Индикатори за мерење на варијација на особина се апсолутнаИ роднина. Апсолутни индикатори на варијација вклучуваат: опсег на варијација, граница, стандардна девијација, дисперзија. Коефициентот на варијација и коефициентот на осцилација се однесуваат на релативни мерки на варијација.
Ограничување (Lim) -Ова е критериум што се определува со екстремните вредности на варијанта во серија на варијации. Со други зборови, овој критериум е ограничен со минималните и максималните вредности на атрибутот:
Амплитуда (Ам)или опсег на варијации -Ова е разликата помеѓу екстремните опции. Пресметката на овој критериум се врши со одземање на нејзината минимална вредност од максималната вредност на атрибутот, што ни овозможува да го процениме степенот на расејување на опцијата:
Недостаток на границата и амплитудата како критериуми за варијабилност е тоа што тие целосно зависат од екстремните вредности на карактеристиката во серијата на варијации. Во овој случај, флуктуациите во вредностите на атрибутите во рамките на серија не се земаат предвид.
Најкомплетниот опис на различноста на особина во статистичката популација е даден со Стандардна девијација(сигма), што е општа мерка за отстапувањето на опцијата од нејзината просечна вредност. Стандардна девијација често се нарекува Стандардна девијација.
Стандардната девијација се заснова на споредба на секоја опција со аритметичката средина на дадена популација. Бидејќи во агрегатот секогаш ќе има опции и помалку и повеќе од него, збирот на отстапувања со знакот "" ќе се поништи со збирот на отстапувања со знакот "", т.е. збирот на сите отстапувања е нула. За да се избегне влијанието на знаците на разликите се земаат отстапувања од аритметичката средина на квадрат, т.е. . Збирот на квадратните отстапувања не е еднаков на нула. За да се добие коефициент кој може да ја измери варијабилноста, земете го просекот од збирот на квадратите - оваа вредност се нарекува варијанси:

Во суштина, дисперзијата е просечен квадрат на отстапувања на поединечни вредности на карактеристика од нејзината просечна вредност. Дисперзија – квадрат на стандардната девијација.
Варијансата е димензионална величина (именувана). Значи, ако варијантите на бројна серија се изразени во метри, тогаш варијансата дава квадратни метри; ако опциите се изразени во килограми, тогаш варијансата го дава квадратот на оваа мерка (kg 2) итн.
Стандардна девијација- квадратен корен на варијанса:
, тогаш при пресметување на дисперзијата и стандардното отстапување во именителот на дропката, наместомора да се стави.
Пресметката на стандардното отстапување може да се подели во шест фази, кои мора да се извршат во одредена секвенца:
Примена на стандардна девијација:
а) за оценување на варијабилноста на варијационите серии и компаративна проценка на типичноста (репрезентативноста) на аритметичките просеци. Ова е неопходно при диференцијалната дијагноза при одредување на стабилноста на симптомите.
б) да се реконструира варијациската серија, т.е. реставрација на неговиот фреквентен одговор врз основа на три сигма правила. Во интервалот (М±3σ) 99,7% од сите варијанти на серијата се наоѓаат во интервалот (М±2σ) - 95,5% и во опсегот (М±1σ) - 68,3% варијанта на ред(сл. 1).
в) да се идентификуваат „појавните“ опции
г) да се утврдат параметрите на нормата и патологијата користејќи проценки на сигма
д) да се пресмета коефициентот на варијација
ѓ) да се пресмета просечната грешка на аритметичката средина.
Да се карактеризира секоја популација која иманормален тип на дистрибуција , доволно е да се знаат два параметри: аритметичката средина и стандардното отстапување.

Слика 1. Три сигма правило
Пример.
Во педијатријата, стандардното отстапување се користи за да се процени физичкиот развој на децата со споредување на податоците за одредено дете со соодветните стандардни индикатори. Како стандард се зема аритметичкиот просек на физичкиот развој на здравите деца. Споредбата на индикаторите со стандардите се врши со помош на специјални табели во кои се дадени стандардите заедно со нивните соодветни сигма скали. Се верува дека ако индикаторот за физичкиот развој на детето е во рамките на стандардот (аритметичка средина) ±σ, тогаш физичкиот развој на детето (според овој индикатор) одговара на нормата. Ако индикаторот е во рамките на стандардот ±2σ, тогаш има мало отстапување од нормата. Ако индикаторот оди подалеку од овие граници, тогаш физичкиот развој на детето остро се разликува од нормата (можна е патологија).
