Следното најважно својство на случајната променлива по математичкото очекување е нејзината дисперзија, дефинирана како средно квадратно отстапување од средната вредност:
Ако дотогаш е означено, варијансата VX ќе биде очекуваната вредност.
Како едноставен пример за пресметување на варијансата, да речеме дека штотуку ни е дадена понуда што не можеме да ја одбиеме: некој ни даде два сертификати за иста лотарија. Организаторите на лотаријата продаваат по 100 билети секоја недела, учествувајќи во посебно извлекување. Извлекувањето избира еден од овие тикети преку унифициран случаен процес - секој тикет има еднакви шанси да биде избран - а сопственикот на тој среќен билет добива сто милиони долари. Останатите 99 носители на лотарија не добиваат ништо.
Подарокот можеме да го искористиме на два начина: да купиме или две тикети во една лотарија, или по една за учество во две различни лотарии. Која стратегија е подобра? Ајде да се обидеме да го анализираме. За да го направите ова, дозволете ни да означиме со случајни променливи што ја претставуваат големината на нашите добивки на првиот и вториот тикет. Очекуваната вредност во милиони е
а истото важи и за Очекуваните вредности се адитивни, така што нашата просечна вкупна исплата ќе биде
без оглед на донесената стратегија.
Сепак, двете стратегии изгледаат различни. Да ги надминеме очекуваните вредности и да ја проучиме целосната дистрибуција на веројатност

Ако купиме два тикети во една лотарија, тогаш нашите шанси да не освоиме ништо ќе бидат 98% и 2% - шансите да освоиме 100 милиони. Ако купиме билети за различни извлекувања, бројките ќе бидат следни: 98,01% - шанса да не освоиме ништо, што е малку повисока од претходно; 0,01% - шанса да освоите 200 милиони, исто така малку повеќе од претходно; а шансата за освојување на 100 милиони сега е 1,98%. Така, во вториот случај, распределбата на големината е нешто повеќе расфрлана; средната вредност, 100 милиони долари, е нешто помалку веројатна, додека екстремите се поверојатни.
Токму овој концепт на ширење на случајна променлива е наменет да го одрази дисперзијата. Ние го мериме ширењето преку квадратот на отстапувањето на случајна променлива од нејзиното математичко очекување. Така, во случајот 1 варијансата ќе биде
во случајот 2 варијансата е
Како што очекувавме, последната вредност е малку поголема, бидејќи дистрибуцијата во случајот 2 е нешто пораспространета.
Кога работиме со варијанси, сè е на квадрат, па резултатот може да биде доста големи бројки. (Мултипликаторот е еден трилион, тоа треба да биде импресивно
дури и играчите навикнати на големи облози.) За да се претворат вредностите во позначајна оригинална скала, често се зема квадратниот корен на варијансата. Добиениот број се нарекува стандардна девијација и обично се означува со грчката буква a:
Стандардните отстапувања на големината за нашите две стратегии за лотарија се . На некој начин, втората опција е околу 71.247 долари поризична.
Како варијансата помага при изборот на стратегија? Не е јасно. Стратегијата со поголема варијанса е поризична; но што е подобро за нашиот паричник - ризик или безбедно играње? Да имаме можност да купиме не два билети, туку сите сто. Тогаш би можеле да гарантираме добивка на една лотарија (а варијансата би била нула); или би можеле да играте во сто различни извлекувања, без да добиете ништо со веројатност, но да имате ненула шанса да освоите до долари. Изборот на една од овие алтернативи е надвор од опсегот на оваа книга; се што можеме да направиме овде е да објасниме како да ги правиме пресметките.
Всушност, постои поедноставен начин да се пресмета варијансата отколку директно да се користи дефиницијата (8.13). (Постојат сите причини да се сомневаме во некаква скриена математика овде; инаку, зошто варијансата во примерите на лотаријата би се покажала како цел број повеќекратно? Имаме
бидејќи - константа; оттука,
„Варијансата е средна вредност на квадратот минус квадратот на средната вредност“.
На пример, во проблемот со лотаријата, просечната вредност се покажува или Одземањето (квадратот на просекот) дава резултати што веќе сме ги добиле порано на потежок начин.
