$X$. ಪ್ರಾರಂಭಿಸಲು, ನಾವು ಈ ಕೆಳಗಿನ ವ್ಯಾಖ್ಯಾನವನ್ನು ನೆನಪಿಸಿಕೊಳ್ಳೋಣ:
ವ್ಯಾಖ್ಯಾನ 1
ಜನಸಂಖ್ಯೆ-- ನಿರ್ದಿಷ್ಟ ಪ್ರಕಾರದ ಯಾದೃಚ್ಛಿಕವಾಗಿ ಆಯ್ಕೆಮಾಡಿದ ವಸ್ತುಗಳ ಒಂದು ಸೆಟ್, ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ನಿರ್ದಿಷ್ಟ ಮೌಲ್ಯಗಳನ್ನು ಪಡೆಯುವ ಸಲುವಾಗಿ ವೀಕ್ಷಣೆಗಳನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ, ನಿರ್ದಿಷ್ಟ ಪ್ರಕಾರದ ಒಂದು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಅನ್ನು ಅಧ್ಯಯನ ಮಾಡುವಾಗ ನಿರಂತರ ಪರಿಸ್ಥಿತಿಗಳಲ್ಲಿ ನಡೆಸಲಾಗುತ್ತದೆ.
ವ್ಯಾಖ್ಯಾನ 2
ಸಾಮಾನ್ಯ ವ್ಯತ್ಯಾಸ-- ಜನಸಂಖ್ಯೆಯ ಮೌಲ್ಯಗಳ ವರ್ಗದ ವಿಚಲನಗಳ ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಅವುಗಳ ಸರಾಸರಿ ಮೌಲ್ಯದಿಂದ ಭಿನ್ನವಾಗಿರುತ್ತದೆ.
ಆಯ್ಕೆಯ ಮೌಲ್ಯಗಳು $x_1,\ x_2,\dots ,x_k$ ಅನುಕ್ರಮವಾಗಿ $n_1,\ n_2,\dots ,n_k$ ಆವರ್ತನಗಳನ್ನು ಹೊಂದಿರಲಿ. ನಂತರ ಸಾಮಾನ್ಯ ವ್ಯತ್ಯಾಸವನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
ಒಂದು ವಿಶೇಷ ಪ್ರಕರಣವನ್ನು ಪರಿಗಣಿಸೋಣ. ಎಲ್ಲಾ ಆಯ್ಕೆಗಳು $x_1,\ x_2,\dots ,x_k$ ವಿಭಿನ್ನವಾಗಿರಲಿ. ಈ ಸಂದರ್ಭದಲ್ಲಿ $n_1,\ n_2,\dots ,n_k=1$. ಈ ಸಂದರ್ಭದಲ್ಲಿ ಸಾಮಾನ್ಯ ವ್ಯತ್ಯಾಸವನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ ಎಂದು ನಾವು ಕಂಡುಕೊಳ್ಳುತ್ತೇವೆ:
ಈ ಪರಿಕಲ್ಪನೆಯು ಸಾಮಾನ್ಯ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಪರಿಕಲ್ಪನೆಯೊಂದಿಗೆ ಸಹ ಸಂಬಂಧಿಸಿದೆ.
ವ್ಯಾಖ್ಯಾನ 3
ಸಾಮಾನ್ಯ ಪ್ರಮಾಣಿತ ವಿಚಲನ
\[(\sigma )_g=\sqrt(D_g)\]
ಮಾದರಿ ವ್ಯತ್ಯಾಸ
ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ $X$ ಗೆ ಸಂಬಂಧಿಸಿದಂತೆ ನಮಗೆ ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ನೀಡೋಣ. ಪ್ರಾರಂಭಿಸಲು, ನಾವು ಈ ಕೆಳಗಿನ ವ್ಯಾಖ್ಯಾನವನ್ನು ನೆನಪಿಸಿಕೊಳ್ಳೋಣ:
ವ್ಯಾಖ್ಯಾನ 4
ಮಾದರಿ ಜನಸಂಖ್ಯೆ-- ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಆಯ್ದ ವಸ್ತುಗಳ ಭಾಗ.
ವ್ಯಾಖ್ಯಾನ 5
ಮಾದರಿ ವ್ಯತ್ಯಾಸ-- ಮಾದರಿ ಜನಸಂಖ್ಯೆಯ ಮೌಲ್ಯಗಳ ಅಂಕಗಣಿತದ ಸರಾಸರಿ.
ಆಯ್ಕೆಯ ಮೌಲ್ಯಗಳು $x_1,\ x_2,\dots ,x_k$ ಅನುಕ್ರಮವಾಗಿ $n_1,\ n_2,\dots ,n_k$ ಆವರ್ತನಗಳನ್ನು ಹೊಂದಿರಲಿ. ನಂತರ ಮಾದರಿ ವ್ಯತ್ಯಾಸವನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
ಒಂದು ವಿಶೇಷ ಪ್ರಕರಣವನ್ನು ಪರಿಗಣಿಸೋಣ. ಎಲ್ಲಾ ಆಯ್ಕೆಗಳು $x_1,\ x_2,\dots ,x_k$ ವಿಭಿನ್ನವಾಗಿರಲಿ. ಈ ಸಂದರ್ಭದಲ್ಲಿ $n_1,\ n_2,\dots ,n_k=1$. ಈ ಸಂದರ್ಭದಲ್ಲಿ ಮಾದರಿ ವ್ಯತ್ಯಾಸವನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ ಎಂದು ನಾವು ಕಂಡುಕೊಳ್ಳುತ್ತೇವೆ:
ಮಾದರಿ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಪರಿಕಲ್ಪನೆಯು ಈ ಪರಿಕಲ್ಪನೆಗೆ ಸಂಬಂಧಿಸಿದೆ.
ವ್ಯಾಖ್ಯಾನ 6
ಮಾದರಿ ಪ್ರಮಾಣಿತ ವಿಚಲನ-- ಸಾಮಾನ್ಯ ವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲ:
\[(\sigma )_в=\sqrt(D_в)\]
ಸರಿಪಡಿಸಿದ ವ್ಯತ್ಯಾಸ
ಸರಿಪಡಿಸಲಾದ ವ್ಯತ್ಯಾಸವನ್ನು ಕಂಡುಹಿಡಿಯಲು $S^2$ ಮಾದರಿ ವ್ಯತ್ಯಾಸವನ್ನು $\frac(n)(n-1)$ ಭಾಗದಿಂದ ಗುಣಿಸುವುದು ಅವಶ್ಯಕ, ಅಂದರೆ
ಈ ಪರಿಕಲ್ಪನೆಯು ಸರಿಪಡಿಸಿದ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಪರಿಕಲ್ಪನೆಯೊಂದಿಗೆ ಸಹ ಸಂಬಂಧಿಸಿದೆ, ಇದು ಸೂತ್ರದಿಂದ ಕಂಡುಬರುತ್ತದೆ:
ಒಂದು ವೇಳೆ ರೂಪಾಂತರಗಳ ಮೌಲ್ಯಗಳು ಪ್ರತ್ಯೇಕವಾಗಿಲ್ಲದಿದ್ದರೂ ಮಧ್ಯಂತರಗಳನ್ನು ಪ್ರತಿನಿಧಿಸಿದರೆ, ನಂತರ ಸಾಮಾನ್ಯ ಅಥವಾ ಮಾದರಿ ವ್ಯತ್ಯಾಸಗಳನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವ ಸೂತ್ರಗಳಲ್ಲಿ, $x_i$ ಮೌಲ್ಯವನ್ನು ಮಧ್ಯಂತರದ ಮಧ್ಯದ ಮೌಲ್ಯವಾಗಿ ತೆಗೆದುಕೊಳ್ಳಲಾಗುತ್ತದೆ ಯಾವ $x_i.$ ಸೇರಿದೆ.
ವ್ಯತ್ಯಾಸ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಕಂಡುಹಿಡಿಯಲು ಸಮಸ್ಯೆಯ ಉದಾಹರಣೆ
ಉದಾಹರಣೆ 1
ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ಈ ಕೆಳಗಿನ ವಿತರಣಾ ಕೋಷ್ಟಕದಿಂದ ವ್ಯಾಖ್ಯಾನಿಸಲಾಗಿದೆ:
ಚಿತ್ರ 1.
ಅದಕ್ಕಾಗಿ ಮಾದರಿ ವ್ಯತ್ಯಾಸ, ಮಾದರಿ ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಸರಿಪಡಿಸಿದ ವ್ಯತ್ಯಾಸ ಮತ್ತು ಸರಿಪಡಿಸಿದ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಕಂಡುಹಿಡಿಯೋಣ.
ಈ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸಲು, ನಾವು ಮೊದಲು ಲೆಕ್ಕಾಚಾರದ ಕೋಷ್ಟಕವನ್ನು ತಯಾರಿಸುತ್ತೇವೆ:
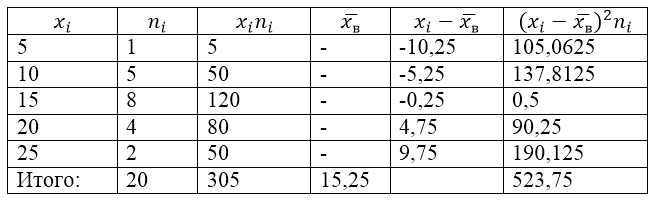
ಚಿತ್ರ 2.
ಕೋಷ್ಟಕದಲ್ಲಿನ ಮೌಲ್ಯ $\overline(x_в)$ (ಮಾದರಿ ಸರಾಸರಿ) ಸೂತ್ರದಿಂದ ಕಂಡುಬರುತ್ತದೆ:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಮಾದರಿ ವ್ಯತ್ಯಾಸವನ್ನು ಕಂಡುಹಿಡಿಯೋಣ:
ಮಾದರಿ ಪ್ರಮಾಣಿತ ವಿಚಲನ:
\[(\sigma )_в=\sqrt(D_в)\ಅಂದಾಜು 5.12\]
ಸರಿಪಡಿಸಿದ ವ್ಯತ್ಯಾಸ:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26.1875\ಅಂದಾಜು 27.57\]
ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಸರಿಪಡಿಸಲಾಗಿದೆ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ(ಸಮಾನಾರ್ಥಕಗಳು: ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಚದರ ವಿಚಲನ; ಸಂಬಂಧಿತ ನಿಯಮಗಳು: ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಮಾಣಿತ ಹರಡುವಿಕೆ) - ಸಂಭವನೀಯತೆ ಸಿದ್ಧಾಂತ ಮತ್ತು ಅಂಕಿಅಂಶಗಳಲ್ಲಿ, ಅದರ ಗಣಿತದ ನಿರೀಕ್ಷೆಗೆ ಸಂಬಂಧಿಸಿದಂತೆ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಮೌಲ್ಯಗಳ ಪ್ರಸರಣದ ಸಾಮಾನ್ಯ ಸೂಚಕ. ಮೌಲ್ಯಗಳ ಮಾದರಿಗಳ ಸೀಮಿತ ಶ್ರೇಣಿಗಳೊಂದಿಗೆ, ಗಣಿತದ ನಿರೀಕ್ಷೆಯ ಬದಲಿಗೆ, ಮಾದರಿಗಳ ಗುಂಪಿನ ಅಂಕಗಣಿತದ ಸರಾಸರಿಯನ್ನು ಬಳಸಲಾಗುತ್ತದೆ.
ಎನ್ಸೈಕ್ಲೋಪೀಡಿಕ್ YouTube
-
1 / 5
ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯೇಬಲ್ನ ಮಾಪನದ ಘಟಕಗಳಲ್ಲಿ ಅಳೆಯಲಾಗುತ್ತದೆ ಮತ್ತು ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ, ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರಗಳನ್ನು ನಿರ್ಮಿಸುವಾಗ, ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯವಾಗಿ ಊಹೆಗಳನ್ನು ಪರೀಕ್ಷಿಸುವಾಗ, ಯಾದೃಚ್ಛಿಕ ಅಸ್ಥಿರಗಳ ನಡುವಿನ ರೇಖೀಯ ಸಂಬಂಧವನ್ನು ಅಳೆಯುವಾಗ ಬಳಸಲಾಗುತ್ತದೆ. ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲ ಎಂದು ವ್ಯಾಖ್ಯಾನಿಸಲಾಗಿದೆ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ:
s = n n - 1 σ 2 = 1 n - 1 - i = 1 n (x i - x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\left(x_(i)-(\bar (x))\right)^(2)));)- ಗಮನಿಸಿ: ಎಂಎಸ್ಡಿ (ರೂಟ್ ಮೀನ್ ಸ್ಕ್ವೇರ್ ಡಿವಿಯೇಷನ್) ಮತ್ತು ಎಸ್ಟಿಡಿ (ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಡಿವಿಯೇಷನ್) ಹೆಸರುಗಳಲ್ಲಿ ಅವುಗಳ ಸೂತ್ರಗಳೊಂದಿಗೆ ಆಗಾಗ್ಗೆ ವ್ಯತ್ಯಾಸಗಳಿವೆ. ಉದಾಹರಣೆಗೆ, ಪೈಥಾನ್ ಪ್ರೋಗ್ರಾಮಿಂಗ್ ಭಾಷೆಯ numPy ಮಾಡ್ಯೂಲ್ನಲ್ಲಿ, std() ಕಾರ್ಯವನ್ನು "ಪ್ರಮಾಣಿತ ವಿಚಲನ" ಎಂದು ವಿವರಿಸಲಾಗಿದೆ, ಆದರೆ ಸೂತ್ರವು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಪ್ರತಿಬಿಂಬಿಸುತ್ತದೆ (ಮಾದರಿಯ ಮೂಲದಿಂದ ವಿಭಾಗ). ಎಕ್ಸೆಲ್ ನಲ್ಲಿ, STANDARDEVAL() ಕಾರ್ಯವು ವಿಭಿನ್ನವಾಗಿದೆ (n-1 ರ ಮೂಲದಿಂದ ಭಾಗಿಸಿ).
ಪ್ರಮಾಣಿತ ವಿಚಲನ(ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಅಂದಾಜು Xಅದರ ವ್ಯತ್ಯಾಸದ ಪಕ್ಷಪಾತವಿಲ್ಲದ ಅಂದಾಜಿನ ಆಧಾರದ ಮೇಲೆ ಅದರ ಗಣಿತದ ನಿರೀಕ್ಷೆಗೆ ಸಂಬಂಧಿಸಿದಂತೆ) s (\ ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ ಗಳು):
σ = 1 n ∑ i = 1 n (x i - x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\ಬಲ) ^(2))))ಎಲ್ಲಿ σ 2 (\ ಡಿಸ್ಪ್ಲೇ ಸ್ಟೈಲ್ \ ಸಿಗ್ಮಾ ^(2))- ಪ್ರಸರಣ; x i (\ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ x_(i)) - iಆಯ್ಕೆಯ ಅಂಶ; n (\ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ n)- ಮಾದರಿ ಅಳತೆ; - ಮಾದರಿಯ ಅಂಕಗಣಿತದ ಸರಾಸರಿ:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + ... + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ldots +x_(n)).)ಎರಡೂ ಅಂದಾಜುಗಳು ಪಕ್ಷಪಾತಿ ಎಂದು ಗಮನಿಸಬೇಕು. ಸಾಮಾನ್ಯ ಸಂದರ್ಭದಲ್ಲಿ, ಪಕ್ಷಪಾತವಿಲ್ಲದ ಅಂದಾಜನ್ನು ನಿರ್ಮಿಸುವುದು ಅಸಾಧ್ಯ. ಆದಾಗ್ಯೂ, ಪಕ್ಷಪಾತವಿಲ್ಲದ ವ್ಯತ್ಯಾಸದ ಅಂದಾಜಿನ ಆಧಾರದ ಮೇಲೆ ಅಂದಾಜು ಸ್ಥಿರವಾಗಿರುತ್ತದೆ.
GOST R 8.736-2011 ಗೆ ಅನುಗುಣವಾಗಿ, ಈ ವಿಭಾಗದ ಎರಡನೇ ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ. ದಯವಿಟ್ಟು ಫಲಿತಾಂಶಗಳನ್ನು ಪರಿಶೀಲಿಸಿ.
ಮೂರು ಸಿಗ್ಮಾ ನಿಯಮ
ಮೂರು ಸಿಗ್ಮಾ ನಿಯಮ (3 σ (\ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ 3\ಸಿಗ್ಮಾ)) - ಸಾಮಾನ್ಯವಾಗಿ ವಿತರಿಸಲಾದ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಬಹುತೇಕ ಎಲ್ಲಾ ಮೌಲ್ಯಗಳು ಮಧ್ಯಂತರದಲ್ಲಿ ಇರುತ್ತದೆ (x ¯ - 3 σ ; x ¯ + 3 σ) (\ ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ \ಎಡ((\ಬಾರ್ (x))-3\ಸಿಗ್ಮಾ ;(\ಬಾರ್ (x))+3\ಸಿಗ್ಮಾ \ಬಲ)). ಹೆಚ್ಚು ಕಟ್ಟುನಿಟ್ಟಾಗಿ - ಅಂದಾಜು 0.9973 ಸಂಭವನೀಯತೆಯೊಂದಿಗೆ, ಸಾಮಾನ್ಯವಾಗಿ ವಿತರಿಸಲಾದ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಮೌಲ್ಯವು ನಿರ್ದಿಷ್ಟಪಡಿಸಿದ ಮಧ್ಯಂತರದಲ್ಲಿದೆ (ಒದಗಿಸಿದ ಮೌಲ್ಯ x ¯ (\ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ (\ಬಾರ್ (x)))ನಿಜ, ಮತ್ತು ಮಾದರಿ ಸಂಸ್ಕರಣೆಯ ಪರಿಣಾಮವಾಗಿ ಪಡೆಯಲಾಗಿಲ್ಲ).
ನಿಜವಾದ ಮೌಲ್ಯವಾಗಿದ್ದರೆ x ¯ (\ಡಿಸ್ಪ್ಲೇಸ್ಟೈಲ್ (\ಬಾರ್ (x)))ತಿಳಿದಿಲ್ಲ, ನಂತರ ನೀವು ಬಳಸಬಾರದು σ (\ ಡಿಸ್ಪ್ಲೇ ಸ್ಟೈಲ್ \ ಸಿಗ್ಮಾ ), ಎ ರು. ಹೀಗಾಗಿ, ಮೂರು ಸಿಗ್ಮಾದ ನಿಯಮವು ಮೂರು ನಿಯಮವಾಗಿ ರೂಪಾಂತರಗೊಳ್ಳುತ್ತದೆ ರು .
ಪ್ರಮಾಣಿತ ವಿಚಲನ ಮೌಲ್ಯದ ವ್ಯಾಖ್ಯಾನ
ಒಂದು ದೊಡ್ಡ ಪ್ರಮಾಣಿತ ವಿಚಲನ ಮೌಲ್ಯವು ಸೆಟ್ನ ಸರಾಸರಿ ಮೌಲ್ಯದೊಂದಿಗೆ ಪ್ರಸ್ತುತಪಡಿಸಿದ ಸೆಟ್ನಲ್ಲಿ ಮೌಲ್ಯಗಳ ಹೆಚ್ಚಿನ ಹರಡುವಿಕೆಯನ್ನು ತೋರಿಸುತ್ತದೆ; ಒಂದು ಸಣ್ಣ ಮೌಲ್ಯವು, ಅದರ ಪ್ರಕಾರ, ಸೆಟ್ನಲ್ಲಿನ ಮೌಲ್ಯಗಳನ್ನು ಸರಾಸರಿ ಮೌಲ್ಯದ ಸುತ್ತಲೂ ಗುಂಪು ಮಾಡಲಾಗಿದೆ ಎಂದು ತೋರಿಸುತ್ತದೆ.
ಉದಾಹರಣೆಗೆ, ನಾವು ಮೂರು ಸಂಖ್ಯೆಯ ಸೆಟ್ಗಳನ್ನು ಹೊಂದಿದ್ದೇವೆ: (0, 0, 14, 14), (0, 6, 8, 14) ಮತ್ತು (6, 6, 8, 8). ಎಲ್ಲಾ ಮೂರು ಸೆಟ್ಗಳು ಸರಾಸರಿ ಮೌಲ್ಯಗಳನ್ನು 7 ಕ್ಕೆ ಸಮನಾಗಿರುತ್ತದೆ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನಗಳು ಕ್ರಮವಾಗಿ 7, 5 ಮತ್ತು 1 ಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ. ಕೊನೆಯ ಸೆಟ್ ಸಣ್ಣ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಹೊಂದಿದೆ, ಏಕೆಂದರೆ ಸೆಟ್ನಲ್ಲಿನ ಮೌಲ್ಯಗಳನ್ನು ಸರಾಸರಿ ಮೌಲ್ಯದ ಸುತ್ತಲೂ ಗುಂಪು ಮಾಡಲಾಗಿದೆ; ಮೊದಲ ಸೆಟ್ ದೊಡ್ಡ ಪ್ರಮಾಣಿತ ವಿಚಲನ ಮೌಲ್ಯವನ್ನು ಹೊಂದಿದೆ - ಸೆಟ್ನೊಳಗಿನ ಮೌಲ್ಯಗಳು ಸರಾಸರಿ ಮೌಲ್ಯದಿಂದ ಹೆಚ್ಚು ಭಿನ್ನವಾಗಿರುತ್ತವೆ.
ಸಾಮಾನ್ಯ ಅರ್ಥದಲ್ಲಿ, ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಅನಿಶ್ಚಿತತೆಯ ಅಳತೆ ಎಂದು ಪರಿಗಣಿಸಬಹುದು. ಉದಾಹರಣೆಗೆ, ಭೌತಶಾಸ್ತ್ರದಲ್ಲಿ, ಕೆಲವು ಪ್ರಮಾಣದ ಅನುಕ್ರಮ ಅಳತೆಗಳ ಸರಣಿಯ ದೋಷವನ್ನು ನಿರ್ಧರಿಸಲು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಬಳಸಲಾಗುತ್ತದೆ. ಸಿದ್ಧಾಂತದಿಂದ ಊಹಿಸಲಾದ ಮೌಲ್ಯಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಅಧ್ಯಯನದ ಅಡಿಯಲ್ಲಿ ವಿದ್ಯಮಾನದ ತೋರಿಕೆಯನ್ನು ನಿರ್ಧರಿಸಲು ಈ ಮೌಲ್ಯವು ಬಹಳ ಮುಖ್ಯವಾಗಿದೆ: ಮಾಪನಗಳ ಸರಾಸರಿ ಮೌಲ್ಯವು ಸಿದ್ಧಾಂತದಿಂದ ಊಹಿಸಲಾದ ಮೌಲ್ಯಗಳಿಗಿಂತ ಹೆಚ್ಚು ಭಿನ್ನವಾಗಿದ್ದರೆ (ದೊಡ್ಡ ಪ್ರಮಾಣಿತ ವಿಚಲನ), ನಂತರ ಪಡೆದ ಮೌಲ್ಯಗಳು ಅಥವಾ ಅವುಗಳನ್ನು ಪಡೆಯುವ ವಿಧಾನವನ್ನು ಮರುಪರಿಶೀಲಿಸಬೇಕು. ಪೋರ್ಟ್ಫೋಲಿಯೊ ಅಪಾಯದೊಂದಿಗೆ ಗುರುತಿಸಲಾಗಿದೆ.
ಹವಾಮಾನ
ಒಂದೇ ಸರಾಸರಿ ಗರಿಷ್ಠ ದೈನಂದಿನ ತಾಪಮಾನ ಹೊಂದಿರುವ ಎರಡು ನಗರಗಳಿವೆ ಎಂದು ಭಾವಿಸೋಣ, ಆದರೆ ಒಂದು ಕರಾವಳಿಯಲ್ಲಿ ಮತ್ತು ಇನ್ನೊಂದು ಬಯಲಿನಲ್ಲಿದೆ. ಕರಾವಳಿಯಲ್ಲಿರುವ ನಗರಗಳು ಒಳನಾಡಿನ ನಗರಗಳಿಗಿಂತ ಕಡಿಮೆಯಿರುವ ಗರಿಷ್ಠ ಹಗಲಿನ ತಾಪಮಾನವನ್ನು ಹೊಂದಿವೆ ಎಂದು ತಿಳಿದಿದೆ. ಆದ್ದರಿಂದ, ಕರಾವಳಿ ನಗರಕ್ಕೆ ಗರಿಷ್ಠ ದೈನಂದಿನ ತಾಪಮಾನದ ಪ್ರಮಾಣಿತ ವಿಚಲನವು ಎರಡನೇ ನಗರಕ್ಕಿಂತ ಕಡಿಮೆಯಿರುತ್ತದೆ, ಈ ಮೌಲ್ಯದ ಸರಾಸರಿ ಮೌಲ್ಯವು ಒಂದೇ ಆಗಿರುತ್ತದೆ ಎಂಬ ವಾಸ್ತವದ ಹೊರತಾಗಿಯೂ, ಪ್ರಾಯೋಗಿಕವಾಗಿ ಇದರರ್ಥ ಗರಿಷ್ಠ ಗಾಳಿಯ ಉಷ್ಣತೆಯು ವರ್ಷದ ಯಾವುದೇ ದಿನವು ಸರಾಸರಿ ಮೌಲ್ಯಕ್ಕಿಂತ ಹೆಚ್ಚಾಗಿರುತ್ತದೆ, ಒಳನಾಡಿನ ನಗರಕ್ಕೆ ಹೆಚ್ಚಿನದಾಗಿರುತ್ತದೆ.
ಕ್ರೀಡೆ
ಕೆಲವು ಪ್ಯಾರಾಮೀಟರ್ಗಳ ಮೇಲೆ ರೇಟ್ ಮಾಡಲಾದ ಹಲವಾರು ಫುಟ್ಬಾಲ್ ತಂಡಗಳಿವೆ ಎಂದು ಭಾವಿಸೋಣ, ಉದಾಹರಣೆಗೆ, ಗಳಿಸಿದ ಮತ್ತು ಬಿಟ್ಟುಕೊಟ್ಟ ಗೋಲುಗಳ ಸಂಖ್ಯೆ, ಸ್ಕೋರಿಂಗ್ ಅವಕಾಶಗಳು ಇತ್ಯಾದಿ. ಈ ಗುಂಪಿನ ಅತ್ಯುತ್ತಮ ತಂಡವು ಉತ್ತಮ ಮೌಲ್ಯಗಳನ್ನು ಹೊಂದಿರುತ್ತದೆ. ಹೆಚ್ಚಿನ ನಿಯತಾಂಕಗಳಲ್ಲಿ. ಪ್ರಸ್ತುತಪಡಿಸಿದ ಪ್ರತಿಯೊಂದು ಪ್ಯಾರಾಮೀಟರ್ಗಳಿಗೆ ತಂಡದ ಪ್ರಮಾಣಿತ ವಿಚಲನವು ಚಿಕ್ಕದಾಗಿದೆ, ತಂಡದ ಫಲಿತಾಂಶವು ಹೆಚ್ಚು ಸಮತೋಲಿತವಾಗಿರುತ್ತದೆ; ಮತ್ತೊಂದೆಡೆ, ದೊಡ್ಡ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಹೊಂದಿರುವ ತಂಡವು ಫಲಿತಾಂಶವನ್ನು ಊಹಿಸಲು ಕಷ್ಟಕರವಾಗಿದೆ, ಇದು ಅಸಮತೋಲನದಿಂದ ವಿವರಿಸಲ್ಪಡುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ಬಲವಾದ ರಕ್ಷಣೆ ಆದರೆ ದುರ್ಬಲ ದಾಳಿ.
ತಂಡದ ನಿಯತಾಂಕಗಳ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಬಳಸುವುದರಿಂದ ಎರಡು ತಂಡಗಳ ನಡುವಿನ ಪಂದ್ಯದ ಫಲಿತಾಂಶವನ್ನು ಊಹಿಸಲು, ತಂಡಗಳ ಸಾಮರ್ಥ್ಯ ಮತ್ತು ದೌರ್ಬಲ್ಯಗಳನ್ನು ನಿರ್ಣಯಿಸಲು ಮತ್ತು ಆದ್ದರಿಂದ ಆಯ್ಕೆಮಾಡಿದ ಹೋರಾಟದ ವಿಧಾನಗಳನ್ನು ಒಂದು ಹಂತಕ್ಕೆ ಅಥವಾ ಇನ್ನೊಂದಕ್ಕೆ ಸಾಧ್ಯವಾಗಿಸುತ್ತದೆ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ
ವ್ಯತ್ಯಾಸದ ಅತ್ಯಂತ ಪರಿಪೂರ್ಣ ಲಕ್ಷಣವೆಂದರೆ ಸರಾಸರಿ ಚದರ ವಿಚಲನ, ಇದನ್ನು ಪ್ರಮಾಣಿತ (ಅಥವಾ ಪ್ರಮಾಣಿತ ವಿಚಲನ) ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ. ಪ್ರಮಾಣಿತ ವಿಚಲನ() ಅಂಕಗಣಿತದ ಸರಾಸರಿಯಿಂದ ಗುಣಲಕ್ಷಣದ ಪ್ರತ್ಯೇಕ ಮೌಲ್ಯಗಳ ಸರಾಸರಿ ವರ್ಗ ವಿಚಲನದ ವರ್ಗಮೂಲಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ:
ಪ್ರಮಾಣಿತ ವಿಚಲನ ಸರಳವಾಗಿದೆ:


ಗುಂಪು ಮಾಡಲಾದ ಡೇಟಾಗೆ ತೂಕದ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಅನ್ವಯಿಸಲಾಗುತ್ತದೆ:

ಸಾಮಾನ್ಯ ವಿತರಣಾ ಪರಿಸ್ಥಿತಿಗಳಲ್ಲಿ ಸರಾಸರಿ ವರ್ಗ ಮತ್ತು ಸರಾಸರಿ ರೇಖೀಯ ವಿಚಲನಗಳ ನಡುವೆ ಕೆಳಗಿನ ಅನುಪಾತವು ನಡೆಯುತ್ತದೆ: ~ 1.25.
ಸ್ಟ್ಯಾಂಡರ್ಡ್ ವಿಚಲನವು ವ್ಯತ್ಯಾಸದ ಮುಖ್ಯ ಸಂಪೂರ್ಣ ಅಳತೆಯಾಗಿದ್ದು, ಸಾಮಾನ್ಯ ವಿತರಣಾ ವಕ್ರರೇಖೆಯ ಆರ್ಡಿನೇಟ್ ಮೌಲ್ಯಗಳನ್ನು ನಿರ್ಧರಿಸಲು, ಮಾದರಿ ವೀಕ್ಷಣೆಯ ಸಂಘಟನೆಗೆ ಸಂಬಂಧಿಸಿದ ಲೆಕ್ಕಾಚಾರಗಳಲ್ಲಿ ಮತ್ತು ಮಾದರಿ ಗುಣಲಕ್ಷಣಗಳ ನಿಖರತೆಯನ್ನು ಸ್ಥಾಪಿಸುವಲ್ಲಿ ಬಳಸಲಾಗುತ್ತದೆ. ಏಕರೂಪದ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಗುಣಲಕ್ಷಣದ ವ್ಯತ್ಯಾಸದ ಮಿತಿಗಳು.
18. ವ್ಯತ್ಯಾಸ, ಅದರ ಪ್ರಕಾರಗಳು, ಪ್ರಮಾಣಿತ ವಿಚಲನ.
ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವ್ಯತ್ಯಾಸ- ಕೊಟ್ಟಿರುವ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಹರಡುವಿಕೆಯ ಅಳತೆ, ಅಂದರೆ ಗಣಿತದ ನಿರೀಕ್ಷೆಯಿಂದ ಅದರ ವಿಚಲನ. ಅಂಕಿಅಂಶಗಳಲ್ಲಿ, ಸಂಕೇತ ಅಥವಾ ಸಾಮಾನ್ಯವಾಗಿ ಬಳಸಲಾಗುತ್ತದೆ. ವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲವನ್ನು ಸಾಮಾನ್ಯವಾಗಿ ಕರೆಯಲಾಗುತ್ತದೆ ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಮಾಣಿತ ವಿಚಲನಅಥವಾ ಪ್ರಮಾಣಿತ ಹರಡುವಿಕೆ.
ಒಟ್ಟು ವ್ಯತ್ಯಾಸ (σ 2) ಈ ಬದಲಾವಣೆಗೆ ಕಾರಣವಾದ ಎಲ್ಲಾ ಅಂಶಗಳ ಪ್ರಭಾವದ ಅಡಿಯಲ್ಲಿ ಸಂಪೂರ್ಣವಾಗಿ ಗುಣಲಕ್ಷಣದ ವ್ಯತ್ಯಾಸವನ್ನು ಅಳೆಯುತ್ತದೆ. ಅದೇ ಸಮಯದಲ್ಲಿ, ಗುಂಪು ಮಾಡುವ ವಿಧಾನಕ್ಕೆ ಧನ್ಯವಾದಗಳು, ಗುಂಪಿನ ಗುಣಲಕ್ಷಣ ಮತ್ತು ಲೆಕ್ಕಿಸದ ಅಂಶಗಳ ಪ್ರಭಾವದ ಅಡಿಯಲ್ಲಿ ಉಂಟಾಗುವ ವ್ಯತ್ಯಾಸದಿಂದಾಗಿ ವ್ಯತ್ಯಾಸವನ್ನು ಗುರುತಿಸಲು ಮತ್ತು ಅಳೆಯಲು ಸಾಧ್ಯವಿದೆ.
ಅಂತರ ಗುಂಪು ವ್ಯತ್ಯಾಸ (σ 2 ಮಿ.ಗ್ರಾಂ) ವ್ಯವಸ್ಥಿತ ವ್ಯತ್ಯಾಸವನ್ನು ನಿರೂಪಿಸುತ್ತದೆ, ಅಂದರೆ ಗುಣಲಕ್ಷಣದ ಪ್ರಭಾವದ ಅಡಿಯಲ್ಲಿ ಉದ್ಭವಿಸುವ ಅಧ್ಯಯನ ಮಾಡಿದ ಗುಣಲಕ್ಷಣದ ಮೌಲ್ಯದಲ್ಲಿನ ವ್ಯತ್ಯಾಸಗಳು - ಗುಂಪಿನ ಆಧಾರವನ್ನು ರೂಪಿಸುವ ಅಂಶ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ(ಸಮಾನಾರ್ಥಕಗಳು: ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಚದರ ವಿಚಲನ; ಸಂಬಂಧಿತ ನಿಯಮಗಳು: ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಮಾಣಿತ ಹರಡುವಿಕೆ) - ಸಂಭವನೀಯತೆ ಸಿದ್ಧಾಂತ ಮತ್ತು ಅಂಕಿಅಂಶಗಳಲ್ಲಿ, ಅದರ ಗಣಿತದ ನಿರೀಕ್ಷೆಗೆ ಸಂಬಂಧಿಸಿದಂತೆ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಮೌಲ್ಯಗಳ ಪ್ರಸರಣದ ಸಾಮಾನ್ಯ ಸೂಚಕ. ಮೌಲ್ಯಗಳ ಮಾದರಿಗಳ ಸೀಮಿತ ಶ್ರೇಣಿಗಳೊಂದಿಗೆ, ಗಣಿತದ ನಿರೀಕ್ಷೆಯ ಬದಲಿಗೆ, ಮಾದರಿಗಳ ಗುಂಪಿನ ಅಂಕಗಣಿತದ ಸರಾಸರಿಯನ್ನು ಬಳಸಲಾಗುತ್ತದೆ.
ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯೇಬಲ್ನ ಮಾಪನದ ಘಟಕಗಳಲ್ಲಿ ಅಳೆಯಲಾಗುತ್ತದೆ ಮತ್ತು ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ, ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರಗಳನ್ನು ನಿರ್ಮಿಸುವಾಗ, ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯವಾಗಿ ಊಹೆಗಳನ್ನು ಪರೀಕ್ಷಿಸುವಾಗ, ಯಾದೃಚ್ಛಿಕ ಅಸ್ಥಿರಗಳ ನಡುವಿನ ರೇಖೀಯ ಸಂಬಂಧವನ್ನು ಅಳೆಯುವಾಗ ಬಳಸಲಾಗುತ್ತದೆ. ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲ ಎಂದು ವ್ಯಾಖ್ಯಾನಿಸಲಾಗಿದೆ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ:

ಪ್ರಮಾಣಿತ ವಿಚಲನ(ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಅಂದಾಜು Xಅದರ ವ್ಯತ್ಯಾಸದ ಪಕ್ಷಪಾತವಿಲ್ಲದ ಅಂದಾಜಿನ ಆಧಾರದ ಮೇಲೆ ಅದರ ಗಣಿತದ ನಿರೀಕ್ಷೆಗೆ ಸಂಬಂಧಿಸಿದಂತೆ):

ಪ್ರಸರಣ ಎಲ್ಲಿದೆ; - iಆಯ್ಕೆಯ ಅಂಶ; - ಮಾದರಿ ಅಳತೆ; - ಮಾದರಿಯ ಅಂಕಗಣಿತದ ಸರಾಸರಿ:

ಎರಡೂ ಅಂದಾಜುಗಳು ಪಕ್ಷಪಾತಿ ಎಂದು ಗಮನಿಸಬೇಕು. ಸಾಮಾನ್ಯ ಸಂದರ್ಭದಲ್ಲಿ, ಪಕ್ಷಪಾತವಿಲ್ಲದ ಅಂದಾಜನ್ನು ನಿರ್ಮಿಸುವುದು ಅಸಾಧ್ಯ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಪಕ್ಷಪಾತವಿಲ್ಲದ ವ್ಯತ್ಯಾಸದ ಅಂದಾಜಿನ ಆಧಾರದ ಮೇಲೆ ಅಂದಾಜು ಸ್ಥಿರವಾಗಿರುತ್ತದೆ.
19. ಮೋಡ್ ಮತ್ತು ಮೀಡಿಯನ್ ಅನ್ನು ನಿರ್ಧರಿಸಲು ಸಾರ, ವ್ಯಾಪ್ತಿ ಮತ್ತು ಕಾರ್ಯವಿಧಾನ.
ಅಂಕಿಅಂಶಗಳಲ್ಲಿನ ಶಕ್ತಿಯ ಸರಾಸರಿಗಳ ಜೊತೆಗೆ, ವಿಭಿನ್ನ ಗುಣಲಕ್ಷಣಗಳ ಮೌಲ್ಯ ಮತ್ತು ವಿತರಣಾ ಸರಣಿಯ ಆಂತರಿಕ ರಚನೆಯ ಸಾಪೇಕ್ಷ ಗುಣಲಕ್ಷಣಗಳಿಗಾಗಿ, ರಚನಾತ್ಮಕ ಸರಾಸರಿಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ, ಇವುಗಳನ್ನು ಮುಖ್ಯವಾಗಿ ಪ್ರತಿನಿಧಿಸಲಾಗುತ್ತದೆ ಫ್ಯಾಷನ್ ಮತ್ತು ಮಧ್ಯಮ.
ಫ್ಯಾಷನ್- ಇದು ಸರಣಿಯ ಅತ್ಯಂತ ಸಾಮಾನ್ಯ ರೂಪಾಂತರವಾಗಿದೆ. ಉದಾಹರಣೆಗೆ, ಗ್ರಾಹಕರಲ್ಲಿ ಹೆಚ್ಚಿನ ಬೇಡಿಕೆಯಲ್ಲಿರುವ ಬಟ್ಟೆ ಮತ್ತು ಬೂಟುಗಳ ಗಾತ್ರವನ್ನು ನಿರ್ಧರಿಸಲು ಫ್ಯಾಷನ್ ಅನ್ನು ಬಳಸಲಾಗುತ್ತದೆ. ಡಿಸ್ಕ್ರೀಟ್ ಸರಣಿಯ ಮೋಡ್ ಅತ್ಯಧಿಕ ಆವರ್ತನದೊಂದಿಗೆ ರೂಪಾಂತರವಾಗಿದೆ. ಮಧ್ಯಂತರ ವ್ಯತ್ಯಾಸ ಸರಣಿಗಾಗಿ ಮೋಡ್ ಅನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ, ಮೊದಲು ಮಾದರಿ ಮಧ್ಯಂತರವನ್ನು (ಗರಿಷ್ಠ ಆವರ್ತನದಿಂದ) ನಿರ್ಧರಿಸುವುದು ಬಹಳ ಮುಖ್ಯ, ಮತ್ತು ನಂತರ - ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಗುಣಲಕ್ಷಣದ ಮಾದರಿ ಮೌಲ್ಯದ ಮೌಲ್ಯ:

§ - ಫ್ಯಾಷನ್ ಅರ್ಥ
§ - ಮಾದರಿ ಮಧ್ಯಂತರದ ಕಡಿಮೆ ಮಿತಿ
§ - ಮಧ್ಯಂತರ ಮೌಲ್ಯ
§ - ಮಾದರಿ ಮಧ್ಯಂತರ ಆವರ್ತನ
§ - ಮಾದರಿಯ ಮುಂಚಿನ ಮಧ್ಯಂತರದ ಆವರ್ತನ
§ - ಮಾದರಿಯ ನಂತರದ ಮಧ್ಯಂತರದ ಆವರ್ತನ
ಮಧ್ಯಮ -ಗುಣಲಕ್ಷಣದ ಈ ಮೌಲ್ಯ, ĸᴏᴛᴏᴩᴏᴇ ಶ್ರೇಯಾಂಕಿತ ಸರಣಿಯ ಆಧಾರದ ಮೇಲೆ ಇರುತ್ತದೆ ಮತ್ತು ಈ ಸರಣಿಯನ್ನು ಸಂಖ್ಯೆಯಲ್ಲಿ ಸಮಾನವಾದ ಎರಡು ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುತ್ತದೆ.
ಸರಾಸರಿ ನಿರ್ಧರಿಸಲು ಒಂದು ಪ್ರತ್ಯೇಕ ಸರಣಿಯಲ್ಲಿಆವರ್ತನಗಳು ಲಭ್ಯವಿದ್ದರೆ, ಮೊದಲು ಆವರ್ತನಗಳ ಅರ್ಧ-ಮೊತ್ತವನ್ನು ಲೆಕ್ಕಹಾಕಿ, ತದನಂತರ ಯಾವ ರೂಪಾಂತರದ ಮೌಲ್ಯವು ಅದರ ಮೇಲೆ ಬೀಳುತ್ತದೆ ಎಂಬುದನ್ನು ನಿರ್ಧರಿಸಿ. (ವಿಂಗಡಿಸಿದ ಸರಣಿಯು ಬೆಸ ಸಂಖ್ಯೆಯ ಗುಣಲಕ್ಷಣಗಳನ್ನು ಹೊಂದಿದ್ದರೆ, ನಂತರ ಸರಾಸರಿ ಸಂಖ್ಯೆಯನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
M e = (n (ಒಟ್ಟು ವೈಶಿಷ್ಟ್ಯಗಳ ಸಂಖ್ಯೆ) + 1)/2,
ಸಮ ಸಂಖ್ಯೆಯ ವೈಶಿಷ್ಟ್ಯಗಳ ಸಂದರ್ಭದಲ್ಲಿ, ಸರಾಸರಿಯು ಸಾಲಿನ ಮಧ್ಯದಲ್ಲಿರುವ ಎರಡು ವೈಶಿಷ್ಟ್ಯಗಳ ಸರಾಸರಿಗೆ ಸಮನಾಗಿರುತ್ತದೆ).
ಸರಾಸರಿ ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ ಮಧ್ಯಂತರ ವ್ಯತ್ಯಾಸ ಸರಣಿಗಾಗಿಮೊದಲಿಗೆ, ಮಧ್ಯದ ಮಧ್ಯಂತರವನ್ನು ನಿರ್ಧರಿಸಿ, ನಂತರ ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಮಧ್ಯದ ಮೌಲ್ಯವನ್ನು ನಿರ್ಧರಿಸಿ:

§ - ಅಗತ್ಯವಿರುವ ಸರಾಸರಿ
§ - ಮಧ್ಯಂತರವನ್ನು ಒಳಗೊಂಡಿರುವ ಮಧ್ಯಂತರದ ಕಡಿಮೆ ಮಿತಿ
§ - ಮಧ್ಯಂತರ ಮೌಲ್ಯ
§ - ಆವರ್ತನಗಳ ಮೊತ್ತ ಅಥವಾ ಸರಣಿ ಪದಗಳ ಸಂಖ್ಯೆ
§ - ಮಧ್ಯದ ಹಿಂದಿನ ಮಧ್ಯಂತರಗಳ ಸಂಚಿತ ಆವರ್ತನಗಳ ಮೊತ್ತ
§ - ಸರಾಸರಿ ಮಧ್ಯಂತರದ ಆವರ್ತನ
ಉದಾಹರಣೆ. ಮೋಡ್ ಮತ್ತು ಮಧ್ಯಮವನ್ನು ಹುಡುಕಿ.
ಪರಿಹಾರ: ಈ ಉದಾಹರಣೆಯಲ್ಲಿ, ಮಾದರಿ ಮಧ್ಯಂತರವು 25-30 ವರ್ಷಗಳ ವಯಸ್ಸಿನೊಳಗೆ ಇರುತ್ತದೆ, ಏಕೆಂದರೆ ಈ ಮಧ್ಯಂತರವು ಅತ್ಯಧಿಕ ಆವರ್ತನವನ್ನು ಹೊಂದಿದೆ (1054).
ಮೋಡ್ನ ಪ್ರಮಾಣವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡೋಣ:
ಅಂದರೆ ವಿದ್ಯಾರ್ಥಿಗಳ ಮಾದರಿ ವಯಸ್ಸು 27 ವರ್ಷಗಳು.
ಸರಾಸರಿ ಲೆಕ್ಕಾಚಾರ ಮಾಡೋಣ. ಮಧ್ಯದ ಮಧ್ಯಂತರವು 25-30 ವರ್ಷಗಳ ವಯೋಮಾನದಲ್ಲಿದೆ, ಏಕೆಂದರೆ ಈ ಮಧ್ಯಂತರದಲ್ಲಿ ಜನಸಂಖ್ಯೆಯನ್ನು ಎರಡು ಸಮಾನ ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುವ ಒಂದು ಆಯ್ಕೆಯಿದೆ (Σf i /2 = 3462/2 = 1731). ಮುಂದೆ, ನಾವು ಸೂತ್ರಕ್ಕೆ ಅಗತ್ಯವಾದ ಸಂಖ್ಯಾತ್ಮಕ ಡೇಟಾವನ್ನು ಬದಲಿಸುತ್ತೇವೆ ಮತ್ತು ಸರಾಸರಿ ಮೌಲ್ಯವನ್ನು ಪಡೆಯುತ್ತೇವೆ:

ಅಂದರೆ ಅರ್ಧದಷ್ಟು ವಿದ್ಯಾರ್ಥಿಗಳು 27.4 ವರ್ಷಕ್ಕಿಂತ ಕಡಿಮೆ ವಯಸ್ಸಿನವರು ಮತ್ತು ಉಳಿದ ಅರ್ಧದಷ್ಟು ವಿದ್ಯಾರ್ಥಿಗಳು 27.4 ವರ್ಷಕ್ಕಿಂತ ಮೇಲ್ಪಟ್ಟವರು.
ಮೋಡ್ ಮತ್ತು ಮಧ್ಯದ ಜೊತೆಗೆ, ಕ್ವಾರ್ಟೈಲ್ಗಳಂತಹ ಸೂಚಕಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ, ಶ್ರೇಯಾಂಕಿತ ಸರಣಿಯನ್ನು 4 ಸಮಾನ ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುತ್ತದೆ, ಡೆಸಿಲ್ಗಳು - 10 ಭಾಗಗಳು ಮತ್ತು ಶೇಕಡಾವಾರು - 100 ಭಾಗಗಳಾಗಿ.
20. ಮಾದರಿ ವೀಕ್ಷಣೆಯ ಪರಿಕಲ್ಪನೆ ಮತ್ತು ಅದರ ವ್ಯಾಪ್ತಿ.
ಆಯ್ದ ವೀಕ್ಷಣೆನಿರಂತರ ಕಣ್ಗಾವಲು ಬಳಸುವಾಗ ಅನ್ವಯಿಸುತ್ತದೆ ದೈಹಿಕವಾಗಿ ಅಸಾಧ್ಯಹೆಚ್ಚಿನ ಪ್ರಮಾಣದ ಡೇಟಾದ ಕಾರಣದಿಂದಾಗಿ ಅಥವಾ ಆರ್ಥಿಕವಾಗಿ ಕಾರ್ಯಸಾಧ್ಯವಲ್ಲ. ಭೌತಿಕ ಅಸಾಧ್ಯತೆಯು ಸಂಭವಿಸುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ಪ್ರಯಾಣಿಕರ ಹರಿವುಗಳು, ಮಾರುಕಟ್ಟೆ ಬೆಲೆಗಳು ಮತ್ತು ಕುಟುಂಬದ ಬಜೆಟ್ಗಳನ್ನು ಅಧ್ಯಯನ ಮಾಡುವಾಗ. ಅವುಗಳ ವಿನಾಶಕ್ಕೆ ಸಂಬಂಧಿಸಿದ ಸರಕುಗಳ ಗುಣಮಟ್ಟವನ್ನು ನಿರ್ಣಯಿಸುವಾಗ ಆರ್ಥಿಕ ಅನನುಕೂಲತೆ ಸಂಭವಿಸುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ರುಚಿ, ಶಕ್ತಿಗಾಗಿ ಇಟ್ಟಿಗೆಗಳನ್ನು ಪರೀಕ್ಷಿಸುವುದು, ಇತ್ಯಾದಿ.
ವೀಕ್ಷಣೆಗಾಗಿ ಆಯ್ಕೆ ಮಾಡಲಾದ ಅಂಕಿಅಂಶಗಳ ಘಟಕಗಳು ಮಾದರಿ ಜನಸಂಖ್ಯೆಅಥವಾ ಮಾದರಿ, ಮತ್ತು ಅವರ ಸಂಪೂರ್ಣ ಶ್ರೇಣಿ - ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆ(ಜಿಎಸ್). ಇದರಲ್ಲಿ ಮಾದರಿಯಲ್ಲಿ ಘಟಕಗಳ ಸಂಖ್ಯೆಸೂಚಿಸುತ್ತವೆ ಎನ್, ಮತ್ತು ಸಂಪೂರ್ಣ GS ನಲ್ಲಿ - ಎನ್. ವರ್ತನೆ ಎನ್/ಎನ್ಸಾಮಾನ್ಯವಾಗಿ ಕರೆಯಲಾಗುತ್ತದೆ ಸಾಪೇಕ್ಷ ಗಾತ್ರಅಥವಾ ಮಾದರಿ ಪಾಲು.
ಮಾದರಿ ವೀಕ್ಷಣೆ ಫಲಿತಾಂಶಗಳ ಗುಣಮಟ್ಟವನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ ಮಾದರಿ ಪ್ರಾತಿನಿಧ್ಯ, ಅಂದರೆ, GS ನಲ್ಲಿ ಅದು ಹೇಗೆ ಪ್ರತಿನಿಧಿಸುತ್ತದೆ ಎಂಬುದರ ಮೇಲೆ. ಮಾದರಿಯ ಪ್ರಾತಿನಿಧ್ಯವನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು, ಅನುಸರಿಸುವುದು ಬಹಳ ಮುಖ್ಯ ಘಟಕಗಳ ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆಯ ತತ್ವ, ಮಾದರಿಯಲ್ಲಿ HS ಘಟಕದ ಸೇರ್ಪಡೆಯು ಅವಕಾಶವನ್ನು ಹೊರತುಪಡಿಸಿ ಯಾವುದೇ ಅಂಶದಿಂದ ಪ್ರಭಾವಿತವಾಗುವುದಿಲ್ಲ ಎಂದು ಊಹಿಸುತ್ತದೆ.
ಅಸ್ತಿತ್ವದಲ್ಲಿದೆ ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆಯ 4 ವಿಧಾನಗಳುಮಾದರಿಗೆ:
- ವಾಸ್ತವವಾಗಿ ಯಾದೃಚ್ಛಿಕಆಯ್ಕೆ ಅಥವಾ "ಲೊಟ್ಟೊ ವಿಧಾನ", ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮೌಲ್ಯಗಳನ್ನು ಸರಣಿ ಸಂಖ್ಯೆಗಳನ್ನು ನಿಗದಿಪಡಿಸಿದಾಗ, ಕೆಲವು ವಸ್ತುಗಳ ಮೇಲೆ ದಾಖಲಿಸಲಾಗುತ್ತದೆ (ಉದಾಹರಣೆಗೆ, ಬ್ಯಾರೆಲ್ಗಳು), ನಂತರ ಅದನ್ನು ಕಂಟೇನರ್ನಲ್ಲಿ (ಉದಾಹರಣೆಗೆ, ಚೀಲದಲ್ಲಿ) ಬೆರೆಸಲಾಗುತ್ತದೆ ಮತ್ತು ಯಾದೃಚ್ಛಿಕವಾಗಿ ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ. ಪ್ರಾಯೋಗಿಕವಾಗಿ, ಈ ವಿಧಾನವನ್ನು ಯಾದೃಚ್ಛಿಕ ಸಂಖ್ಯೆಯ ಜನರೇಟರ್ ಅಥವಾ ಯಾದೃಚ್ಛಿಕ ಸಂಖ್ಯೆಗಳ ಗಣಿತದ ಕೋಷ್ಟಕಗಳನ್ನು ಬಳಸಿ ನಡೆಸಲಾಗುತ್ತದೆ.
- ಯಾಂತ್ರಿಕಆಯ್ಕೆಯ ಪ್ರಕಾರ ಪ್ರತಿ ( ಎನ್/ಎನ್) - ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಮೌಲ್ಯ. ಉದಾಹರಣೆಗೆ, ಇದು 100,000 ಮೌಲ್ಯಗಳನ್ನು ಹೊಂದಿದ್ದರೆ ಮತ್ತು ನೀವು 1,000 ಅನ್ನು ಆಯ್ಕೆ ಮಾಡಬೇಕಾದರೆ, ಪ್ರತಿ 100,000 / 1000 = 100 ನೇ ಮೌಲ್ಯವನ್ನು ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲಾಗುತ್ತದೆ. ಇದಲ್ಲದೆ, ಅವರು ಶ್ರೇಣೀಕರಿಸದಿದ್ದರೆ, ಮೊದಲನೆಯದನ್ನು ಮೊದಲ ನೂರರಿಂದ ಯಾದೃಚ್ಛಿಕವಾಗಿ ಆಯ್ಕೆಮಾಡಲಾಗುತ್ತದೆ ಮತ್ತು ಇತರರ ಸಂಖ್ಯೆಗಳು ನೂರು ಹೆಚ್ಚಾಗಿರುತ್ತದೆ. ಉದಾಹರಣೆಗೆ, ಮೊದಲ ಘಟಕವು ಸಂಖ್ಯೆ 19 ಆಗಿದ್ದರೆ, ನಂತರದ ಸಂಖ್ಯೆ 119 ಆಗಿರಬೇಕು, ನಂತರ ಸಂಖ್ಯೆ 219, ನಂತರ ಸಂಖ್ಯೆ 319, ಇತ್ಯಾದಿ. ಜನಸಂಖ್ಯೆಯ ಘಟಕಗಳನ್ನು ಶ್ರೇಣೀಕರಿಸಿದರೆ, ನಂತರ ಸಂಖ್ಯೆ 50 ಅನ್ನು ಮೊದಲು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ, ನಂತರ ಸಂಖ್ಯೆ 150, ನಂತರ ಸಂಖ್ಯೆ 250, ಇತ್ಯಾದಿ.
- ವೈವಿಧ್ಯಮಯ ಡೇಟಾ ಶ್ರೇಣಿಯಿಂದ ಮೌಲ್ಯಗಳ ಆಯ್ಕೆಯನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ ಶ್ರೇಣೀಕೃತ(ಶ್ರೇಣೀಕೃತ) ವಿಧಾನ, ಜನಸಂಖ್ಯೆಯನ್ನು ಮೊದಲು ಏಕರೂಪದ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಿದಾಗ ಯಾದೃಚ್ಛಿಕ ಅಥವಾ ಯಾಂತ್ರಿಕ ಆಯ್ಕೆಯನ್ನು ಅನ್ವಯಿಸಲಾಗುತ್ತದೆ.
- ವಿಶೇಷ ಮಾದರಿ ವಿಧಾನವಾಗಿದೆ ಧಾರಾವಾಹಿಆಯ್ಕೆ, ಇದರಲ್ಲಿ ಅವರು ಯಾದೃಚ್ಛಿಕವಾಗಿ ಅಥವಾ ಯಾಂತ್ರಿಕವಾಗಿ ವೈಯಕ್ತಿಕ ಮೌಲ್ಯಗಳನ್ನು ಆಯ್ಕೆಮಾಡುವುದಿಲ್ಲ, ಆದರೆ ಅವುಗಳ ಸರಣಿ (ಕೆಲವು ಸಂಖ್ಯೆಯಿಂದ ಸತತವಾಗಿ ಕೆಲವು ಸಂಖ್ಯೆಗಳಿಗೆ ಅನುಕ್ರಮಗಳು), ಅದರೊಳಗೆ ನಿರಂತರ ವೀಕ್ಷಣೆಯನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ.
ಮಾದರಿ ಅವಲೋಕನಗಳ ಗುಣಮಟ್ಟವು ಸಹ ಅವಲಂಬಿಸಿರುತ್ತದೆ ಮಾದರಿ ಪ್ರಕಾರ: ಪುನರಾವರ್ತನೆಯಾಯಿತುಅಥವಾ ಪುನರಾವರ್ತಿಸಲಾಗದ.ನಲ್ಲಿ ಮರು ಆಯ್ಕೆಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲಾದ ಅಂಕಿಅಂಶಗಳ ಮೌಲ್ಯಗಳು ಅಥವಾ ಅವುಗಳ ಸರಣಿಯನ್ನು ಹೊಸ ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲು ಅವಕಾಶವನ್ನು ಹೊಂದಿರುವ ಬಳಕೆಯ ನಂತರ ಸಾಮಾನ್ಯ ಜನರಿಗೆ ಹಿಂತಿರುಗಿಸಲಾಗುತ್ತದೆ. ಇದಲ್ಲದೆ, ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಎಲ್ಲಾ ಮೌಲ್ಯಗಳು ಮಾದರಿಯಲ್ಲಿ ಸೇರ್ಪಡೆಗೊಳ್ಳುವ ಒಂದೇ ಸಂಭವನೀಯತೆಯನ್ನು ಹೊಂದಿವೆ. ಪುನರಾವರ್ತನೆಯಿಲ್ಲದ ಆಯ್ಕೆಅಂದರೆ ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲಾದ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮೌಲ್ಯಗಳು ಅಥವಾ ಅವುಗಳ ಸರಣಿಗಳು ಬಳಕೆಯ ನಂತರ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಗೆ ಹಿಂತಿರುಗುವುದಿಲ್ಲ ಮತ್ತು ಆದ್ದರಿಂದ ನಂತರದ ಉಳಿದ ಮೌಲ್ಯಗಳಿಗೆ ಮುಂದಿನ ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸುವ ಸಂಭವನೀಯತೆಯು ಹೆಚ್ಚಾಗುತ್ತದೆ.
ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿಯು ಹೆಚ್ಚು ನಿಖರವಾದ ಫಲಿತಾಂಶಗಳನ್ನು ನೀಡುತ್ತದೆ ಮತ್ತು ಆದ್ದರಿಂದ ಇದನ್ನು ಹೆಚ್ಚಾಗಿ ಬಳಸಲಾಗುತ್ತದೆ. ಆದರೆ ಅದನ್ನು ಅನ್ವಯಿಸಲಾಗದ ಸಂದರ್ಭಗಳಿವೆ (ಪ್ರಯಾಣಿಕರ ಹರಿವು, ಗ್ರಾಹಕರ ಬೇಡಿಕೆ, ಇತ್ಯಾದಿಗಳನ್ನು ಅಧ್ಯಯನ ಮಾಡುವುದು) ಮತ್ತು ನಂತರ ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆಯನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ.
21. ಗರಿಷ್ಠ ವೀಕ್ಷಣೆ ಮಾದರಿ ದೋಷ, ಸರಾಸರಿ ಮಾದರಿ ದೋಷ, ಅವುಗಳ ಲೆಕ್ಕಾಚಾರದ ಕಾರ್ಯವಿಧಾನ.
ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ರೂಪಿಸಲು ಮೇಲೆ ಪಟ್ಟಿ ಮಾಡಲಾದ ವಿಧಾನಗಳು ಮತ್ತು ಉದ್ಭವಿಸುವ ಪ್ರಾತಿನಿಧ್ಯ ದೋಷಗಳನ್ನು ನಾವು ವಿವರವಾಗಿ ಪರಿಗಣಿಸೋಣ. ಸರಿಯಾಗಿ ಯಾದೃಚ್ಛಿಕಮಾದರಿಯು ಯಾವುದೇ ವ್ಯವಸ್ಥಿತ ಅಂಶಗಳಿಲ್ಲದೆ ಯಾದೃಚ್ಛಿಕವಾಗಿ ಜನಸಂಖ್ಯೆಯಿಂದ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆಮಾಡುವುದರ ಮೇಲೆ ಆಧಾರಿತವಾಗಿದೆ. ತಾಂತ್ರಿಕವಾಗಿ, ನಿಜವಾದ ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆಯನ್ನು ಸಾಕಷ್ಟು ಡ್ರಾಯಿಂಗ್ ಮೂಲಕ (ಉದಾಹರಣೆಗೆ, ಲಾಟರಿಗಳು) ಅಥವಾ ಯಾದೃಚ್ಛಿಕ ಸಂಖ್ಯೆಗಳ ಕೋಷ್ಟಕವನ್ನು ಬಳಸಿಕೊಂಡು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ.
"ಅದರ ಶುದ್ಧ ರೂಪದಲ್ಲಿ" ಸರಿಯಾದ ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆಯು ಆಯ್ದ ವೀಕ್ಷಣೆಯ ಅಭ್ಯಾಸದಲ್ಲಿ ವಿರಳವಾಗಿ ಬಳಸಲ್ಪಡುತ್ತದೆ, ಆದರೆ ಇದು ಆಯ್ದ ವೀಕ್ಷಣೆಯ ಮೂಲಭೂತ ತತ್ವಗಳನ್ನು ಕಾರ್ಯಗತಗೊಳಿಸುತ್ತದೆ. ಮಾದರಿ ವಿಧಾನದ ಸಿದ್ಧಾಂತದ ಕೆಲವು ಪ್ರಶ್ನೆಗಳನ್ನು ಮತ್ತು ಸರಳವಾದ ಯಾದೃಚ್ಛಿಕ ಮಾದರಿಗಾಗಿ ದೋಷ ಸೂತ್ರವನ್ನು ಪರಿಗಣಿಸೋಣ.
ಮಾದರಿ ಪಕ್ಷಪಾತ- ϶ᴛᴏ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ನಿಯತಾಂಕದ ಮೌಲ್ಯ ಮತ್ತು ಮಾದರಿ ವೀಕ್ಷಣೆಯ ಫಲಿತಾಂಶಗಳಿಂದ ಲೆಕ್ಕಹಾಕಿದ ಅದರ ಮೌಲ್ಯದ ನಡುವಿನ ವ್ಯತ್ಯಾಸ. ಸರಾಸರಿ ಪರಿಮಾಣಾತ್ಮಕ ಗುಣಲಕ್ಷಣಕ್ಕಾಗಿ ಮಾದರಿ ದೋಷವನ್ನು ನಿರ್ಧರಿಸಲಾಗುತ್ತದೆ ಎಂಬುದನ್ನು ಗಮನಿಸುವುದು ಮುಖ್ಯ
ಸೂಚಕವನ್ನು ಸಾಮಾನ್ಯವಾಗಿ ಗರಿಷ್ಠ ಮಾದರಿ ದೋಷ ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ. ಮಾದರಿ ಸರಾಸರಿಯು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಆಗಿದ್ದು ಅದು ಮಾದರಿಯಲ್ಲಿ ಯಾವ ಘಟಕಗಳನ್ನು ಸೇರಿಸಲಾಗಿದೆ ಎಂಬುದರ ಆಧಾರದ ಮೇಲೆ ವಿಭಿನ್ನ ಮೌಲ್ಯಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು. ಆದ್ದರಿಂದ, ಮಾದರಿ ದೋಷಗಳು ಸಹ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ಗಳಾಗಿವೆ ಮತ್ತು ವಿಭಿನ್ನ ಮೌಲ್ಯಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು. ಈ ಕಾರಣಕ್ಕಾಗಿ, ಸಂಭವನೀಯ ದೋಷಗಳ ಸರಾಸರಿಯನ್ನು ನಿರ್ಧರಿಸಲಾಗುತ್ತದೆ - ಸರಾಸರಿ ಮಾದರಿ ದೋಷ, ಇದು ಅವಲಂಬಿಸಿರುತ್ತದೆ:
· ಮಾದರಿ ಗಾತ್ರ: ದೊಡ್ಡ ಸಂಖ್ಯೆ, ಸಣ್ಣ ಸರಾಸರಿ ದೋಷ;
· ಅಧ್ಯಯನ ಮಾಡಲಾದ ಗುಣಲಕ್ಷಣದಲ್ಲಿನ ಬದಲಾವಣೆಯ ಮಟ್ಟ: ಗುಣಲಕ್ಷಣದ ವ್ಯತ್ಯಾಸವು ಚಿಕ್ಕದಾಗಿದೆ, ಮತ್ತು ಪರಿಣಾಮವಾಗಿ, ಪ್ರಸರಣ, ಸರಾಸರಿ ಮಾದರಿ ದೋಷವು ಚಿಕ್ಕದಾಗಿದೆ.
ನಲ್ಲಿ ಯಾದೃಚ್ಛಿಕ ಮರು ಆಯ್ಕೆಸರಾಸರಿ ದೋಷವನ್ನು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ. ಪ್ರಾಯೋಗಿಕವಾಗಿ, ಸಾಮಾನ್ಯ ವ್ಯತ್ಯಾಸವು ನಿಖರವಾಗಿ ತಿಳಿದಿಲ್ಲ, ಆದರೆ ಸಂಭವನೀಯತೆ ಸಿದ್ಧಾಂತದಲ್ಲಿ ಅದು ಸಾಬೀತಾಗಿದೆ
 . ಸಾಕಷ್ಟು ದೊಡ್ಡದಾದ n ನ ಮೌಲ್ಯವು 1 ಕ್ಕೆ ಹತ್ತಿರವಾಗಿರುವುದರಿಂದ, ನಾವು ಅದನ್ನು ಊಹಿಸಬಹುದು. ನಂತರ ಸರಾಸರಿ ಮಾದರಿ ದೋಷವನ್ನು ಲೆಕ್ಕ ಹಾಕಬೇಕು: . ಆದರೆ ಸಣ್ಣ ಮಾದರಿಯ ಸಂದರ್ಭಗಳಲ್ಲಿ (n ಜೊತೆಗೆ<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. ಸಾಕಷ್ಟು ದೊಡ್ಡದಾದ n ನ ಮೌಲ್ಯವು 1 ಕ್ಕೆ ಹತ್ತಿರವಾಗಿರುವುದರಿಂದ, ನಾವು ಅದನ್ನು ಊಹಿಸಬಹುದು. ನಂತರ ಸರಾಸರಿ ಮಾದರಿ ದೋಷವನ್ನು ಲೆಕ್ಕ ಹಾಕಬೇಕು: . ಆದರೆ ಸಣ್ಣ ಮಾದರಿಯ ಸಂದರ್ಭಗಳಲ್ಲಿ (n ಜೊತೆಗೆ<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.ನಲ್ಲಿ ಯಾದೃಚ್ಛಿಕ ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿಕೊಟ್ಟಿರುವ ಸೂತ್ರಗಳನ್ನು ಮೌಲ್ಯದಿಂದ ಸರಿಹೊಂದಿಸಲಾಗುತ್ತದೆ. ನಂತರ ಸರಾಸರಿ ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿ ದೋಷ:
 ಮತ್ತು
ಮತ್ತು  . ಏಕೆಂದರೆ ಗಿಂತ ಯಾವಾಗಲೂ ಕಡಿಮೆ ಇರುತ್ತದೆ, ನಂತರ ಗುಣಕ () ಯಾವಾಗಲೂ 1 ಕ್ಕಿಂತ ಕಡಿಮೆಯಿರುತ್ತದೆ. ಇದರರ್ಥ ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆಯೊಂದಿಗೆ ಸರಾಸರಿ ದೋಷವು ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆಗಿಂತ ಯಾವಾಗಲೂ ಕಡಿಮೆ ಇರುತ್ತದೆ. ಯಾಂತ್ರಿಕ ಮಾದರಿಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಕೆಲವು ರೀತಿಯಲ್ಲಿ ಆದೇಶಿಸಿದಾಗ ಬಳಸಲಾಗುತ್ತದೆ (ಉದಾಹರಣೆಗೆ, ವರ್ಣಮಾಲೆಯ ಕ್ರಮದಲ್ಲಿ ಮತದಾರರ ಪಟ್ಟಿಗಳು, ದೂರವಾಣಿ ಸಂಖ್ಯೆಗಳು, ಮನೆ ಮತ್ತು ಅಪಾರ್ಟ್ಮೆಂಟ್ ಸಂಖ್ಯೆಗಳು). ಘಟಕಗಳ ಆಯ್ಕೆಯನ್ನು ನಿರ್ದಿಷ್ಟ ಮಧ್ಯಂತರದಲ್ಲಿ ನಡೆಸಲಾಗುತ್ತದೆ, ಇದು ಮಾದರಿ ಶೇಕಡಾವಾರು ವಿಲೋಮ ಮೌಲ್ಯಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ. ಆದ್ದರಿಂದ, 2% ಮಾದರಿಯೊಂದಿಗೆ, ಪ್ರತಿ 50 ಘಟಕ = 1/0.02 ಅನ್ನು ಆಯ್ಕೆಮಾಡಲಾಗುತ್ತದೆ, 5% ಮಾದರಿಯೊಂದಿಗೆ, ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಪ್ರತಿ 1/0.05 = 20 ಯೂನಿಟ್.
. ಏಕೆಂದರೆ ಗಿಂತ ಯಾವಾಗಲೂ ಕಡಿಮೆ ಇರುತ್ತದೆ, ನಂತರ ಗುಣಕ () ಯಾವಾಗಲೂ 1 ಕ್ಕಿಂತ ಕಡಿಮೆಯಿರುತ್ತದೆ. ಇದರರ್ಥ ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆಯೊಂದಿಗೆ ಸರಾಸರಿ ದೋಷವು ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆಗಿಂತ ಯಾವಾಗಲೂ ಕಡಿಮೆ ಇರುತ್ತದೆ. ಯಾಂತ್ರಿಕ ಮಾದರಿಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಕೆಲವು ರೀತಿಯಲ್ಲಿ ಆದೇಶಿಸಿದಾಗ ಬಳಸಲಾಗುತ್ತದೆ (ಉದಾಹರಣೆಗೆ, ವರ್ಣಮಾಲೆಯ ಕ್ರಮದಲ್ಲಿ ಮತದಾರರ ಪಟ್ಟಿಗಳು, ದೂರವಾಣಿ ಸಂಖ್ಯೆಗಳು, ಮನೆ ಮತ್ತು ಅಪಾರ್ಟ್ಮೆಂಟ್ ಸಂಖ್ಯೆಗಳು). ಘಟಕಗಳ ಆಯ್ಕೆಯನ್ನು ನಿರ್ದಿಷ್ಟ ಮಧ್ಯಂತರದಲ್ಲಿ ನಡೆಸಲಾಗುತ್ತದೆ, ಇದು ಮಾದರಿ ಶೇಕಡಾವಾರು ವಿಲೋಮ ಮೌಲ್ಯಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ. ಆದ್ದರಿಂದ, 2% ಮಾದರಿಯೊಂದಿಗೆ, ಪ್ರತಿ 50 ಘಟಕ = 1/0.02 ಅನ್ನು ಆಯ್ಕೆಮಾಡಲಾಗುತ್ತದೆ, 5% ಮಾದರಿಯೊಂದಿಗೆ, ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಪ್ರತಿ 1/0.05 = 20 ಯೂನಿಟ್.ಉಲ್ಲೇಖ ಬಿಂದುವನ್ನು ವಿವಿಧ ರೀತಿಯಲ್ಲಿ ಆಯ್ಕೆಮಾಡಲಾಗಿದೆ: ಯಾದೃಚ್ಛಿಕವಾಗಿ, ಮಧ್ಯಂತರದ ಮಧ್ಯದಿಂದ, ಉಲ್ಲೇಖ ಬಿಂದುವಿನ ಬದಲಾವಣೆಯೊಂದಿಗೆ. ವ್ಯವಸ್ಥಿತ ದೋಷಗಳನ್ನು ತಪ್ಪಿಸುವುದು ಮುಖ್ಯ ವಿಷಯ. ಉದಾಹರಣೆಗೆ, 5% ಮಾದರಿಯೊಂದಿಗೆ, ಮೊದಲ ಘಟಕವು 13 ನೇ ಆಗಿದ್ದರೆ, ನಂತರದವುಗಳು 33, 53, 73, ಇತ್ಯಾದಿ.
ನಿಖರತೆಯ ವಿಷಯದಲ್ಲಿ, ಯಾಂತ್ರಿಕ ಆಯ್ಕೆಯು ನಿಜವಾದ ಯಾದೃಚ್ಛಿಕ ಮಾದರಿಗೆ ಹತ್ತಿರದಲ್ಲಿದೆ. ಈ ಕಾರಣಕ್ಕಾಗಿ, ಯಾಂತ್ರಿಕ ಮಾದರಿಯ ಸರಾಸರಿ ದೋಷವನ್ನು ನಿರ್ಧರಿಸಲು, ಸರಿಯಾದ ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆ ಸೂತ್ರಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ.
ನಲ್ಲಿ ವಿಶಿಷ್ಟ ಆಯ್ಕೆಸಮೀಕ್ಷೆ ಮಾಡಲಾದ ಜನಸಂಖ್ಯೆಯನ್ನು ಪ್ರಾಥಮಿಕವಾಗಿ ಏಕರೂಪದ, ಒಂದೇ ರೀತಿಯ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ. ಉದಾಹರಣೆಗೆ, ಉದ್ಯಮಗಳನ್ನು ಸಮೀಕ್ಷೆ ಮಾಡುವಾಗ, ಇವುಗಳು ಉದ್ಯಮಗಳು, ಜನಸಂಖ್ಯೆಯನ್ನು ಅಧ್ಯಯನ ಮಾಡುವಾಗ ಉಪ-ವಲಯಗಳು, ಇವು ಪ್ರದೇಶಗಳು, ಸಾಮಾಜಿಕ ಅಥವಾ ವಯಸ್ಸಿನ ಗುಂಪುಗಳು. ಮುಂದೆ, ಪ್ರತಿ ಗುಂಪಿನಿಂದ ಸ್ವತಂತ್ರ ಆಯ್ಕೆಯನ್ನು ಯಾಂತ್ರಿಕವಾಗಿ ಅಥವಾ ಸಂಪೂರ್ಣವಾಗಿ ಯಾದೃಚ್ಛಿಕವಾಗಿ ಮಾಡಲಾಗುತ್ತದೆ.
ವಿಶಿಷ್ಟ ಮಾದರಿಯು ಇತರ ವಿಧಾನಗಳಿಗಿಂತ ಹೆಚ್ಚು ನಿಖರವಾದ ಫಲಿತಾಂಶಗಳನ್ನು ನೀಡುತ್ತದೆ. ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಟೈಪ್ ಮಾಡುವುದರಿಂದ ಪ್ರತಿ ಟೈಪೊಲಾಜಿಕಲ್ ಗುಂಪನ್ನು ಮಾದರಿಯಲ್ಲಿ ಪ್ರತಿನಿಧಿಸಲಾಗಿದೆ ಎಂದು ಖಚಿತಪಡಿಸುತ್ತದೆ, ಇದು ಸರಾಸರಿ ಮಾದರಿ ದೋಷದ ಮೇಲೆ ಇಂಟರ್ಗ್ರೂಪ್ ವ್ಯತ್ಯಾಸದ ಪ್ರಭಾವವನ್ನು ತೊಡೆದುಹಾಕಲು ಸಾಧ್ಯವಾಗಿಸುತ್ತದೆ. ಆದ್ದರಿಂದ, ವ್ಯತ್ಯಾಸಗಳನ್ನು () ಸೇರಿಸುವ ನಿಯಮದ ಪ್ರಕಾರ ವಿಶಿಷ್ಟ ಮಾದರಿಯ ದೋಷವನ್ನು ಕಂಡುಹಿಡಿಯುವಾಗ, ಗುಂಪಿನ ವ್ಯತ್ಯಾಸಗಳ ಸರಾಸರಿಯನ್ನು ಮಾತ್ರ ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುವುದು ಬಹಳ ಮುಖ್ಯ. ನಂತರ ಸರಾಸರಿ ಮಾದರಿ ದೋಷ: ಪುನರಾವರ್ತಿತ ಮಾದರಿಯೊಂದಿಗೆ, ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿಯೊಂದಿಗೆ
 , ಎಲ್ಲಿ
, ಎಲ್ಲಿ  - ಮಾದರಿಯಲ್ಲಿನ ಗುಂಪಿನೊಳಗಿನ ವ್ಯತ್ಯಾಸಗಳ ಸರಾಸರಿ.
- ಮಾದರಿಯಲ್ಲಿನ ಗುಂಪಿನೊಳಗಿನ ವ್ಯತ್ಯಾಸಗಳ ಸರಾಸರಿ.ಸರಣಿ (ಅಥವಾ ಗೂಡು) ಆಯ್ಕೆಮಾದರಿ ಸಮೀಕ್ಷೆಯ ಪ್ರಾರಂಭದ ಮೊದಲು ಜನಸಂಖ್ಯೆಯನ್ನು ಸರಣಿ ಅಥವಾ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಿದಾಗ ಬಳಸಲಾಗುತ್ತದೆ. ಈ ಸರಣಿಗಳಲ್ಲಿ ಸಿದ್ಧಪಡಿಸಿದ ಉತ್ಪನ್ನಗಳ ಪ್ಯಾಕೇಜಿಂಗ್, ವಿದ್ಯಾರ್ಥಿ ಗುಂಪುಗಳು ಮತ್ತು ಬ್ರಿಗೇಡ್ಗಳು ಸೇರಿವೆ. ಪರೀಕ್ಷೆಗಾಗಿ ಸರಣಿಗಳನ್ನು ಯಾಂತ್ರಿಕವಾಗಿ ಅಥವಾ ಸಂಪೂರ್ಣವಾಗಿ ಯಾದೃಚ್ಛಿಕವಾಗಿ ಆಯ್ಕೆಮಾಡಲಾಗುತ್ತದೆ ಮತ್ತು ಸರಣಿಯೊಳಗೆ ಘಟಕಗಳ ನಿರಂತರ ಪರೀಕ್ಷೆಯನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ. ಈ ಕಾರಣಕ್ಕಾಗಿ, ಸರಾಸರಿ ಮಾದರಿ ದೋಷವು ಇಂಟರ್ಗ್ರೂಪ್ (ಸರಣಿಗಳ ನಡುವೆ) ವ್ಯತ್ಯಾಸದ ಮೇಲೆ ಮಾತ್ರ ಅವಲಂಬಿತವಾಗಿರುತ್ತದೆ, ಇದನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
 ಇಲ್ಲಿ r ಎಂಬುದು ಆಯ್ದ ಸರಣಿಗಳ ಸಂಖ್ಯೆ; - i-th ಸರಣಿಯ ಸರಾಸರಿ. ಸರಣಿ ಮಾದರಿಯ ಸರಾಸರಿ ದೋಷವನ್ನು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ: ಪುನರಾವರ್ತಿತ ಮಾದರಿಯೊಂದಿಗೆ, ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿಯೊಂದಿಗೆ
ಇಲ್ಲಿ r ಎಂಬುದು ಆಯ್ದ ಸರಣಿಗಳ ಸಂಖ್ಯೆ; - i-th ಸರಣಿಯ ಸರಾಸರಿ. ಸರಣಿ ಮಾದರಿಯ ಸರಾಸರಿ ದೋಷವನ್ನು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ: ಪುನರಾವರ್ತಿತ ಮಾದರಿಯೊಂದಿಗೆ, ಪುನರಾವರ್ತಿತವಲ್ಲದ ಮಾದರಿಯೊಂದಿಗೆ  , ಇಲ್ಲಿ R ಎಂಬುದು ಸರಣಿಯ ಒಟ್ಟು ಸಂಖ್ಯೆ. ಸಂಯೋಜಿತಆಯ್ಕೆಯು ಪರಿಗಣಿಸಲಾದ ಆಯ್ಕೆ ವಿಧಾನಗಳ ಸಂಯೋಜನೆಯಾಗಿದೆ.
, ಇಲ್ಲಿ R ಎಂಬುದು ಸರಣಿಯ ಒಟ್ಟು ಸಂಖ್ಯೆ. ಸಂಯೋಜಿತಆಯ್ಕೆಯು ಪರಿಗಣಿಸಲಾದ ಆಯ್ಕೆ ವಿಧಾನಗಳ ಸಂಯೋಜನೆಯಾಗಿದೆ.ಯಾವುದೇ ಮಾದರಿ ವಿಧಾನದ ಸರಾಸರಿ ಮಾದರಿ ದೋಷವು ಮುಖ್ಯವಾಗಿ ಮಾದರಿಯ ಸಂಪೂರ್ಣ ಗಾತ್ರವನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ ಮತ್ತು ಸ್ವಲ್ಪ ಮಟ್ಟಿಗೆ, ಮಾದರಿಯ ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ. ಮೊದಲ ಪ್ರಕರಣದಲ್ಲಿ 4,500 ಯೂನಿಟ್ಗಳ ಜನಸಂಖ್ಯೆಯಿಂದ ಮತ್ತು ಎರಡನೆಯದರಲ್ಲಿ 225,000 ಯುನಿಟ್ಗಳ ಜನಸಂಖ್ಯೆಯಿಂದ 225 ವೀಕ್ಷಣೆಗಳನ್ನು ಮಾಡಲಾಗಿದೆ ಎಂದು ನಾವು ಊಹಿಸೋಣ. ಎರಡೂ ಸಂದರ್ಭಗಳಲ್ಲಿನ ವ್ಯತ್ಯಾಸಗಳು 25 ಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ. ನಂತರ ಮೊದಲ ಸಂದರ್ಭದಲ್ಲಿ, 5% ಆಯ್ಕೆಯೊಂದಿಗೆ, ಮಾದರಿ ದೋಷವು ಹೀಗಿರುತ್ತದೆ:
 ಎರಡನೆಯ ಸಂದರ್ಭದಲ್ಲಿ, 0.1% ಆಯ್ಕೆಯೊಂದಿಗೆ, ಇದು ಸಮಾನವಾಗಿರುತ್ತದೆ:
ಎರಡನೆಯ ಸಂದರ್ಭದಲ್ಲಿ, 0.1% ಆಯ್ಕೆಯೊಂದಿಗೆ, ಇದು ಸಮಾನವಾಗಿರುತ್ತದೆ: ಆದಾಗ್ಯೂ, ಮಾದರಿಯ ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವನ್ನು 50 ಪಟ್ಟು ಕಡಿಮೆಗೊಳಿಸಿದಾಗ, ಮಾದರಿಯ ಗಾತ್ರವು ಬದಲಾಗದ ಕಾರಣ ಮಾದರಿ ದೋಷವು ಸ್ವಲ್ಪಮಟ್ಟಿಗೆ ಹೆಚ್ಚಾಯಿತು. ಮಾದರಿ ಗಾತ್ರವನ್ನು 625 ವೀಕ್ಷಣೆಗಳಿಗೆ ಹೆಚ್ಚಿಸಲಾಗಿದೆ ಎಂದು ಭಾವಿಸೋಣ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಮಾದರಿ ದೋಷವು ಹೀಗಿರುತ್ತದೆ:
ಆದಾಗ್ಯೂ, ಮಾದರಿಯ ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವನ್ನು 50 ಪಟ್ಟು ಕಡಿಮೆಗೊಳಿಸಿದಾಗ, ಮಾದರಿಯ ಗಾತ್ರವು ಬದಲಾಗದ ಕಾರಣ ಮಾದರಿ ದೋಷವು ಸ್ವಲ್ಪಮಟ್ಟಿಗೆ ಹೆಚ್ಚಾಯಿತು. ಮಾದರಿ ಗಾತ್ರವನ್ನು 625 ವೀಕ್ಷಣೆಗಳಿಗೆ ಹೆಚ್ಚಿಸಲಾಗಿದೆ ಎಂದು ಭಾವಿಸೋಣ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಮಾದರಿ ದೋಷವು ಹೀಗಿರುತ್ತದೆ:  ಅದೇ ಜನಸಂಖ್ಯೆಯ ಗಾತ್ರದೊಂದಿಗೆ ಮಾದರಿಯನ್ನು 2.8 ಪಟ್ಟು ಹೆಚ್ಚಿಸುವುದರಿಂದ ಮಾದರಿ ದೋಷದ ಗಾತ್ರವನ್ನು 1.6 ಪಟ್ಟು ಹೆಚ್ಚು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ.
ಅದೇ ಜನಸಂಖ್ಯೆಯ ಗಾತ್ರದೊಂದಿಗೆ ಮಾದರಿಯನ್ನು 2.8 ಪಟ್ಟು ಹೆಚ್ಚಿಸುವುದರಿಂದ ಮಾದರಿ ದೋಷದ ಗಾತ್ರವನ್ನು 1.6 ಪಟ್ಟು ಹೆಚ್ಚು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ.22. ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ರೂಪಿಸುವ ವಿಧಾನಗಳು ಮತ್ತು ವಿಧಾನಗಳು.
ಅಂಕಿಅಂಶಗಳಲ್ಲಿ, ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ರೂಪಿಸುವ ವಿವಿಧ ವಿಧಾನಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ, ಇದು ಅಧ್ಯಯನದ ಉದ್ದೇಶಗಳಿಂದ ನಿರ್ಧರಿಸಲ್ಪಡುತ್ತದೆ ಮತ್ತು ಅಧ್ಯಯನದ ವಸ್ತುವಿನ ನಿಶ್ಚಿತಗಳನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ.
ಮಾದರಿ ಸಮೀಕ್ಷೆಯನ್ನು ನಡೆಸುವ ಮುಖ್ಯ ಷರತ್ತು ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಪ್ರತಿ ಘಟಕವನ್ನು ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲು ಸಮಾನ ಅವಕಾಶದ ತತ್ವದ ಉಲ್ಲಂಘನೆಯಿಂದ ಉಂಟಾಗುವ ವ್ಯವಸ್ಥಿತ ದೋಷಗಳ ಸಂಭವವನ್ನು ತಡೆಗಟ್ಟುವುದು. ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ರೂಪಿಸಲು ವೈಜ್ಞಾನಿಕವಾಗಿ ಆಧಾರಿತ ವಿಧಾನಗಳ ಬಳಕೆಯ ಮೂಲಕ ವ್ಯವಸ್ಥಿತ ದೋಷಗಳ ತಡೆಗಟ್ಟುವಿಕೆಯನ್ನು ಸಾಧಿಸಲಾಗುತ್ತದೆ.
ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲು ಕೆಳಗಿನ ವಿಧಾನಗಳಿವೆ: 1) ವೈಯಕ್ತಿಕ ಆಯ್ಕೆ - ಮಾದರಿಗಾಗಿ ಪ್ರತ್ಯೇಕ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ; 2) ಗುಂಪಿನ ಆಯ್ಕೆ - ಮಾದರಿಯು ಗುಣಾತ್ಮಕವಾಗಿ ಏಕರೂಪದ ಗುಂಪುಗಳು ಅಥವಾ ಅಧ್ಯಯನ ಮಾಡಲಾದ ಘಟಕಗಳ ಸರಣಿಯನ್ನು ಒಳಗೊಂಡಿದೆ; 3) ಸಂಯೋಜಿತ ಆಯ್ಕೆಯು ವೈಯಕ್ತಿಕ ಮತ್ತು ಗುಂಪಿನ ಆಯ್ಕೆಯ ಸಂಯೋಜನೆಯಾಗಿದೆ. ಮಾದರಿ ಜನಸಂಖ್ಯೆಯನ್ನು ರೂಪಿಸುವ ನಿಯಮಗಳಿಂದ ಆಯ್ಕೆ ವಿಧಾನಗಳನ್ನು ನಿರ್ಧರಿಸಲಾಗುತ್ತದೆ.
ಮಾದರಿಯು ಹೀಗಿರಬೇಕು:
- ವಾಸ್ತವವಾಗಿ ಯಾದೃಚ್ಛಿಕಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಪ್ರತ್ಯೇಕ ಘಟಕಗಳ ಯಾದೃಚ್ಛಿಕ (ಉದ್ದೇಶಪೂರ್ವಕವಲ್ಲದ) ಆಯ್ಕೆಯ ಪರಿಣಾಮವಾಗಿ ಮಾದರಿ ಜನಸಂಖ್ಯೆಯು ರೂಪುಗೊಳ್ಳುತ್ತದೆ ಎಂಬ ಅಂಶವನ್ನು ಒಳಗೊಂಡಿದೆ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಆಯ್ಕೆಮಾಡಿದ ಘಟಕಗಳ ಸಂಖ್ಯೆಯನ್ನು ಸಾಮಾನ್ಯವಾಗಿ ಸ್ವೀಕರಿಸಿದ ಮಾದರಿ ಅನುಪಾತದ ಆಧಾರದ ಮೇಲೆ ನಿರ್ಧರಿಸಲಾಗುತ್ತದೆ. ಮಾದರಿಯ ಅನುಪಾತವು ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಘಟಕಗಳ ಸಂಖ್ಯೆಯ ಅನುಪಾತವಾಗಿದೆ n ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಘಟಕಗಳ ಸಂಖ್ಯೆಗೆ N, ᴛ.ᴇ.
- ಯಾಂತ್ರಿಕಮಾದರಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಘಟಕಗಳ ಆಯ್ಕೆಯು ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಮಾಡಲ್ಪಟ್ಟಿದೆ, ಸಮಾನ ಮಧ್ಯಂತರಗಳಾಗಿ (ಗುಂಪುಗಳು) ವಿಂಗಡಿಸಲಾಗಿದೆ ಎಂಬ ಅಂಶವನ್ನು ಒಳಗೊಂಡಿದೆ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಮಧ್ಯಂತರದ ಗಾತ್ರವು ಮಾದರಿ ಹಂಚಿಕೆಯ ಪರಸ್ಪರ ಸಮಾನವಾಗಿರುತ್ತದೆ. ಆದ್ದರಿಂದ, 2% ಮಾದರಿಯೊಂದಿಗೆ, ಪ್ರತಿ 50 ನೇ ಘಟಕವನ್ನು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ (1:0.02), 5% ಮಾದರಿಯೊಂದಿಗೆ, ಪ್ರತಿ 20 ನೇ ಘಟಕ (1:0.05), ಇತ್ಯಾದಿ. ಆದಾಗ್ಯೂ, ಆಯ್ಕೆಯ ಸ್ವೀಕೃತ ಅನುಪಾತಕ್ಕೆ ಅನುಗುಣವಾಗಿ, ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಯಾಂತ್ರಿಕವಾಗಿ ಸಮಾನ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ. ಪ್ರತಿ ಗುಂಪಿನಿಂದ, ಮಾದರಿಗಾಗಿ ಒಂದು ಘಟಕವನ್ನು ಮಾತ್ರ ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ.
- ವಿಶಿಷ್ಟ -ಇದರಲ್ಲಿ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಮೊದಲು ಏಕರೂಪದ ವಿಶಿಷ್ಟ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ. ಮುಂದೆ, ಪ್ರತಿ ವಿಶಿಷ್ಟ ಗುಂಪಿನಿಂದ, ಮಾದರಿ ಜನಸಂಖ್ಯೆಗೆ ಪ್ರತ್ಯೇಕವಾಗಿ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲು ಸಂಪೂರ್ಣವಾಗಿ ಯಾದೃಚ್ಛಿಕ ಅಥವಾ ಯಾಂತ್ರಿಕ ಮಾದರಿಯನ್ನು ಬಳಸಲಾಗುತ್ತದೆ. ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡುವ ಇತರ ವಿಧಾನಗಳಿಗೆ ಹೋಲಿಸಿದರೆ ಇದು ಹೆಚ್ಚು ನಿಖರವಾದ ಫಲಿತಾಂಶಗಳನ್ನು ನೀಡುತ್ತದೆ ಎಂಬುದು ವಿಶಿಷ್ಟ ಮಾದರಿಯ ಪ್ರಮುಖ ಲಕ್ಷಣವಾಗಿದೆ;
- ಧಾರಾವಾಹಿ- ಇದರಲ್ಲಿ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯನ್ನು ಸಮಾನ ಗಾತ್ರದ ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ - ಸರಣಿ. ಮಾದರಿ ಜನಸಂಖ್ಯೆಗೆ ಸರಣಿಯನ್ನು ಆಯ್ಕೆಮಾಡಲಾಗಿದೆ. ಸರಣಿಯೊಳಗೆ, ಸರಣಿಯಲ್ಲಿ ಒಳಗೊಂಡಿರುವ ಘಟಕಗಳ ನಿರಂತರ ವೀಕ್ಷಣೆಯನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ;
- ಸಂಯೋಜಿಸಲಾಗಿದೆ- ಮಾದರಿ ಎರಡು ಹಂತಗಳಾಗಿರಬೇಕು. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಜನಸಂಖ್ಯೆಯನ್ನು ಮೊದಲು ಗುಂಪುಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ. ಮುಂದೆ, ಗುಂಪುಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ, ಮತ್ತು ನಂತರದ ಒಳಗೆ, ಪ್ರತ್ಯೇಕ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ.
ಅಂಕಿಅಂಶಗಳಲ್ಲಿ, ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆಮಾಡಲು ಈ ಕೆಳಗಿನ ವಿಧಾನಗಳನ್ನು ಪ್ರತ್ಯೇಕಿಸಲಾಗಿದೆ:
- ಒಂದೇ ಹಂತಮಾದರಿ - ಪ್ರತಿ ಆಯ್ದ ಘಟಕವನ್ನು ತಕ್ಷಣವೇ ನಿರ್ದಿಷ್ಟ ಮಾನದಂಡದ ಪ್ರಕಾರ ಅಧ್ಯಯನಕ್ಕೆ ಒಳಪಡಿಸಲಾಗುತ್ತದೆ (ಸರಿಯಾದ ಯಾದೃಚ್ಛಿಕ ಮತ್ತು ಸರಣಿ ಮಾದರಿ);
- ಬಹು-ಹಂತಮಾದರಿ - ಪ್ರತ್ಯೇಕ ಗುಂಪುಗಳ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಆಯ್ಕೆಯನ್ನು ಮಾಡಲಾಗುತ್ತದೆ ಮತ್ತು ಗುಂಪುಗಳಿಂದ ಪ್ರತ್ಯೇಕ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ (ಮಾದರಿ ಜನಸಂಖ್ಯೆಗೆ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡುವ ಯಾಂತ್ರಿಕ ವಿಧಾನದೊಂದಿಗೆ ವಿಶಿಷ್ಟ ಮಾದರಿ).
ಜೊತೆಗೆ, ಇವೆ:
- ಮರು ಆಯ್ಕೆ- ಹಿಂತಿರುಗಿದ ಚೆಂಡಿನ ಯೋಜನೆಯ ಪ್ರಕಾರ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲಾದ ಪ್ರತಿ ಘಟಕ ಅಥವಾ ಸರಣಿಯನ್ನು ಸಾಮಾನ್ಯ ಜನರಿಗೆ ಹಿಂತಿರುಗಿಸಲಾಗುತ್ತದೆ ಮತ್ತು ಆದ್ದರಿಂದ ಮತ್ತೊಮ್ಮೆ ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲು ಅವಕಾಶವಿದೆ;
- ಪುನರಾವರ್ತಿತ ಆಯ್ಕೆ- ಹಿಂತಿರುಗಿಸದ ಚೆಂಡಿನ ಯೋಜನೆಯ ಪ್ರಕಾರ. ಇದು ಒಂದೇ ಮಾದರಿಯ ಗಾತ್ರದೊಂದಿಗೆ ಹೆಚ್ಚು ನಿಖರವಾದ ಫಲಿತಾಂಶಗಳನ್ನು ಹೊಂದಿದೆ.
23. ಅತ್ಯಂತ ಪ್ರಮುಖ ಮಾದರಿ ಗಾತ್ರದ ನಿರ್ಣಯ (ವಿದ್ಯಾರ್ಥಿಗಳ ಟಿ-ಟೇಬಲ್ ಬಳಸಿ).
ಮಾದರಿ ಸಿದ್ಧಾಂತದಲ್ಲಿನ ವೈಜ್ಞಾನಿಕ ತತ್ವಗಳಲ್ಲಿ ಒಂದು ಸಾಕಷ್ಟು ಸಂಖ್ಯೆಯ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆಮಾಡಲಾಗಿದೆ ಎಂದು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳುವುದು. ಸೈದ್ಧಾಂತಿಕವಾಗಿ, ಈ ತತ್ವವನ್ನು ಗಮನಿಸುವುದರ ತೀವ್ರ ಪ್ರಾಮುಖ್ಯತೆಯನ್ನು ಸಂಭವನೀಯತೆ ಸಿದ್ಧಾಂತದಲ್ಲಿ ಮಿತಿ ಪ್ರಮೇಯಗಳ ಪುರಾವೆಗಳಲ್ಲಿ ಪ್ರಸ್ತುತಪಡಿಸಲಾಗಿದೆ, ಇದು ಜನಸಂಖ್ಯೆಯಿಂದ ಯಾವ ಪ್ರಮಾಣದ ಘಟಕಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಬೇಕೆಂದು ಸ್ಥಾಪಿಸಲು ಸಾಧ್ಯವಾಗುವಂತೆ ಮಾಡುತ್ತದೆ ಇದರಿಂದ ಅದು ಸಾಕಾಗುತ್ತದೆ ಮತ್ತು ಮಾದರಿಯ ಪ್ರಾತಿನಿಧ್ಯವನ್ನು ಖಾತ್ರಿಗೊಳಿಸುತ್ತದೆ.
ಪ್ರಮಾಣಿತ ಮಾದರಿ ದೋಷದಲ್ಲಿನ ಇಳಿಕೆ, ಮತ್ತು ಆದ್ದರಿಂದ ಅಂದಾಜಿನ ನಿಖರತೆಯ ಹೆಚ್ಚಳವು ಯಾವಾಗಲೂ ಮಾದರಿಯ ಗಾತ್ರದ ಹೆಚ್ಚಳದೊಂದಿಗೆ ಸಂಬಂಧಿಸಿದೆ, ಆದ್ದರಿಂದ, ಈಗಾಗಲೇ ಮಾದರಿ ವೀಕ್ಷಣೆಯನ್ನು ಆಯೋಜಿಸುವ ಹಂತದಲ್ಲಿ, ಅದರ ಗಾತ್ರವನ್ನು ನಿರ್ಧರಿಸುವುದು ಅವಶ್ಯಕ ವೀಕ್ಷಣೆಯ ಫಲಿತಾಂಶಗಳ ಅಗತ್ಯವಿರುವ ನಿಖರತೆಯನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು ಮಾದರಿ ಜನಸಂಖ್ಯೆಯು ಇರಬೇಕು. ಒಂದು ನಿರ್ದಿಷ್ಟ ಪ್ರಕಾರ ಮತ್ತು ಆಯ್ಕೆಯ ವಿಧಾನಕ್ಕೆ ಅನುಗುಣವಾಗಿ ಗರಿಷ್ಠ ಮಾದರಿ ದೋಷಗಳಿಗೆ (A) ಸೂತ್ರಗಳಿಂದ ಪಡೆದ ಸೂತ್ರಗಳನ್ನು ಬಳಸಿಕೊಂಡು ಅತ್ಯಂತ ಪ್ರಮುಖ ಮಾದರಿ ಪರಿಮಾಣದ ಲೆಕ್ಕಾಚಾರವನ್ನು ನಿರ್ಮಿಸಲಾಗಿದೆ. ಆದ್ದರಿಂದ, ಯಾದೃಚ್ಛಿಕ ಪುನರಾವರ್ತಿತ ಮಾದರಿ ಗಾತ್ರ (n) ಗಾಗಿ ನಾವು ಹೊಂದಿದ್ದೇವೆ:

ಈ ಸೂತ್ರದ ಮೂಲತತ್ವವೆಂದರೆ ಅತ್ಯಂತ ಪ್ರಮುಖ ಸಂಖ್ಯೆಗಳ ಯಾದೃಚ್ಛಿಕ ಪುನರಾವರ್ತಿತ ಮಾದರಿಯೊಂದಿಗೆ, ಮಾದರಿ ಗಾತ್ರವು ವಿಶ್ವಾಸಾರ್ಹ ಗುಣಾಂಕದ ವರ್ಗಕ್ಕೆ ನೇರವಾಗಿ ಅನುಪಾತದಲ್ಲಿರುತ್ತದೆ. (ಟಿ2)ಮತ್ತು ವ್ಯತ್ಯಾಸದ ಗುಣಲಕ್ಷಣದ ವ್ಯತ್ಯಾಸ (?2) ಮತ್ತು ಗರಿಷ್ಠ ಮಾದರಿ ದೋಷದ ವರ್ಗಕ್ಕೆ ವಿಲೋಮ ಅನುಪಾತದಲ್ಲಿರುತ್ತದೆ (?2). ನಿರ್ದಿಷ್ಟವಾಗಿ ಹೇಳುವುದಾದರೆ, ಗರಿಷ್ಠ ದೋಷದಲ್ಲಿ ಎರಡು ಅಂಶಗಳ ಹೆಚ್ಚಳದೊಂದಿಗೆ, ಅಗತ್ಯವಿರುವ ಮಾದರಿ ಗಾತ್ರವನ್ನು ನಾಲ್ಕು ಅಂಶಗಳಿಂದ ಕಡಿಮೆಗೊಳಿಸಬೇಕು. ಮೂರು ನಿಯತಾಂಕಗಳಲ್ಲಿ, ಎರಡು (ಟಿ ಮತ್ತು?) ಅನ್ನು ಸಂಶೋಧಕರು ಹೊಂದಿಸಿದ್ದಾರೆ. ಅದೇ ಸಮಯದಲ್ಲಿ, ಗುರಿಯ ಆಧಾರದ ಮೇಲೆ ಸಂಶೋಧಕ
ಮತ್ತು ಮಾದರಿ ಸಮೀಕ್ಷೆಯ ಸಮಸ್ಯೆಗಳು ಪ್ರಶ್ನೆಯನ್ನು ಪರಿಹರಿಸಬೇಕು: ಸೂಕ್ತವಾದ ಆಯ್ಕೆಯನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು ಈ ನಿಯತಾಂಕಗಳನ್ನು ಯಾವ ಪರಿಮಾಣಾತ್ಮಕ ಸಂಯೋಜನೆಯಲ್ಲಿ ಸೇರಿಸುವುದು ಉತ್ತಮ? ಒಂದು ಸಂದರ್ಭದಲ್ಲಿ, ನಿಖರತೆಯ ಅಳತೆಗಿಂತ (?) ಪಡೆದ ಫಲಿತಾಂಶಗಳ ವಿಶ್ವಾಸಾರ್ಹತೆಯಿಂದ ಅವನು ಹೆಚ್ಚು ತೃಪ್ತಿ ಹೊಂದಬಹುದು (?), ಇನ್ನೊಂದರಲ್ಲಿ - ಪ್ರತಿಯಾಗಿ. ಮಾದರಿ ವೀಕ್ಷಣೆಯನ್ನು ವಿನ್ಯಾಸಗೊಳಿಸುವ ಹಂತದಲ್ಲಿ ಸಂಶೋಧಕರು ಈ ಸೂಚಕವನ್ನು ಹೊಂದಿಲ್ಲವಾದ್ದರಿಂದ, ಗರಿಷ್ಠ ಮಾದರಿ ದೋಷದ ಮೌಲ್ಯದ ಬಗ್ಗೆ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸುವುದು ಹೆಚ್ಚು ಕಷ್ಟಕರವಾಗಿದೆ, ಆದ್ದರಿಂದ ಪ್ರಾಯೋಗಿಕವಾಗಿ ಗರಿಷ್ಠ ಮಾದರಿ ದೋಷದ ಮೌಲ್ಯವನ್ನು ಹೊಂದಿಸುವುದು ವಾಡಿಕೆ , ಸಾಮಾನ್ಯವಾಗಿ ಗುಣಲಕ್ಷಣದ ನಿರೀಕ್ಷಿತ ಸರಾಸರಿ ಮಟ್ಟದ 10% ಒಳಗೆ. ಅಂದಾಜು ಸರಾಸರಿಯನ್ನು ಸ್ಥಾಪಿಸುವುದನ್ನು ವಿವಿಧ ರೀತಿಯಲ್ಲಿ ಸಂಪರ್ಕಿಸಬಹುದು: ಇದೇ ರೀತಿಯ ಹಿಂದಿನ ಸಮೀಕ್ಷೆಗಳಿಂದ ಡೇಟಾವನ್ನು ಬಳಸುವುದು, ಅಥವಾ ಮಾದರಿ ಚೌಕಟ್ಟಿನಿಂದ ಡೇಟಾವನ್ನು ಬಳಸುವುದು ಮತ್ತು ಸಣ್ಣ ಪೈಲಟ್ ಮಾದರಿಯನ್ನು ನಡೆಸುವುದು.
ಮಾದರಿ ವೀಕ್ಷಣೆಯನ್ನು ವಿನ್ಯಾಸಗೊಳಿಸುವಾಗ ಸ್ಥಾಪಿಸಲು ಅತ್ಯಂತ ಕಷ್ಟಕರವಾದ ವಿಷಯವೆಂದರೆ ಸೂತ್ರದಲ್ಲಿ (5.2) ಮೂರನೇ ಪ್ಯಾರಾಮೀಟರ್ - ಮಾದರಿ ಜನಸಂಖ್ಯೆಯ ವ್ಯತ್ಯಾಸ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಹಿಂದಿನ ರೀತಿಯ ಮತ್ತು ಪೈಲಟ್ ಸಮೀಕ್ಷೆಗಳಲ್ಲಿ ಪಡೆದ ಸಂಶೋಧಕರಿಗೆ ಲಭ್ಯವಿರುವ ಎಲ್ಲಾ ಮಾಹಿತಿಯನ್ನು ಬಳಸುವುದು ಬಹಳ ಮುಖ್ಯ.
ಮಾದರಿ ಸಮೀಕ್ಷೆಯು ಮಾದರಿ ಘಟಕಗಳ ಹಲವಾರು ಗುಣಲಕ್ಷಣಗಳ ಅಧ್ಯಯನವನ್ನು ಒಳಗೊಂಡಿದ್ದರೆ ಅತ್ಯಂತ ಪ್ರಮುಖವಾದ ಮಾದರಿ ಗಾತ್ರವನ್ನು ನಿರ್ಧರಿಸುವ ಪ್ರಶ್ನೆಯು ಹೆಚ್ಚು ಸಂಕೀರ್ಣವಾಗುತ್ತದೆ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಪ್ರತಿಯೊಂದು ಗುಣಲಕ್ಷಣಗಳ ಸರಾಸರಿ ಮಟ್ಟಗಳು ಮತ್ತು ಅವುಗಳ ವ್ಯತ್ಯಾಸವು ನಿಯಮದಂತೆ ವಿಭಿನ್ನವಾಗಿರುತ್ತದೆ ಮತ್ತು ಈ ನಿಟ್ಟಿನಲ್ಲಿ, ಯಾವ ಗುಣಲಕ್ಷಣಗಳ ಯಾವ ವ್ಯತ್ಯಾಸವನ್ನು ಆದ್ಯತೆ ನೀಡಬೇಕೆಂದು ನಿರ್ಧರಿಸುವುದು ಉದ್ದೇಶ ಮತ್ತು ಉದ್ದೇಶಗಳನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಂಡು ಮಾತ್ರ ಸಾಧ್ಯ. ಸಮೀಕ್ಷೆಯ.
ಮಾದರಿ ವೀಕ್ಷಣೆಯನ್ನು ವಿನ್ಯಾಸಗೊಳಿಸುವಾಗ, ನಿರ್ದಿಷ್ಟ ಅಧ್ಯಯನದ ಉದ್ದೇಶಗಳು ಮತ್ತು ವೀಕ್ಷಣೆಯ ಫಲಿತಾಂಶಗಳ ಆಧಾರದ ಮೇಲೆ ತೀರ್ಮಾನಗಳ ಸಂಭವನೀಯತೆಗೆ ಅನುಗುಣವಾಗಿ ಅನುಮತಿಸುವ ಮಾದರಿ ದೋಷದ ಪೂರ್ವನಿರ್ಧರಿತ ಮೌಲ್ಯವನ್ನು ಊಹಿಸಲಾಗಿದೆ.
ಸಾಮಾನ್ಯವಾಗಿ, ಮಾದರಿ ಸರಾಸರಿಯ ಗರಿಷ್ಠ ದೋಷದ ಸೂತ್ರವು ನಮಗೆ ನಿರ್ಧರಿಸಲು ಅನುಮತಿಸುತ್ತದೆ:
‣‣‣ ಮಾದರಿ ಜನಸಂಖ್ಯೆಯ ಸೂಚಕಗಳಿಂದ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಸೂಚಕಗಳ ಸಂಭವನೀಯ ವಿಚಲನಗಳ ಪ್ರಮಾಣ;
‣‣‣ ಅಗತ್ಯವಿರುವ ನಿಖರತೆಯನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು ಅಗತ್ಯವಿರುವ ಮಾದರಿ ಗಾತ್ರ, ಸಂಭವನೀಯ ದೋಷದ ಮಿತಿಗಳು ನಿರ್ದಿಷ್ಟ ನಿರ್ದಿಷ್ಟ ಮೌಲ್ಯವನ್ನು ಮೀರುವುದಿಲ್ಲ;
‣‣‣ ಮಾದರಿಯಲ್ಲಿನ ದೋಷವು ನಿರ್ದಿಷ್ಟಪಡಿಸಿದ ಮಿತಿಯನ್ನು ಹೊಂದಿರುವ ಸಂಭವನೀಯತೆ.
ವಿದ್ಯಾರ್ಥಿ ವಿತರಣೆಸಂಭವನೀಯತೆ ಸಿದ್ಧಾಂತದಲ್ಲಿ, ಇದು ಸಂಪೂರ್ಣ ನಿರಂತರ ವಿತರಣೆಗಳ ಒಂದು-ಪ್ಯಾರಾಮೀಟರ್ ಕುಟುಂಬವಾಗಿದೆ.
24. ಡೈನಾಮಿಕ್ ಸರಣಿ (ಮಧ್ಯಂತರ, ಕ್ಷಣ), ಡೈನಾಮಿಕ್ ಸರಣಿಯನ್ನು ಮುಚ್ಚುವುದು.
ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿ- ಇವುಗಳು ನಿರ್ದಿಷ್ಟ ಕಾಲಾನುಕ್ರಮದಲ್ಲಿ ಪ್ರಸ್ತುತಪಡಿಸಲಾದ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಸೂಚಕಗಳ ಮೌಲ್ಯಗಳಾಗಿವೆ.
ಪ್ರತಿ ಬಾರಿಯ ಸರಣಿಯು ಎರಡು ಅಂಶಗಳನ್ನು ಒಳಗೊಂಡಿದೆ:
1) ಅವಧಿಗಳ ಸೂಚಕಗಳು(ವರ್ಷಗಳು, ತ್ರೈಮಾಸಿಕಗಳು, ತಿಂಗಳುಗಳು, ದಿನಗಳು ಅಥವಾ ದಿನಾಂಕಗಳು);
2) ಅಧ್ಯಯನದ ಅಡಿಯಲ್ಲಿ ವಸ್ತುವನ್ನು ನಿರೂಪಿಸುವ ಸೂಚಕಗಳುಕಾಲಾವಧಿಗಳಿಗೆ ಅಥವಾ ಅನುಗುಣವಾದ ದಿನಾಂಕಗಳಲ್ಲಿ, ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ ಸರಣಿ ಮಟ್ಟಗಳು.
ಸರಣಿಯ ಮಟ್ಟವನ್ನು ಸಂಪೂರ್ಣ ಮತ್ತು ಸರಾಸರಿ ಅಥವಾ ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಲಾಗುತ್ತದೆ. ಸೂಚಕಗಳ ಸ್ವರೂಪದ ಅವಲಂಬನೆಯನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಂಡು, ಸಂಪೂರ್ಣ, ಸಾಪೇಕ್ಷ ಮತ್ತು ಸರಾಸರಿ ಮೌಲ್ಯಗಳ ಕ್ರಿಯಾತ್ಮಕ ಸರಣಿಯನ್ನು ನಿರ್ಮಿಸಲಾಗಿದೆ. ಸಾಪೇಕ್ಷ ಮತ್ತು ಸರಾಸರಿ ಮೌಲ್ಯಗಳ ಡೈನಾಮಿಕ್ ಸರಣಿಯನ್ನು ಸಂಪೂರ್ಣ ಮೌಲ್ಯಗಳ ಪಡೆದ ಸರಣಿಯ ಆಧಾರದ ಮೇಲೆ ನಿರ್ಮಿಸಲಾಗಿದೆ. ಡೈನಾಮಿಕ್ಸ್ನ ಮಧ್ಯಂತರ ಮತ್ತು ಕ್ಷಣ ಸರಣಿಗಳಿವೆ.
ಡೈನಾಮಿಕ್ ಮಧ್ಯಂತರ ಸರಣಿನಿರ್ದಿಷ್ಟ ಅವಧಿಗೆ ಸೂಚಕಗಳ ಮೌಲ್ಯಗಳನ್ನು ಒಳಗೊಂಡಿದೆ. ಮಧ್ಯಂತರ ಸರಣಿಯಲ್ಲಿ, ದೀರ್ಘಾವಧಿಯಲ್ಲಿ ವಿದ್ಯಮಾನದ ಪರಿಮಾಣವನ್ನು ಪಡೆಯಲು ಮಟ್ಟವನ್ನು ಒಟ್ಟುಗೂಡಿಸಬಹುದು, ಅಥವಾ ಸಂಚಿತ ಮೊತ್ತಗಳು ಎಂದು ಕರೆಯಲ್ಪಡುತ್ತವೆ.
ಡೈನಾಮಿಕ್ ಕ್ಷಣ ಸರಣಿಒಂದು ನಿರ್ದಿಷ್ಟ ಹಂತದಲ್ಲಿ ಸೂಚಕಗಳ ಮೌಲ್ಯಗಳನ್ನು ಪ್ರತಿಬಿಂಬಿಸುತ್ತದೆ (ಸಮಯದ ದಿನಾಂಕ). ಕ್ಷಣ ಸರಣಿಯಲ್ಲಿ, ಸಂಶೋಧಕರು ಕೆಲವು ದಿನಾಂಕಗಳ ನಡುವಿನ ಸರಣಿಯ ಮಟ್ಟದಲ್ಲಿನ ಬದಲಾವಣೆಯನ್ನು ಪ್ರತಿಬಿಂಬಿಸುವ ವಿದ್ಯಮಾನಗಳಲ್ಲಿನ ವ್ಯತ್ಯಾಸದಲ್ಲಿ ಮಾತ್ರ ಆಸಕ್ತಿ ಹೊಂದಿರಬಹುದು, ಏಕೆಂದರೆ ಇಲ್ಲಿ ಮಟ್ಟಗಳ ಮೊತ್ತವು ಯಾವುದೇ ನೈಜ ವಿಷಯವನ್ನು ಹೊಂದಿಲ್ಲ. ಸಂಚಿತ ಮೊತ್ತವನ್ನು ಇಲ್ಲಿ ಲೆಕ್ಕಹಾಕಲಾಗಿಲ್ಲ.
ಸಮಯ ಸರಣಿಯ ಸರಿಯಾದ ನಿರ್ಮಾಣಕ್ಕೆ ಪ್ರಮುಖ ಷರತ್ತು ಸರಣಿ ಮಟ್ಟಗಳ ಹೋಲಿಕೆವಿವಿಧ ಅವಧಿಗಳಿಗೆ ಸೇರಿದವರು. ಮಟ್ಟವನ್ನು ಏಕರೂಪದ ಪ್ರಮಾಣದಲ್ಲಿ ಪ್ರಸ್ತುತಪಡಿಸಬೇಕು ಮತ್ತು ವಿದ್ಯಮಾನದ ವಿವಿಧ ಭಾಗಗಳ ವ್ಯಾಪ್ತಿಯ ಸಮಾನ ಸಂಪೂರ್ಣತೆ ಇರಬೇಕು.
ನೈಜ ಡೈನಾಮಿಕ್ಸ್ನ ವಿರೂಪವನ್ನು ತಪ್ಪಿಸಲು, ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಸಂಶೋಧನೆಯಲ್ಲಿ ಪ್ರಾಥಮಿಕ ಲೆಕ್ಕಾಚಾರಗಳನ್ನು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ (ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯನ್ನು ಮುಚ್ಚುವುದು), ಇದು ಸಮಯ ಸರಣಿಯ ಅಂಕಿಅಂಶಗಳ ವಿಶ್ಲೇಷಣೆಗೆ ಮುಂಚಿತವಾಗಿರುತ್ತದೆ. ಅಡಿಯಲ್ಲಿ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯನ್ನು ಮುಚ್ಚಲಾಗುತ್ತಿದೆಸಂಯೋಜನೆಯನ್ನು ಎರಡು ಅಥವಾ ಹೆಚ್ಚಿನ ಸರಣಿಗಳ ಒಂದು ಸರಣಿಯಾಗಿ ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಸಾಮಾನ್ಯವಾಗಿ ಒಪ್ಪಿಕೊಳ್ಳಲಾಗಿದೆ, ಅದರ ಮಟ್ಟವನ್ನು ವಿಭಿನ್ನ ವಿಧಾನವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ ಅಥವಾ ಪ್ರಾದೇಶಿಕ ಗಡಿಗಳಿಗೆ ಹೊಂದಿಕೆಯಾಗುವುದಿಲ್ಲ, ಇತ್ಯಾದಿ. ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯನ್ನು ಮುಚ್ಚುವುದು ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಸಂಪೂರ್ಣ ಮಟ್ಟವನ್ನು ಸಾಮಾನ್ಯ ಆಧಾರಕ್ಕೆ ತರುವುದನ್ನು ಸೂಚಿಸುತ್ತದೆ, ಇದು ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಮಟ್ಟಗಳ ಹೋಲಿಕೆಯನ್ನು ತಟಸ್ಥಗೊಳಿಸುತ್ತದೆ.
25. ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿ, ಗುಣಾಂಕಗಳು, ಬೆಳವಣಿಗೆ ಮತ್ತು ಬೆಳವಣಿಗೆ ದರಗಳ ಹೋಲಿಕೆಯ ಪರಿಕಲ್ಪನೆ.
ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿ- ಇವು ಕಾಲಾನಂತರದಲ್ಲಿ ನೈಸರ್ಗಿಕ ಮತ್ತು ಸಾಮಾಜಿಕ ವಿದ್ಯಮಾನಗಳ ಬೆಳವಣಿಗೆಯನ್ನು ನಿರೂಪಿಸುವ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಸೂಚಕಗಳ ಸರಣಿಯಾಗಿದೆ. ರಷ್ಯಾದ ರಾಜ್ಯ ಅಂಕಿಅಂಶಗಳ ಸಮಿತಿಯು ಪ್ರಕಟಿಸಿದ ಅಂಕಿಅಂಶಗಳ ಸಂಗ್ರಹಣೆಗಳು ಕೋಷ್ಟಕ ರೂಪದಲ್ಲಿ ಹೆಚ್ಚಿನ ಸಂಖ್ಯೆಯ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಗಳನ್ನು ಒಳಗೊಂಡಿವೆ. ಡೈನಾಮಿಕ್ ಸರಣಿಯು ಅಧ್ಯಯನ ಮಾಡಲಾದ ವಿದ್ಯಮಾನಗಳ ಅಭಿವೃದ್ಧಿಯ ಮಾದರಿಗಳನ್ನು ಗುರುತಿಸಲು ಸಾಧ್ಯವಾಗಿಸುತ್ತದೆ.
ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯು ಎರಡು ರೀತಿಯ ಸೂಚಕಗಳನ್ನು ಹೊಂದಿರುತ್ತದೆ. ಸಮಯ ಸೂಚಕಗಳು(ವರ್ಷಗಳು, ತ್ರೈಮಾಸಿಕಗಳು, ತಿಂಗಳುಗಳು, ಇತ್ಯಾದಿ) ಅಥವಾ ಸಮಯದ ಅಂಕಗಳು (ವರ್ಷದ ಆರಂಭದಲ್ಲಿ, ಪ್ರತಿ ತಿಂಗಳ ಆರಂಭದಲ್ಲಿ, ಇತ್ಯಾದಿ). ಸಾಲು ಮಟ್ಟದ ಸೂಚಕಗಳು. ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಮಟ್ಟಗಳ ಸೂಚಕಗಳನ್ನು ಸಂಪೂರ್ಣ ಮೌಲ್ಯಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಬಹುದು (ಟನ್ ಅಥವಾ ರೂಬಲ್ಸ್ನಲ್ಲಿ ಉತ್ಪನ್ನ ಉತ್ಪಾದನೆ), ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳು (% ನಲ್ಲಿ ನಗರ ಜನಸಂಖ್ಯೆಯ ಪಾಲು) ಮತ್ತು ಸರಾಸರಿ ಮೌಲ್ಯಗಳು (ವರ್ಷಕ್ಕೆ ಉದ್ಯಮದ ಕಾರ್ಮಿಕರ ಸರಾಸರಿ ಸಂಬಳ , ಇತ್ಯಾದಿ). ಕೋಷ್ಟಕ ರೂಪದಲ್ಲಿ, ಸಮಯ ಸರಣಿಯು ಎರಡು ಕಾಲಮ್ಗಳು ಅಥವಾ ಎರಡು ಸಾಲುಗಳನ್ನು ಹೊಂದಿರುತ್ತದೆ.
ಸಮಯ ಸರಣಿಯ ಸರಿಯಾದ ನಿರ್ಮಾಣಕ್ಕೆ ಹಲವಾರು ಅವಶ್ಯಕತೆಗಳನ್ನು ಪೂರೈಸುವ ಅಗತ್ಯವಿದೆ:
- ಡೈನಾಮಿಕ್ಸ್ನ ಎಲ್ಲಾ ಸೂಚಕಗಳು ವೈಜ್ಞಾನಿಕವಾಗಿ ಸಮರ್ಥನೀಯ ಮತ್ತು ವಿಶ್ವಾಸಾರ್ಹವಾಗಿರಬೇಕು;
- ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಸೂಚಕಗಳು ಕಾಲಾನಂತರದಲ್ಲಿ ಹೋಲಿಸಬಹುದಾಗಿದೆ, ᴛ.ᴇ. ಅದೇ ಅವಧಿಗಳಿಗೆ ಅಥವಾ ಅದೇ ದಿನಾಂಕಗಳಲ್ಲಿ ಲೆಕ್ಕ ಹಾಕಬೇಕು;
- ಹಲವಾರು ಡೈನಾಮಿಕ್ಸ್ನ ಸೂಚಕಗಳು ಪ್ರದೇಶದಾದ್ಯಂತ ಹೋಲಿಸಬಹುದಾಗಿದೆ;
- ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಸೂಚಕಗಳು ವಿಷಯದಲ್ಲಿ ಹೋಲಿಸಬಹುದಾದಂತಿರಬೇಕು, ᴛ.ᴇ. ಒಂದೇ ವಿಧಾನದ ಪ್ರಕಾರ ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ, ಅದೇ ರೀತಿಯಲ್ಲಿ;
- ಹಲವಾರು ಡೈನಾಮಿಕ್ಸ್ನ ಸೂಚಕಗಳನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳಲಾದ ಫಾರ್ಮ್ಗಳ ವ್ಯಾಪ್ತಿಯಲ್ಲಿ ಹೋಲಿಸಬಹುದು. ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಎಲ್ಲಾ ಸೂಚಕಗಳನ್ನು ಅದೇ ಅಳತೆಯ ಘಟಕಗಳಲ್ಲಿ ನೀಡಬೇಕು.
ಅಂಕಿಅಂಶಗಳ ಸೂಚಕಗಳು ಒಂದು ನಿರ್ದಿಷ್ಟ ಅವಧಿಯಲ್ಲಿ ಅಧ್ಯಯನ ಮಾಡುವ ಪ್ರಕ್ರಿಯೆಯ ಫಲಿತಾಂಶಗಳನ್ನು ಅಥವಾ ಒಂದು ನಿರ್ದಿಷ್ಟ ಹಂತದಲ್ಲಿ ಅಧ್ಯಯನ ಮಾಡಲಾದ ವಿದ್ಯಮಾನದ ಸ್ಥಿತಿಯನ್ನು ನಿರೂಪಿಸಬಹುದು, ᴛ.ᴇ. ಸೂಚಕಗಳು ಮಧ್ಯಂತರ (ಆವರ್ತಕ) ಮತ್ತು ಕ್ಷಣಿಕವಾಗಿರಬಹುದು. ಅಂತೆಯೇ, ಆರಂಭದಲ್ಲಿ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯು ಮಧ್ಯಂತರ ಅಥವಾ ಕ್ಷಣವಾಗಿರುತ್ತದೆ. ಮೊಮೆಂಟ್ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯು ಸಮಾನ ಮತ್ತು ಅಸಮಾನ ಸಮಯದ ಮಧ್ಯಂತರಗಳೊಂದಿಗೆ ಬರುತ್ತದೆ.
ಮೂಲ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯನ್ನು ಸರಾಸರಿ ಮೌಲ್ಯಗಳ ಸರಣಿಯಾಗಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ಸರಣಿಯಾಗಿ ಪರಿವರ್ತಿಸಬಹುದು (ಸರಪಳಿ ಮತ್ತು ಮೂಲ). ಅಂತಹ ಸಮಯ ಸರಣಿಯನ್ನು ಪಡೆದ ಸಮಯ ಸರಣಿ ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ.
ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಪ್ರಕಾರವನ್ನು ಅವಲಂಬಿಸಿ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯಲ್ಲಿ ಸರಾಸರಿ ಮಟ್ಟವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವ ವಿಧಾನವು ವಿಭಿನ್ನವಾಗಿದೆ. ಉದಾಹರಣೆಗಳನ್ನು ಬಳಸಿಕೊಂಡು, ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಪ್ರಕಾರಗಳು ಮತ್ತು ಸರಾಸರಿ ಮಟ್ಟವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು ನಾವು ಸೂತ್ರಗಳನ್ನು ಪರಿಗಣಿಸುತ್ತೇವೆ.
ಸಂಪೂರ್ಣ ಹೆಚ್ಚಾಗುತ್ತದೆ (Δy) ಹಿಂದಿನ ಮಟ್ಟಕ್ಕೆ ಹೋಲಿಸಿದರೆ (gr. 3. - ಸರಪಳಿ ಸಂಪೂರ್ಣ ಹೆಚ್ಚಳ) ಅಥವಾ ಆರಂಭಿಕ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ (gr. 4. - ಮೂಲಭೂತ ಸಂಪೂರ್ಣ ಹೆಚ್ಚಳ) ಎಷ್ಟು ಘಟಕಗಳನ್ನು ಸರಣಿಯ ನಂತರದ ಮಟ್ಟವು ಬದಲಾಗಿದೆ ಎಂಬುದನ್ನು ತೋರಿಸಿ. ಲೆಕ್ಕಾಚಾರದ ಸೂತ್ರಗಳನ್ನು ಈ ಕೆಳಗಿನಂತೆ ಬರೆಯಬಹುದು:

ಸರಣಿಯ ಸಂಪೂರ್ಣ ಮೌಲ್ಯಗಳು ಕಡಿಮೆಯಾದಾಗ, ಕ್ರಮವಾಗಿ "ಕಡಿಮೆ" ಅಥವಾ "ಕಡಿಮೆ" ಇರುತ್ತದೆ.
ಸಂಪೂರ್ಣ ಬೆಳವಣಿಗೆಯ ಸೂಚಕಗಳು ಸೂಚಿಸುತ್ತವೆ, ಉದಾಹರಣೆಗೆ, 1998 ರಲ್ಲಿ. ಉತ್ಪನ್ನ "A" ಉತ್ಪಾದನೆಯು 1997 ಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಹೆಚ್ಚಾಗಿದೆ. 4 ಸಾವಿರ ಟನ್ಗಳಿಂದ, ಮತ್ತು 1994 ಕ್ಕೆ ಹೋಲಿಸಿದರೆ ᴦ. - 34 ಸಾವಿರ ಟನ್ಗಳಷ್ಟು; ಇತರ ವರ್ಷಗಳಲ್ಲಿ, ಟೇಬಲ್ ನೋಡಿ. 11.5 ಗ್ರಾಂ
ref.rf ನಲ್ಲಿ ಪೋಸ್ಟ್ ಮಾಡಲಾಗಿದೆ
3 ಮತ್ತು 4.ಬೆಳವಣಿಗೆ ದರಹಿಂದಿನ ಮಟ್ಟಕ್ಕೆ ಹೋಲಿಸಿದರೆ (ಗ್ರಾ. 5 - ಬೆಳವಣಿಗೆ ಅಥವಾ ಕುಸಿತದ ಸರಪಳಿ ಗುಣಾಂಕಗಳು) ಅಥವಾ ಆರಂಭಿಕ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ (ಗ್ರಾ. 6 - ಬೆಳವಣಿಗೆ ಅಥವಾ ಕುಸಿತದ ಮೂಲ ಗುಣಾಂಕಗಳು) ಎಷ್ಟು ಬಾರಿ ಸರಣಿಯ ಮಟ್ಟವು ಬದಲಾಗಿದೆ ಎಂಬುದನ್ನು ತೋರಿಸುತ್ತದೆ. ಲೆಕ್ಕಾಚಾರದ ಸೂತ್ರಗಳನ್ನು ಈ ಕೆಳಗಿನಂತೆ ಬರೆಯಬಹುದು:

ಬೆಳವಣಿಗೆಯ ದರಗಳುಸರಣಿಯ ಮುಂದಿನ ಹಂತವು ಹಿಂದಿನ ಹಂತಕ್ಕೆ (ಕಾಲಮ್ 7 - ಸರಪಳಿ ಬೆಳವಣಿಗೆ ದರಗಳು) ಅಥವಾ ಆರಂಭಿಕ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ (ಗ್ರಾ. 8 - ಮೂಲ ಬೆಳವಣಿಗೆ ದರಗಳು) ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವನ್ನು ತೋರಿಸುತ್ತದೆ. ಲೆಕ್ಕಾಚಾರದ ಸೂತ್ರಗಳನ್ನು ಈ ಕೆಳಗಿನಂತೆ ಬರೆಯಬಹುದು:

ಆದ್ದರಿಂದ, ಉದಾಹರಣೆಗೆ, 1997 ರಲ್ಲಿ. 1996 ಕ್ಕೆ ಹೋಲಿಸಿದರೆ "A" ಉತ್ಪನ್ನದ ಉತ್ಪಾದನೆಯ ಪ್ರಮಾಣ. 105.5% (
ಬೆಳವಣಿಗೆ ದರಹಿಂದಿನ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ (ಕಾಲಮ್ 9 - ಸರಪಳಿ ಬೆಳವಣಿಗೆಯ ದರಗಳು) ಅಥವಾ ಆರಂಭಿಕ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ (ಕಾಲಮ್ 10 - ಮೂಲ ಬೆಳವಣಿಗೆ ದರಗಳು) ವರದಿ ಮಾಡುವ ಅವಧಿಯ ಮಟ್ಟವು ಎಷ್ಟು ಶೇಕಡಾ ಹೆಚ್ಚಾಗಿದೆ ಎಂಬುದನ್ನು ತೋರಿಸಿ. ಲೆಕ್ಕಾಚಾರದ ಸೂತ್ರಗಳನ್ನು ಈ ಕೆಳಗಿನಂತೆ ಬರೆಯಬಹುದು:
T pr = T r - 100% ಅಥವಾ T pr = ಹಿಂದಿನ ಅವಧಿಯ ಸಂಪೂರ್ಣ ಬೆಳವಣಿಗೆ / ಮಟ್ಟ * 100%
ಆದ್ದರಿಂದ, ಉದಾಹರಣೆಗೆ, 1996 ರಲ್ಲಿ. 1995 ಗೆ ಹೋಲಿಸಿದರೆ ᴦ. ಉತ್ಪನ್ನ "A" ಅನ್ನು 3.8% (103.8% - 100%) ಅಥವಾ (8:210) x 100% ರಷ್ಟು ಉತ್ಪಾದಿಸಲಾಯಿತು, ಮತ್ತು 1994 ಕ್ಕೆ ಹೋಲಿಸಿದರೆ ᴦ. - 9% (109% - 100%).
ಸರಣಿಯಲ್ಲಿನ ಸಂಪೂರ್ಣ ಮಟ್ಟಗಳು ಕಡಿಮೆಯಾದರೆ, ದರವು 100% ಕ್ಕಿಂತ ಕಡಿಮೆಯಿರುತ್ತದೆ ಮತ್ತು ಅದರ ಪ್ರಕಾರ, ಇಳಿಕೆಯ ದರ ಇರುತ್ತದೆ (ಮೈನಸ್ ಚಿಹ್ನೆಯೊಂದಿಗೆ ಹೆಚ್ಚಳದ ದರ).
1% ಹೆಚ್ಚಳದ ಸಂಪೂರ್ಣ ಮೌಲ್ಯ(ಗ್ರಾ.
ref.rf ನಲ್ಲಿ ಪೋಸ್ಟ್ ಮಾಡಲಾಗಿದೆ
11) ನಿರ್ದಿಷ್ಟ ಅವಧಿಯಲ್ಲಿ ಎಷ್ಟು ಘಟಕಗಳನ್ನು ಉತ್ಪಾದಿಸಬೇಕು ಎಂಬುದನ್ನು ತೋರಿಸುತ್ತದೆ ಇದರಿಂದ ಹಿಂದಿನ ಅವಧಿಯ ಮಟ್ಟವು 1% ರಷ್ಟು ಹೆಚ್ಚಾಗುತ್ತದೆ. ನಮ್ಮ ಉದಾಹರಣೆಯಲ್ಲಿ, 1995 ರಲ್ಲಿ ᴦ. 2.0 ಸಾವಿರ ಟನ್ ಉತ್ಪಾದಿಸುವ ಅಗತ್ಯವಿತ್ತು, ಮತ್ತು 1998 ರಲ್ಲಿ ᴦ. - 2.3 ಸಾವಿರ ಟನ್, ᴛ.ᴇ. ಹೆಚ್ಚು ದೊಡ್ಡದು.1% ಬೆಳವಣಿಗೆಯ ಸಂಪೂರ್ಣ ಮೌಲ್ಯವನ್ನು ಎರಡು ರೀತಿಯಲ್ಲಿ ನಿರ್ಧರಿಸಬಹುದು:
§ ಹಿಂದಿನ ಅವಧಿಯ ಮಟ್ಟವನ್ನು 100 ರಿಂದ ಭಾಗಿಸಿ;
§ ಸರಣಿಯ ಸಂಪೂರ್ಣ ಹೆಚ್ಚಳವನ್ನು ಅನುಗುಣವಾದ ಸರಪಳಿ ಬೆಳವಣಿಗೆಯ ದರಗಳಿಂದ ಭಾಗಿಸಲಾಗಿದೆ.
1% ಹೆಚ್ಚಳದ ಸಂಪೂರ್ಣ ಮೌಲ್ಯ =