Покрај индикаторите за варијација изразени во апсолутни вредности, статистичкото истражување користи индикатори за варијација изразени во релативни вредности. Коефициент на осцилација -ова е односот на опсегот на варијација со просечната вредност на особината. Коефициентот на варијација -ова е односот на стандардното отстапување со просечната вредност на карактеристиката. Обично, овие вредности се изразуваат во проценти.
Формули за пресметување на индикатори за релативна варијација:
Од горенаведените формули е јасно дека колку е поголем коефициентот В е поблиску до нула, толку е помала варијацијата во вредностите на карактеристиката. Повеќе В, толку е попроменлив знакот.
Во статистичката практика најчесто се користи коефициентот на варијација. Се користи не само за компаративна проценка на варијациите, туку и за карактеризирање на хомогеноста на популацијата. Популацијата се смета за хомогена ако коефициентот на варијација не надминува 33% (за распределби блиску до нормалата). Аритметички, односот на σ и аритметичката средина го неутрализира влијанието на апсолутната вредност на овие карактеристики, а процентуалниот однос го прави коефициентот на варијација бездимензионална (неименувана) вредност.
Резултирачката вредност на коефициентот на варијација се проценува во согласност со приближните градации на степенот на разновидност на особината:
Слаб - до 10%
Просечно - 10 - 20%
Силен - повеќе од 20%
Употребата на коефициентот на варијација е препорачлива во случаи кога е неопходно да се споредат карактеристиките кои се различни по големина и димензија.
Разликата помеѓу коефициентот на варијација и другите критериуми за расејување е јасно прикажана пример.
Табела 1
Состав на работници на индустриски претпријатија
Врз основа на статистичките карактеристики дадени во примерот, можеме да извлечеме заклучок за релативната хомогеност на старосниот состав и образовното ниво на вработените во претпријатието, со оглед на ниската професионална стабилност на испитуваниот контингент. Лесно е да се види дека обидот да се процени овие општествени трендови според стандардната девијација би довел до погрешен заклучок, а обидот да се споредат сметководствените карактеристики „работно искуство“ и „возраст“ со сметководствениот индикатор „образование“ генерално би бил неточни поради хетерогеноста на овие карактеристики.
Медијана и перцентили
За редни (ранги) распределби, каде што критериумот за средината на серијата е медијаната, стандардната девијација и дисперзија не можат да послужат како карактеристики на дисперзијата на варијантата.
Истото важи и за сериите со отворени варијации. Оваа околност се должи на фактот што отстапувањата од кои се пресметуваат варијансата и σ се мерат од аритметичката средина, која не се пресметува во отворени варијациони серии и во серии распределби на квалитативни карактеристики. Затоа, за компресиран опис на дистрибуциите, се користи друг параметар на расејување - квантил(синоним - „процентил“), погоден за опишување на квалитативни и квантитативни карактеристики во која било форма на нивната дистрибуција. Овој параметар може да се користи и за претворање на квантитативните карактеристики во квалитативни. Во овој случај, таквите оценки се доделуваат во зависност од кој редослед на квантили одговара одредена опција.
Во практиката на биомедицинско истражување, најчесто се користат следниве квантили:
– медијана;
, – квартили (четвртини), каде – долен квартил, – горниот квартал.
Квантилите ја делат областа на можни промени во серија на варијации во одредени интервали. Медијана (квантил) е опција која се наоѓа во средината на серија на варијации и ја дели оваа серија на половина на два еднакви делови ( 0,5 И 0,5 ). Квартил ја дели серијата на четири дела: првиот дел (долниот квартал) е опција што ги раздвојува опциите чии нумерички вредности не надминуваат 25% од максимално можно во дадена серија; квартил ги раздвојува опциите со нумеричка вредност од до 50% од максималното можно. Горниот квартал () ги одвојува опциите до 75% од максималните можни вредности.
Во случај на асиметрична распределба променлива во однос на аритметичката средина, медијаната и квартилите се користат за да се карактеризира.Во овој случај, се користи следната форма за прикажување на просечната вредност - Мех (;). На пример, проучуваната карактеристика – „периодот во кој детето почнало самостојно да оди“ – има асиметрична дистрибуција во студиската група. Во исто време, долниот квартал () одговара на почетокот на одење - 9,5 месеци, средната - 11 месеци, горниот квартал () - 12 месеци. Според тоа, карактеристиката на просечниот тренд на наведениот атрибут ќе биде претставена како 11 (9,5; 12) месеци.