Меѓутоа, постои уште поедноставна формула која е применлива кога пресметуваме за независни X и Y. Имаме

бидејќи, како што знаеме, за независни случајни променливи Затоа,

Варијансата на збирот на независни случајни променливи е еднаква на збирот на нивните варијанси. Така, на пример, варијансата на износот што може да се добие со еден лоз е еднаков на
Според тоа, дисперзијата на вкупните добивки за две лозови во две различни (независни) лотарии ќе биде Соодветната дисперзивна вредност за независните лозови ќе биде
Варијансата на збирот на поени фрлени на две коцки може да се добие со користење на истата формула, бидејќи тоа е збир на две независни случајни променливи. Ние имаме
за правилната коцка; затоа, во случај на поместен центар на маса
затоа, ако двете коцки имаат поместен центар на маса. Имајте на ум дека во вториот случај варијансата е поголема, иако е потребна средна вредност од 7 почесто отколку во случај на обични коцки. Ако нашата цел е да свиткаме повеќе среќни седумки, тогаш варијансата не е најдобар показател за успех.
Во ред, утврдивме како да пресметаме варијанса. Но, сè уште не сме дале одговор на прашањето зошто е неопходно да се пресмета варијансата. Сите го прават тоа, но зошто? Главната причина е нееднаквоста на Чебишев, која воспоставува важно својство на дисперзија:
(Оваа нееднаквост се разликува од неравенките на Чебишев за суми што ги сретнавме во Поглавје 2.) На квалитативно ниво, (8.17) наведува дека случајната променлива X ретко зема вредности далеку од нејзината средна вредност ако нејзината варијанса VX е мала. Доказ
управувањето е извонредно едноставно. Навистина,

делењето со го комплетира доказот.
Ако математичкото очекување го означиме со a и стандардното отстапување со a и го замениме во (8.17) тогаш условот се претвора во затоа, добиваме од (8.17)
Така, X ќе лежи во рамките - пати повеќе од стандардното отстапување на неговата средна вредност, освен во случаи кога веројатноста не надминува Случајната променлива ќе лежи во рамките на 2а од најмалку 75% од испитувањата; кои се движат од до - барем за 99%. Тоа се случаи на нееднаквост на Чебишев.
Ако фрлите неколку коцки еднаш, тогаш вкупниот збир на поени во сите фрлања речиси секогаш ќе биде блиску до: Причината за тоа е следнава: варијансата на независните фрлања ќе биде Варијансата во значи стандардна девијација на сè.
Затоа, од нееднаквоста на Чебишев добиваме дека збирот на поени ќе лежи помеѓу
барем за 99% од сите ролни коцки. На пример, резултатот од милион фрлања со веројатност од повеќе од 99% ќе биде помеѓу 6,976 милиони и 7,024 милиони.
Општо земено, нека X е која било случајна променлива на просторот на веројатност Π со конечно математичко очекување и конечно стандардно отстапување a. Потоа можеме да го воведеме во предвид просторот на веројатност Pn, чиишто елементарни настани се -секвенци каде секоја , а веројатноста е дефинирана како
Ако сега ги дефинираме случајните променливи со формулата
потоа вредноста
ќе биде збир на независни случајни променливи, што одговара на процесот на собирање независни реализации на вредноста X на P. Математичкото очекување ќе биде еднакво и стандардното отстапување - ; според тоа, просечната вредност на реализациите,
![]()
ќе се движи од до во најмалку 99% од временскиот период. Со други зборови, ако изберете доволно голем, аритметичката средина на независните тестови речиси секогаш ќе биде многу блиску до очекуваната вредност (Во учебниците за теорија на веројатност се докажува уште посилна теорема, наречена силен закон на големи броеви; за нас едноставната последица на нееднаквоста на Чебишев, која штотуку ја извадивме.)