Проценка на статистичката значајност на резултатите од студијата
Статистичката значајност на податоците се подразбира како степен до кој тие одговараат на прикажаната реалност, т.е. статистички значајни податоци се оние кои не ја искривуваат и правилно ја одразуваат објективната реалност.
Оценувањето на статистичката значајност на резултатите од истражувањето значи да се утврди со која веројатност е можно да се пренесат резултатите добиени од популацијата на примерокот на целата популација. Проценката на статистичката значајност е неопходна за да се разбере колку феномен може да се искористи за да се процени феноменот како целина и неговите модели.
Оценката на статистичката значајност на резултатите од истражувањето се состои од:
1. грешки на репрезентативност (грешки на просечни и релативни вредности) - м;
2. граници на доверба на просечни или релативни вредности;
3. веродостојност на разликата во просечните или релативните вредности според критериумот т.
Стандардна грешка на аритметичката срединаили репрезентативна грешкаги карактеризира флуктуациите на просекот. Треба да се напомене дека колку е поголема големината на примерокот, толку е помало ширењето на просечните вредности. Стандардната грешка на средната вредност се пресметува со формулата:
Во современата научна литература, аритметичката средина се пишува заедно со грешката на репрезентативноста:
или заедно со стандардната девијација:
Како пример, земете ги податоците за 1.500 градски клиники во земјата (општа популација). Просечниот број на опслужени пациенти на клиниката е 18.150 лица. Случаен избор на 10% од локациите (150 клиники) дава просечен број на пациенти еднаков на 20.051 лице. Грешката при земање примероци, очигледно поради фактот што не беа вклучени сите 1500 клиники во примерокот, е еднаква на разликата помеѓу овие просеци - општиот просек ( Мген) и средна вредност на примерокот ( Мизбрани). Ако формираме друг примерок со иста големина од нашата популација, тој ќе даде различна вредност на грешката. Сите овие примероци средства, со доволно големи примероци, се распоредени нормално околу општата средина со доволно голем број повторувања на примерокот од ист број предмети од општата популација. Стандардна грешка на средната вредност м- ова е неизбежното ширење на примерок средства околу општата средина.
Во случај кога резултатите од истражувањето се претставени во релативни количини (на пример, проценти) - пресметано стандардна грешка на дропка:

каде што P е индикаторот во %, n е бројот на набљудувања.
Резултатот се прикажува како (P ± m)%. На пример,процентот на опоравување кај пациентите беше (95,2±2,5)%.
Во случај бројот на елементи од населението, тогаш при пресметување на стандардните грешки на средната и дропката во именителот на дропката, наместомора да се стави.
За нормална дистрибуција (распределбата на средини на примерокот е нормална), знаеме кој дел од популацијата спаѓа во кој било интервал околу средната вредност. Особено:
Практично, проблемот е што карактеристиките на општата популација ни се непознати, а примерокот е направен токму заради нивна проценка. Тоа значи дека ако направиме примероци со иста големина nод општата популација, тогаш во 68,3% од случаите интервалот ќе ја содржи вредноста М(во 95,5% од случаите ќе биде на интервал и во 99,7% од случаите - на интервал).
Бидејќи всушност е земен само еден примерок, оваа изјава е формулирана во смисла на веројатност: со веројатност од 68,3%, просечната вредност на атрибутот во популацијата лежи во интервалот, со веројатност од 95,5% - во интервалот итн.
Во пракса, се гради интервал околу вредноста на примерокот така што, со дадена (доволно висока) веројатност, веројатност за доверба -би ја „покриле“ вистинската вредност на овој параметар кај општата популација. Овој интервал се нарекува интервал на доверба.
Веројатност за довербаП – ова е степенот на доверба дека интервалот на доверба всушност ќе ја содржи вистинската (непозната) вредност на параметарот во популацијата.
На пример, ако веројатноста за доверба Ре 90%, тоа значи дека 90 примероци од 100 ќе дадат точна проценка на параметарот во популацијата. Според тоа, веројатноста за грешка, т.е. неточна проценка на општиот просек за примерокот е еднаква во проценти: . За овој пример, тоа значи дека 10 примероци од 100 ќе дадат погрешна проценка.