Понекогаш не ги знаеме карактеристиките на просторот на веројатност, но треба да го процениме математичкото очекување на случајната променлива X користејќи повторени набљудувања на нејзината вредност. (На пример, можеби би сакале просечната јануарска пладневна температура во Сан Франциско; или можеби сакаме да го знаеме очекуваниот животен век на кој агентите за осигурување треба да ги засноваат своите пресметки.) Ако имаме на располагање независни емпириски набљудувања, можеме да претпоставиме дека вистинското математичко очекување е приближно еднакво
![]()
Можете исто така да ја процените варијансата користејќи ја формулата
Гледајќи ја оваа формула, можеби ќе помислите дека во неа има печатна грешка; Се чини дека треба да биде таму како во (8.19), бидејќи вистинската вредност на дисперзијата е одредена во (8.15) преку очекуваните вредности. Меѓутоа, заменувањето овде со ни овозможува да добиеме подобра проценка, бидејќи од дефиницијата (8.20) произлегува дека
![]()
Еве го доказот:

(Во оваа пресметка се потпираме на независноста на набљудувањата кога заменуваме со )
Во пракса, за да се проценат резултатите од експериментот со случајна променлива X, обично се пресметува емпириската средина и емпириското стандардно отстапување и потоа се запишува одговорот во форма Еве, на пример, резултатите од фрлањето пар коцки, веројатно точно.
Случајните променливи, покрај законите за дистрибуција, исто така може да се опишат нумерички карактеристики .
Математичко очекување M (x) на случајна променлива се нарекува нејзина средна вредност.
Математичкото очекување на дискретна случајна променлива се пресметува со помош на формулата
Каде – вредности на случајни променливи, стр јас -нивните веројатности.
Да ги разгледаме својствата на математичкото очекување:
1. Математичкото очекување на константата е еднакво на самата константа
2. Ако случајна променлива се помножи со одреден број k, тогаш математичкото очекување ќе се помножи со истиот број
M (kx) = kM (x)
3. Математичкото очекување од збирот на случајни променливи е еднакво на збирот на нивните математички очекувања
M (x 1 + x 2 + … + x n) = M (x 1) + M (x 2) +…+ M (x n)
4. M (x 1 - x 2) = M (x 1) - M (x 2)
5. За независни случајни променливи x 1, x 2, … x n, математичкото очекување на производот е еднакво на производот на нивните математички очекувања
M (x 1, x 2, ... x n) = M (x 1) M (x 2) ... M (x n)
6. M (x - M (x)) = M (x) - M (M (x)) = M (x) - M (x) = 0
Да го пресметаме математичкото очекување за случајната променлива од Пример 11.
M(x) = = ![]() .
.
Пример 12.Нека случајните променливи x 1, x 2 се специфицираат соодветно со законите за распределба:
x 1 Табела 2
x 2 Табела 3
Да ги пресметаме M (x 1) и M (x 2)
M (x 1) = (- 0,1) 0,1 + (- 0,01) 0,2 + 0 0,4 + 0,01 0,2 + 0,1 0,1 = 0
M (x 2) = (- 20) 0,3 + (- 10) 0,1 + 0 0,2 + 10 0,1 + 20 0,3 = 0
Математичките очекувања на двете случајни променливи се исти - тие се еднакви на нула. Сепак, природата на нивната дистрибуција е различна. Ако вредностите на x 1 се разликуваат малку од нивните математички очекувања, тогаш вредностите на x 2 во голема мера се разликуваат од нивните математички очекувања, а веројатноста за такви отстапувања не се мали. Овие примери покажуваат дека е невозможно од просечната вредност да се одреди кои отстапувања од неа се случуваат, и помали и поголеми. Значи, со исти просечни годишни врнежи во две области, не може да се каже дека овие површини се подеднакво поволни за земјоделски работи. Слично на тоа, врз основа на индикаторот за просечна плата, не е можно да се процени уделот на високо и ниско платените работници. Затоа, се воведува нумеричка карактеристика - дисперзија D(x) , што го карактеризира степенот на отстапување на случајна променлива од нејзината просечна вредност:
D (x) = M (x - M (x)) 2. (2)
Дисперзијата е математичко очекување на квадратното отстапување на случајна променлива од математичкото очекување. За дискретна случајна променлива, варијансата се пресметува со помош на формулата:
D(x)= ![]() =
= ![]() (3)
(3)
Од дефиницијата за дисперзија произлегува дека D (x) 0.
Карактеристики на дисперзија:
1. Варијансата на константата е нула
2. Ако случајната променлива се помножи со одреден број k, тогаш варијансата ќе се помножи со квадратот на овој број
D (kx) = k 2 D (x)
3. D (x) = M (x 2) - M 2 (x)
4. За парни независни случајни променливи x 1 , x 2 , … x n варијансата на збирот е еднаква на збирот на варијансите.
D (x 1 + x 2 + … + x n) = D (x 1) + D (x 2) +…+ D (x n)
Да ја пресметаме варијансата за случајната променлива од Пример 11.
Математичко очекување M (x) = 1. Според тоа, според формулата (3) имаме:
D (x) = (0 – 1) 2 1/4 + (1 – 1) 2 1/2 + (2 – 1) 2 1/4 =1 1/4 +1 1/4= 1/2
Забележете дека е полесно да се пресмета варијансата ако користите својство 3:
D (x) = M (x 2) - M 2 (x).
Ајде да ги пресметаме варијансите за случајните променливи x 1 , x 2 од Пример 12 користејќи ја оваа формула. Математичките очекувања на двете случајни променливи се нула.
D (x 1) = 0,01 0,1 + 0,0001 0,2 + 0,0001 0,2 + 0,01 0,1 = 0,001 + 0,00002 + 0,00002 + 0,001 = 0,00204
D (x 2) = (-20) 2 0,3 + (-10) 2 0,1 + 10 2 0,1 + 20 2 0,3 = 240 +20 = 260
Колку е поблиску вредноста на варијансата до нула, толку е помало ширењето на случајната променлива во однос на средната вредност.
Количината се нарекува Стандардна девијација. Режим на случајна променлива x дискретен тип MdСе вика вредноста на случајната променлива која има најголема веројатност.
Режим на случајна променлива x континуиран тип Md, е реален број дефиниран како точка на максимум на густината на распределбата на веројатноста f(x).
Медијана на случајна променлива x континуиран тип Mnе реален број кој ја задоволува равенката
Очекувана вредностДисперзијаконтинуирана случајна променлива X, чиишто можни вредности припаѓаат на целата оска Ox, се определува со еднаквоста: ![]()
Цел на услугата. Онлајн калкулаторот е дизајниран да решава проблеми во кои или густина на дистрибуција f(x) или дистрибутивна функција F(x) (види пример). Обично во такви задачи треба да најдете математичко очекување, стандардно отстапување, графички функции f(x) и F(x).
Инструкции. Изберете го типот на изворните податоци: густина на дистрибуција f(x) или функција на дистрибуција F(x).
Густината на распределбата f(x) е дадена: 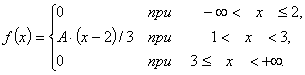
Функцијата за распределба F(x) е дадена: 
Континуирана случајна променлива е одредена со густина на веројатност 
(Рејлиевиот закон за дистрибуција - се користи во радио инженерството). Најдете M(x) , D(x) .
Се повикува случајната променлива X континуирано
, ако неговата дистрибутивна функција F(X)=P(X< x) непрерывна и имеет производную.
Функцијата за распределба на континуирана случајна променлива се користи за пресметување на веројатноста случајната променлива да падне во даден интервал:
P(α< X < β)=F(β) - F(α)
Покрај тоа, за континуирана случајна променлива, не е важно дали нејзините граници се вклучени во овој интервал или не:
P(α< X < β) = P(α ≤ X < β) = P(α ≤ X ≤ β)
Густина на дистрибуција
континуирана случајна променлива се нарекува функција
f(x)=F’(x) , извод на функцијата распределба.
Својства на густината на дистрибуцијата
1. Густината на распределбата на случајната променлива е ненегативна (f(x) ≥ 0) за сите вредности на x.2. Состојба за нормализација:
Геометриското значење на условот за нормализација: површината под кривата на густина на распределбата е еднаква на единство.
3. Веројатноста случајната променлива X да падне во интервалот од α до β може да се пресмета со формулата
Геометриски, веројатноста континуираната случајна променлива X да падне во интервалот (α, β) е еднаква на областа на криволинеарниот трапез под кривата на густина на дистрибуција врз основа на овој интервал.
4. Функцијата на дистрибуција се изразува во однос на густината на следниот начин:
Вредноста на густината на распределбата во точката x не е еднаква на веројатноста да се прифати оваа вредност за континуирана случајна променлива, можеме да зборуваме само за веројатноста да падне во даден интервал. Нека)