Очигледно, степенот на доверба (веројатност на доверба) зависи од големината на интервалот: колку е поширок интервалот, толку е поголема довербата дека непозната вредност за населението ќе падне во него. Во пракса, најмалку двојно поголема грешка при земање примероци се користи за да се изгради интервал на доверба за да се обезбеди најмалку 95,5% доверба.
Утврдувањето на границите на доверливост на просеците и релативните вредности ни овозможува да ги најдеме нивните две екстремни вредности - минималната можна и максималната можна, во рамките на кои проучуваниот индикатор може да се појави кај целата популација. Врз основа на ова, граници на доверба (или интервал на доверба)- тоа се границите на просечните или релативните вредности, над кои поради случајни флуктуации постои незначителна веројатност.
Интервалот на доверба може да се преработи како: , каде т– критериум за доверба.
Границите на довербата на аритметичката средина во популацијата се одредуваат со формулата:
М ген = М изберете + т м М
за релативна вредност:
Р ген = П изберете + т м Р
Каде М генИ Р ген- вредности на просечни и релативни вредности за општата популација; М изберетеИ Р изберете- вредности на просечни и релативни вредности добиени од популацијата на примерокот; м МИ м П- грешки на просечни и релативни вредности; т- критериум за доверба (критериум за точност, кој се утврдува при планирањето на студијата и може да биде еднаков на 2 или 3); т м- ова е интервал на доверба или Δ - максималната грешка на индикаторот добиена во примерок студија.
Треба да се напомене дека вредноста на критериумот тдо одреден степен поврзан со веројатноста за прогноза без грешки (p), изразена во %. Го избира самиот истражувач, водејќи се од потребата да се добие резултатот со потребниот степен на точност. Така, за веројатноста за прогноза без грешки од 95,5%, вредноста на критериумот те 2, за 99,7% - 3.
Дадените проценки на интервалот на доверба се прифатливи само за статистички популации со повеќе од 30 набљудувања. Со помала големина на популација (мали примероци), се користат посебни табели за одредување на критериумот t. Во овие табели, саканата вредност се наоѓа на пресекот на линијата што одговара на големината на популацијата (n-1), и колона што одговара на нивото на веројатност за прогноза без грешки (95,5%; 99,7%) избрана од истражувачот. Во медицинските истражувања, кога се утврдуваат граници на доверба за кој било индикатор, веројатноста за прогноза без грешки е 95,5% или повеќе. Ова значи дека вредноста на индикаторот добиен од популацијата на примерокот мора да се најде во општата популација во најмалку 95,5% од случаите.
Прашања за темата на лекцијата:
Релевантност на показателите за разновидност на особини кај статистичката популација.
Општи карактеристики на индикаторите за апсолутна варијација.
Стандардна девијација, пресметка, примена.
Релативни мерки на варијација.
Медијана, квартална оценка.
Проценка на статистичката значајност на резултатите од студијата.
Стандардна грешка на аритметичката средина, формула за пресметка, пример за употреба.
Пресметка на пропорцијата и нејзината стандардна грешка.
Концептот на веројатност за доверба, пример за употреба.
10. Концептот на интервал на доверба, неговата примена.
Тест задачи на темата со стандардни одговори:
1. АПСОЛУТНИ ИНДИКАТОРИ НА ВАРИЈАЦИЈА СЕ ПОВЕРУВААТ НА
1) коефициент на варијација
2) коефициент на осцилација
4) медијана
2. РЕЛАТИВНИ ИНДИКАТОРИ НА ВАРИЈАЦИЈАТА ПОВРЗАНИ
1) дисперзија
4) коефициент на варијација
3. КРИТЕРИУМ КОЈ СЕ УРЕДУВА СО ЕКСТРЕМНИ ВРЕДНОСТИ НА ОПЦИЈА ВО СЕРИЈАТА НА ВАРИЈАЦИЈА
2) амплитуда
3) дисперзија
4) коефициент на варијација
4. РАЗЛИКАТА НА ЕКСТРЕМНИТЕ ОПЦИИ Е
2) амплитуда
3) стандардна девијација
4) коефициент на варијација
5. ПРОСЕЧНИОТ КВАДРАТ НА ОТСТАПУВАЊАТА НА ИНДИВИДУАЛНИ ВРЕДНОСТИ НА КАРАКТЕРИСТИКА ОД НЕГОВИТЕ ПРОСЕЧНИ ВРЕДНОСТИ Е
1) коефициент на осцилација
2) медијана
3) дисперзија
6. ОДНОСОТ НА СКАЛАТА НА ВАРИЈАЦИЈА СО ПРОСЕЧНАТА ВРЕДНОСТ НА ЛИК Е
1) коефициент на варијација
2) стандардна девијација
4) коефициент на осцилација
7. СООДНОСОТ НА ПРОСЕЧНОТО КВАДРАТНИОТ ДЕВИИЈАЦИЈА НА ПРОСЕЧНАТА ВРЕДНОСТ НА КАРАКТЕРИСТИКА Е
1) дисперзија
2) коефициент на варијација
3) коефициент на осцилација
4) амплитуда
8. ОПЦИЈАТА КОЈА СЕ ВО СРЕДИНА НА СЕРИЈАТА ВАРИЈАЦИЈА И ЈА ДЕЛИ НА ДВА ЕДНАКВИ ДЕЛА Е
1) медијана
3) амплитуда
9. ВО МЕДИЦИНСКОТО ИСТРАЖУВАЊЕ, КОГА СЕ ПОСТАВУВААТ ГРАНИЦИ НА ДОВЕРБА ЗА КОЈ ИНДИКАТОР, СЕ ПРИФАЌА ВЕРОЈАТНОСТА ЗА ПРЕДВИДУВАЊЕ БЕЗ ГРЕШКИ
10. АКО 90 ПРИМЕРОЦИ ОД 100 ДАВААТ ТОЧНА ПРОЦЕНКА НА ПАРАМЕР ВО НАСЕЛЕНИЕТО, ОВА ЗНАЧИ ДЕКА ВЕРОЈАТНОСТА НА ДОВЕРБА ПЕДНАКВИ
11. АКО 10 ПРИМЕРОЦИ ОД 100 ДАВААТ НЕТОЧНА ПРОЦЕНКА, ВЕРОЈАТНОСТА ЗА ГРЕШКА Е ЕДНАКВА
12. ГРАНИЦИ НА ПРОСЕЧНИ ИЛИ РЕЛАТИВНИ ВРЕДНОСТИ ИЗЛЕКУВАЊЕ НА КОИ ПОРАДИ СЛУЧАЈНИ ОСЦИЛАЦИИ ИМА НЕЗНАЧЕНА ВЕРОЈАТНОСТ – ОВА Е
1) интервал на доверба
2) амплитуда
4) коефициент на варијација
13. ЗА МАЛ ПРИМЕРОК СЕ СМЕТА ТОА НАСЕЛЕНИЕ ВО КОЈ
1) n е помало или еднакво на 100
2) n е помало или еднакво на 30
3) n е помало или еднакво на 40
4) n е блиску до 0
14. ЗА ВЕРОЈАТНОСТА ЗА ПРОГНОЗУВАЊЕ БЕЗ ГРЕШКИ 95% КРИТЕРИОНА ВРЕДНОСТ тЕ
15. ЗА ВЕРОЈАТНОСТА ЗА ПРОГНОЗУВАЊЕ БЕЗ ГРЕШКИ 99% КРИТЕРИОНА ВРЕДНОСТ тЕ
16. ЗА РАСПРЕДЕЛУВАЊА БЛИСКИ ДО НОРМАЛНИ, НАСЕЛЕНИЕТО СЕ СМЕТАТ ЗА ХОМОГЕНО АКО КОЕФИЦИЕНТОТ НА ВАРИЈАЦИЈА НЕ НАМИНЕ
17. ОПЦИЈА, ОДДЕЛЕНИ ОПЦИИ, КОИ НУМЕРИЧКИТЕ ВРЕДНОСТИ НЕ НАМИНУВААТ 25% ОД МАКСИМАЛНИОТ МОЖЕН ВО ДАДЕНА СЕРИЈА - ОВА Е
2) долен квартил
3) горен квартал
4) квартил
18. ПОДАТОЦИ КОИ НЕ ЈА ИСКРЕВУВААТ И ПРАВИЛНО ЈА РЕФЛЕКЦИРААТ ОБЈЕКТИВНАТА РЕАЛНОСТ СЕ НАРЕКУВААТ
1) невозможно
2) подеднакво можно
3) сигурен
4) случајно
19. СПОРЕД ПРАВИЛОТО НА „ТРИ Сигма“, СО НОРМАЛНА РАСПРЕДЕЛБА НА КАРАКТЕРИСТИКА ВО ВНАТРЕ
 ЌЕ СЕ ЛОЦИРА
ЌЕ СЕ ЛОЦИРА1) 68,3% опција
Очекување и варијанса
Дозволете ни да измериме случајна променлива Нпати, на пример, десет пати ја мериме брзината на ветерот и сакаме да ја најдеме просечната вредност. Како просечната вредност е поврзана со функцијата на дистрибуција?
Ќе ги склопиме коцките многу пати. Бројот на поени што ќе се појават на коцката при секое фрлање е случајна променлива и може да земе која било природна вредност од 1 до 6. Аритметичката средина на паднатите поени пресметана за сите фрлања на коцки е исто така случајна променлива, но за големи Нсе стреми кон многу специфичен број - математичко очекување M x. Во овој случај M x = 3,5.
Како ја добивте оваа вредност? Пушти внатре Нтестови, еднаш ќе добиеш 1 поен, еднаш ќе добиеш 2 поени итн. Тогаш кога Н→ ∞ број на исходи во кои е зацртана една точка, Слично, Оттука
Модел 4.5. Коцки
Сега да претпоставиме дека го знаеме законот за распределба на случајната променлива x, односно знаеме дека случајната променлива xможе да земе вредности x 1 , x 2 , ..., x kсо веројатности стр 1 , стр 2 , ..., стр к.
Очекувана вредност M xслучајна променлива xеднакво на:
Одговори. 2,8.
Математичкото очекување не е секогаш разумна проценка на некоја случајна променлива. Така, за да се процени просечната плата, поразумно е да се користи концептот на медијана, односно таква вредност што бројот на луѓе кои примаат плата помала од просечната и поголема се совпаѓаат.
Медијанаслучајната променлива се нарекува број x 1/2 е таква што стр (x < x 1/2) = 1/2.
Со други зборови, веројатноста стр 1 дека случајната променлива xќе биде помал x 1/2 и веројатност стр 2 дека случајната променлива xќе биде поголема x 1/2 се идентични и еднакви на 1/2. Медијаната не се одредува единствено за сите дистрибуции.
Да се вратиме на случајната променлива x, што може да земе вредности x 1 , x 2 , ..., x kсо веројатности стр 1 , стр 2 , ..., стр к.
Варијансаслучајна променлива xПросечната вредност на квадратното отстапување на случајната променлива од нејзиното математичко очекување се нарекува:
Пример 2
Под условите од претходниот пример, пресметајте ја варијансата и стандардното отстапување на случајната променлива x.
Одговори. 0,16, 0,4.
Модел 4.6. Пукање во цел
Пример 3
Најдете ја распределбата на веројатноста на бројот на поени што се појавуваат на коцката при првото фрлање, медијаната, математичкото очекување, варијансата и стандардното отстапување.
Секој раб е подеднакво веројатно да испадне, така што дистрибуцијата ќе изгледа вака:
Стандардна девијација Се гледа дека отстапувањето на вредноста од просечната вредност е многу големо.
Својства на математичкото очекување:
- Математичкото очекување од збирот на независни случајни променливи е еднакво на збирот на нивните математички очекувања:
Пример 4
Најдете го математичкото очекување на збирот и производот на поени фрлени на две коцки.
Во примерот 3 откривме дека за една коцка М (x) = 3,5. Значи за две коцки
Карактеристики на дисперзија:
- Варијансата на збирот на независни случајни променливи е еднаква на збирот на варијансите:
Dx + y = Dx + Дај.
Дозволете за Нсе тркалаат на склопените коцки yпоени. Потоа
Овој резултат важи не само за ролни со коцки. Во многу случаи, тој ја одредува точноста на емпириски мерење на математичкото очекување. Се гледа дека со зголемен број на мерења Нширењето на вредностите околу просекот, односно стандардното отстапување, пропорционално се намалува
Варијансата на случајна променлива е поврзана со математичкото очекување на квадратот на оваа случајна променлива со следнава релација:
Ајде да ги најдеме математичките очекувања на двете страни на оваа еднаквост. А-приоритет,
Математичкото очекување на десната страна на еднаквоста, според својството на математичките очекувања, е еднакво на
Стандардна девијација
Стандардна девијацијаеднаков на квадратниот корен на варијансата:
При определување на стандардното отстапување за доволно голем волумен од популацијата што се проучува (n > 30), се користат следните формули:Поврзани информации.