ಡೈನಾಮಿಕ್ಸ್ನಲ್ಲಿ, ವಿಶೇಷವಾಗಿ ದೀರ್ಘಾವಧಿಯಲ್ಲಿ, ಪ್ರತಿ ಶೇಕಡಾವಾರು ಹೆಚ್ಚಳ ಅಥವಾ ಇಳಿಕೆಯ ವಿಷಯದೊಂದಿಗೆ ಬೆಳವಣಿಗೆಯ ದರದ ಜಂಟಿ ವಿಶ್ಲೇಷಣೆ ಮುಖ್ಯವಾಗಿದೆ.
ಸಮಯ ಸರಣಿಯನ್ನು ವಿಶ್ಲೇಷಿಸಲು ಪರಿಗಣಿಸಲಾದ ವಿಧಾನವು ಸಮಯ ಸರಣಿಗೆ ಅನ್ವಯಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಗಮನಿಸಿ, ಅದರ ಮಟ್ಟಗಳನ್ನು ಸಂಪೂರ್ಣ ಮೌಲ್ಯಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಲಾಗುತ್ತದೆ (ಟಿ, ಸಾವಿರ ರೂಬಲ್ಸ್ಗಳು, ಉದ್ಯೋಗಿಗಳ ಸಂಖ್ಯೆ, ಇತ್ಯಾದಿ), ಮತ್ತು ಸಮಯ ಸರಣಿಗೆ, ಯಾವ ಮಟ್ಟಗಳು ಸಾಪೇಕ್ಷ ಸೂಚಕಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಲಾಗುತ್ತದೆ (% ದೋಷಗಳು ,% ಕಲ್ಲಿದ್ದಲಿನ ಬೂದಿ ಅಂಶ, ಇತ್ಯಾದಿ.) ಅಥವಾ ಸರಾಸರಿ ಮೌಲ್ಯಗಳು (c/ha ನಲ್ಲಿ ಸರಾಸರಿ ಇಳುವರಿ, ಸರಾಸರಿ ಸಂಬಳ, ಇತ್ಯಾದಿ).
ಹಿಂದಿನ ಅಥವಾ ಆರಂಭಿಕ ಹಂತಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಪರಿಗಣಿಸಲಾದ ವಿಶ್ಲೇಷಣಾತ್ಮಕ ಸೂಚಕಗಳ ಜೊತೆಗೆ, ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯನ್ನು ವಿಶ್ಲೇಷಿಸುವಾಗ, ಅವಧಿಯ ಸರಾಸರಿ ವಿಶ್ಲೇಷಣಾತ್ಮಕ ಸೂಚಕಗಳನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವುದು ಬಹಳ ಮುಖ್ಯ: ಸರಣಿಯ ಸರಾಸರಿ ಮಟ್ಟ, ಸರಾಸರಿ ವಾರ್ಷಿಕ ಸಂಪೂರ್ಣ ಹೆಚ್ಚಳ (ಕಡಿಮೆ) ಮತ್ತು ಸರಾಸರಿ ವಾರ್ಷಿಕ ಬೆಳವಣಿಗೆ ದರ ಮತ್ತು ಬೆಳವಣಿಗೆ ದರ .
ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯ ಸರಾಸರಿ ಮಟ್ಟವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವ ವಿಧಾನಗಳನ್ನು ಮೇಲೆ ಚರ್ಚಿಸಲಾಗಿದೆ. ನಾವು ಪರಿಗಣಿಸುತ್ತಿರುವ ಮಧ್ಯಂತರ ಡೈನಾಮಿಕ್ಸ್ ಸರಣಿಯಲ್ಲಿ, ಸರಣಿಯ ಸರಾಸರಿ ಮಟ್ಟವನ್ನು ಸರಳ ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
1994-1998 ರ ಉತ್ಪನ್ನದ ಸರಾಸರಿ ವಾರ್ಷಿಕ ಉತ್ಪಾದನಾ ಪ್ರಮಾಣ. 218.4 ಸಾವಿರ ಟನ್ಗಳಷ್ಟಿತ್ತು.
ಸರಾಸರಿ ವಾರ್ಷಿಕ ಸಂಪೂರ್ಣ ಬೆಳವಣಿಗೆಯನ್ನು ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ
ಪ್ರಮಾಣಿತ ವಿಚಲನ - ಪರಿಕಲ್ಪನೆ ಮತ್ತು ಪ್ರಕಾರಗಳು. ವರ್ಗೀಕರಣ ಮತ್ತು ವೈಶಿಷ್ಟ್ಯಗಳು "ಸರಾಸರಿ ಚದರ ವಿಚಲನ" 2017, 2018.
ಪಾಠ ಸಂಖ್ಯೆ 4
ವಿಷಯ: “ವಿವರಣಾತ್ಮಕ ಅಂಕಿಅಂಶಗಳು. ಒಟ್ಟಾರೆಯಾಗಿ ಗುಣಲಕ್ಷಣ ವೈವಿಧ್ಯತೆಯ ಸೂಚಕಗಳು"
ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ವಿಶಿಷ್ಟತೆಯ ವೈವಿಧ್ಯತೆಯ ಮುಖ್ಯ ಮಾನದಂಡಗಳೆಂದರೆ: ಮಿತಿ, ವೈಶಾಲ್ಯ, ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಆಂದೋಲನದ ಗುಣಾಂಕ ಮತ್ತು ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ. ಹಿಂದಿನ ಪಾಠದಲ್ಲಿ, ಸರಾಸರಿ ಮೌಲ್ಯಗಳು ಒಟ್ಟಾರೆಯಾಗಿ ಅಧ್ಯಯನ ಮಾಡಲಾದ ಗುಣಲಕ್ಷಣದ ಸಾಮಾನ್ಯ ಗುಣಲಕ್ಷಣಗಳನ್ನು ಮಾತ್ರ ಒದಗಿಸುತ್ತವೆ ಮತ್ತು ಅದರ ಪ್ರತ್ಯೇಕ ರೂಪಾಂತರಗಳ ಮೌಲ್ಯಗಳನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುವುದಿಲ್ಲ ಎಂದು ಚರ್ಚಿಸಲಾಗಿದೆ: ಕನಿಷ್ಠ ಮತ್ತು ಗರಿಷ್ಠ ಮೌಲ್ಯಗಳು, ಸರಾಸರಿಗಿಂತ ಹೆಚ್ಚು, ಕೆಳಗೆ ಸರಾಸರಿ, ಇತ್ಯಾದಿ.
ಉದಾಹರಣೆ. ಎರಡು ವಿಭಿನ್ನ ಸಂಖ್ಯೆಯ ಅನುಕ್ರಮಗಳ ಸರಾಸರಿ ಮೌಲ್ಯಗಳು: -100; -20; 100; 20 ಮತ್ತು 0.1; -0.2; 0.1 ಸಂಪೂರ್ಣವಾಗಿ ಒಂದೇ ಮತ್ತು ಸಮಾನವಾಗಿರುತ್ತದೆಬಗ್ಗೆ.ಆದಾಗ್ಯೂ, ಈ ಸಂಬಂಧಿತ ಸರಾಸರಿ ಅನುಕ್ರಮ ಡೇಟಾದ ಸ್ಕ್ಯಾಟರ್ ಶ್ರೇಣಿಗಳು ತುಂಬಾ ವಿಭಿನ್ನವಾಗಿವೆ.
ವಿಶಿಷ್ಟತೆಯ ವೈವಿಧ್ಯತೆಗಾಗಿ ಪಟ್ಟಿ ಮಾಡಲಾದ ಮಾನದಂಡಗಳ ನಿರ್ಣಯವನ್ನು ಪ್ರಾಥಮಿಕವಾಗಿ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಜನಸಂಖ್ಯೆಯ ಪ್ರತ್ಯೇಕ ಅಂಶಗಳಲ್ಲಿ ಅದರ ಮೌಲ್ಯವನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಂಡು ನಡೆಸಲಾಗುತ್ತದೆ.
ಗುಣಲಕ್ಷಣದ ವ್ಯತ್ಯಾಸವನ್ನು ಅಳೆಯುವ ಸೂಚಕಗಳು ಸಂಪೂರ್ಣಮತ್ತು ಸಂಬಂಧಿ. ವ್ಯತ್ಯಾಸದ ಸಂಪೂರ್ಣ ಸೂಚಕಗಳು ಸೇರಿವೆ: ವ್ಯತ್ಯಾಸದ ವ್ಯಾಪ್ತಿ, ಮಿತಿ, ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಪ್ರಸರಣ. ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ ಮತ್ತು ಆಂದೋಲನದ ಗುಣಾಂಕವು ವ್ಯತ್ಯಾಸದ ಸಾಪೇಕ್ಷ ಅಳತೆಗಳನ್ನು ಉಲ್ಲೇಖಿಸುತ್ತದೆ.
ಮಿತಿ (ಲಿಮಿಟ್)-ಇದು ವಿಭಿನ್ನ ಸರಣಿಯಲ್ಲಿನ ರೂಪಾಂತರದ ತೀವ್ರ ಮೌಲ್ಯಗಳಿಂದ ನಿರ್ಧರಿಸಲ್ಪಡುವ ಮಾನದಂಡವಾಗಿದೆ. ಬೇರೆ ರೀತಿಯಲ್ಲಿ ಹೇಳುವುದಾದರೆ, ಈ ಮಾನದಂಡವು ಗುಣಲಕ್ಷಣದ ಕನಿಷ್ಠ ಮತ್ತು ಗರಿಷ್ಠ ಮೌಲ್ಯಗಳಿಂದ ಸೀಮಿತವಾಗಿದೆ:
ವೈಶಾಲ್ಯ (ಆಮ್)ಅಥವಾ ವ್ಯತ್ಯಾಸದ ವ್ಯಾಪ್ತಿ -ಇದು ತೀವ್ರ ಆಯ್ಕೆಗಳ ನಡುವಿನ ವ್ಯತ್ಯಾಸವಾಗಿದೆ. ಈ ಮಾನದಂಡದ ಲೆಕ್ಕಾಚಾರವನ್ನು ಗುಣಲಕ್ಷಣದ ಗರಿಷ್ಠ ಮೌಲ್ಯದಿಂದ ಅದರ ಕನಿಷ್ಠ ಮೌಲ್ಯವನ್ನು ಕಳೆಯುವುದರ ಮೂಲಕ ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ, ಇದು ಆಯ್ಕೆಯ ಸ್ಕ್ಯಾಟರ್ ಮಟ್ಟವನ್ನು ಅಂದಾಜು ಮಾಡಲು ನಮಗೆ ಅನುಮತಿಸುತ್ತದೆ:
ವ್ಯತ್ಯಾಸದ ಮಾನದಂಡವಾಗಿ ಮಿತಿ ಮತ್ತು ವೈಶಾಲ್ಯದ ಅನನುಕೂಲವೆಂದರೆ ಅವು ವಿಭಿನ್ನ ಸರಣಿಯಲ್ಲಿನ ವಿಶಿಷ್ಟತೆಯ ವಿಪರೀತ ಮೌಲ್ಯಗಳನ್ನು ಸಂಪೂರ್ಣವಾಗಿ ಅವಲಂಬಿಸಿವೆ. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಸರಣಿಯೊಳಗಿನ ಗುಣಲಕ್ಷಣ ಮೌಲ್ಯಗಳಲ್ಲಿನ ಏರಿಳಿತಗಳನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುವುದಿಲ್ಲ.
ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಗುಣಲಕ್ಷಣದ ವೈವಿಧ್ಯತೆಯ ಸಂಪೂರ್ಣ ವಿವರಣೆಯನ್ನು ಒದಗಿಸಲಾಗಿದೆ ಪ್ರಮಾಣಿತ ವಿಚಲನ(ಸಿಗ್ಮಾ), ಇದು ಅದರ ಸರಾಸರಿ ಮೌಲ್ಯದಿಂದ ಆಯ್ಕೆಯ ವಿಚಲನದ ಸಾಮಾನ್ಯ ಅಳತೆಯಾಗಿದೆ. ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಹೆಚ್ಚಾಗಿ ಕರೆಯಲಾಗುತ್ತದೆ ಪ್ರಮಾಣಿತ ವಿಚಲನ.
ಪ್ರಮಾಣಿತ ವಿಚಲನವು ನಿರ್ದಿಷ್ಟ ಜನಸಂಖ್ಯೆಯ ಅಂಕಗಣಿತದ ಸರಾಸರಿಯೊಂದಿಗೆ ಪ್ರತಿ ಆಯ್ಕೆಯ ಹೋಲಿಕೆಯನ್ನು ಆಧರಿಸಿದೆ. ಒಟ್ಟಾರೆಯಾಗಿ ಯಾವಾಗಲೂ ಅದಕ್ಕಿಂತ ಕಡಿಮೆ ಮತ್ತು ಹೆಚ್ಚಿನ ಆಯ್ಕೆಗಳಿರುವುದರಿಂದ, "" ಚಿಹ್ನೆಯೊಂದಿಗಿನ ವಿಚಲನಗಳ ಮೊತ್ತವನ್ನು "" ಚಿಹ್ನೆಯೊಂದಿಗೆ ವಿಚಲನಗಳ ಮೊತ್ತದಿಂದ ರದ್ದುಗೊಳಿಸಲಾಗುತ್ತದೆ, ಅಂದರೆ. ಎಲ್ಲಾ ವಿಚಲನಗಳ ಮೊತ್ತವು ಶೂನ್ಯವಾಗಿರುತ್ತದೆ. ವ್ಯತ್ಯಾಸಗಳ ಚಿಹ್ನೆಗಳ ಪ್ರಭಾವವನ್ನು ತಪ್ಪಿಸಲು, ಅಂಕಗಣಿತದ ಸರಾಸರಿ ವರ್ಗದಿಂದ ವಿಚಲನಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಲಾಗುತ್ತದೆ, ಅಂದರೆ. . ವರ್ಗ ವಿಚಲನಗಳ ಮೊತ್ತವು ಶೂನ್ಯಕ್ಕೆ ಸಮನಾಗಿರುವುದಿಲ್ಲ. ವ್ಯತ್ಯಾಸವನ್ನು ಅಳೆಯುವ ಗುಣಾಂಕವನ್ನು ಪಡೆಯಲು, ಚೌಕಗಳ ಮೊತ್ತದ ಸರಾಸರಿಯನ್ನು ತೆಗೆದುಕೊಳ್ಳಿ - ಈ ಮೌಲ್ಯವನ್ನು ಕರೆಯಲಾಗುತ್ತದೆ ವ್ಯತ್ಯಾಸಗಳು:

ಮೂಲಭೂತವಾಗಿ, ಪ್ರಸರಣವು ಅದರ ಸರಾಸರಿ ಮೌಲ್ಯದಿಂದ ವಿಶಿಷ್ಟತೆಯ ವೈಯಕ್ತಿಕ ಮೌಲ್ಯಗಳ ವಿಚಲನಗಳ ಸರಾಸರಿ ವರ್ಗವಾಗಿದೆ. ಪ್ರಸರಣ – ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಚೌಕ.
ವ್ಯತ್ಯಾಸವು ಆಯಾಮದ ಪ್ರಮಾಣವಾಗಿದೆ (ಹೆಸರಿಸಲಾಗಿದೆ). ಆದ್ದರಿಂದ, ಸಂಖ್ಯೆಯ ಸರಣಿಯ ರೂಪಾಂತರಗಳನ್ನು ಮೀಟರ್ಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಿದರೆ, ಆಗ ವ್ಯತ್ಯಾಸವು ಚದರ ಮೀಟರ್ಗಳನ್ನು ನೀಡುತ್ತದೆ; ಆಯ್ಕೆಗಳನ್ನು ಕಿಲೋಗ್ರಾಂಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಿದರೆ, ವ್ಯತ್ಯಾಸವು ಈ ಅಳತೆಯ ವರ್ಗವನ್ನು ನೀಡುತ್ತದೆ (ಕೆಜಿ 2), ಇತ್ಯಾದಿ.
ಪ್ರಮಾಣಿತ ವಿಚಲನ- ವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲ:
, ನಂತರ ಭಿನ್ನರಾಶಿಯ ಛೇದದಲ್ಲಿ ಪ್ರಸರಣ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ, ಬದಲಿಗೆಹಾಕಬೇಕು.
ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಲೆಕ್ಕಾಚಾರವನ್ನು ಆರು ಹಂತಗಳಾಗಿ ವಿಂಗಡಿಸಬಹುದು, ಅದನ್ನು ನಿರ್ದಿಷ್ಟ ಅನುಕ್ರಮದಲ್ಲಿ ಕೈಗೊಳ್ಳಬೇಕು:
ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಅಪ್ಲಿಕೇಶನ್:
ಎ) ವ್ಯತ್ಯಾಸ ಸರಣಿಯ ವ್ಯತ್ಯಾಸವನ್ನು ನಿರ್ಣಯಿಸಲು ಮತ್ತು ಅಂಕಗಣಿತದ ಸರಾಸರಿಗಳ ವಿಶಿಷ್ಟತೆಯ (ಪ್ರಾತಿನಿಧಿಕತೆ) ತುಲನಾತ್ಮಕ ಮೌಲ್ಯಮಾಪನಕ್ಕಾಗಿ. ರೋಗಲಕ್ಷಣಗಳ ಸ್ಥಿರತೆಯನ್ನು ನಿರ್ಧರಿಸುವಾಗ ಭೇದಾತ್ಮಕ ರೋಗನಿರ್ಣಯದಲ್ಲಿ ಇದು ಅವಶ್ಯಕವಾಗಿದೆ.
ಬಿ) ಬದಲಾವಣೆಯ ಸರಣಿಯನ್ನು ಪುನರ್ನಿರ್ಮಿಸಲು, ಅಂದರೆ. ಆಧರಿಸಿ ಅದರ ಆವರ್ತನ ಪ್ರತಿಕ್ರಿಯೆಯ ಮರುಸ್ಥಾಪನೆ ಮೂರು ಸಿಗ್ಮಾ ನಿಯಮಗಳು. ಮಧ್ಯಂತರದಲ್ಲಿ (M±3σ) ಸರಣಿಯ ಎಲ್ಲಾ ರೂಪಾಂತರಗಳಲ್ಲಿ 99.7% ಮಧ್ಯಂತರದಲ್ಲಿ ನೆಲೆಗೊಂಡಿದೆ (M±2σ) - 95.5% ಮತ್ತು ವ್ಯಾಪ್ತಿಯಲ್ಲಿ (M±1σ) - 68.3% ಸಾಲು ಆಯ್ಕೆ(ಚಿತ್ರ 1).
ಸಿ) "ಪಾಪ್-ಅಪ್" ಆಯ್ಕೆಗಳನ್ನು ಗುರುತಿಸಲು
ಡಿ) ಸಿಗ್ಮಾ ಅಂದಾಜುಗಳನ್ನು ಬಳಸಿಕೊಂಡು ರೂಢಿ ಮತ್ತು ರೋಗಶಾಸ್ತ್ರದ ನಿಯತಾಂಕಗಳನ್ನು ನಿರ್ಧರಿಸಲು
ಇ) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು
f) ಅಂಕಗಣಿತದ ಸರಾಸರಿ ದೋಷವನ್ನು ಲೆಕ್ಕಹಾಕಲು.
ಹೊಂದಿರುವ ಯಾವುದೇ ಜನಸಂಖ್ಯೆಯನ್ನು ನಿರೂಪಿಸಲುಸಾಮಾನ್ಯ ವಿತರಣೆಯ ಪ್ರಕಾರ , ಎರಡು ನಿಯತಾಂಕಗಳನ್ನು ತಿಳಿದುಕೊಳ್ಳುವುದು ಸಾಕು: ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನ.

ಚಿತ್ರ 1. ಮೂರು ಸಿಗ್ಮಾ ನಿಯಮ
ಉದಾಹರಣೆ.
ಪೀಡಿಯಾಟ್ರಿಕ್ಸ್ನಲ್ಲಿ, ನಿರ್ದಿಷ್ಟ ಮಗುವಿನ ಡೇಟಾವನ್ನು ಅನುಗುಣವಾದ ಪ್ರಮಾಣಿತ ಸೂಚಕಗಳೊಂದಿಗೆ ಹೋಲಿಸುವ ಮೂಲಕ ಮಕ್ಕಳ ದೈಹಿಕ ಬೆಳವಣಿಗೆಯನ್ನು ನಿರ್ಣಯಿಸಲು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಬಳಸಲಾಗುತ್ತದೆ. ಆರೋಗ್ಯವಂತ ಮಕ್ಕಳ ದೈಹಿಕ ಬೆಳವಣಿಗೆಯ ಅಂಕಗಣಿತದ ಸರಾಸರಿಯನ್ನು ಮಾನದಂಡವಾಗಿ ತೆಗೆದುಕೊಳ್ಳಲಾಗುತ್ತದೆ. ಮಾನದಂಡಗಳೊಂದಿಗೆ ಸೂಚಕಗಳ ಹೋಲಿಕೆ ವಿಶೇಷ ಕೋಷ್ಟಕಗಳನ್ನು ಬಳಸಿಕೊಂಡು ಕೈಗೊಳ್ಳಲಾಗುತ್ತದೆ, ಇದರಲ್ಲಿ ಮಾನದಂಡಗಳನ್ನು ಅವುಗಳ ಅನುಗುಣವಾದ ಸಿಗ್ಮಾ ಮಾಪಕಗಳೊಂದಿಗೆ ನೀಡಲಾಗುತ್ತದೆ. ಮಗುವಿನ ದೈಹಿಕ ಬೆಳವಣಿಗೆಯ ಸೂಚಕವು ಪ್ರಮಾಣಿತ (ಅಂಕಗಣಿತದ ಸರಾಸರಿ) ±σ ಒಳಗೆ ಇದ್ದರೆ, ನಂತರ ಮಗುವಿನ ದೈಹಿಕ ಬೆಳವಣಿಗೆ (ಈ ಸೂಚಕದ ಪ್ರಕಾರ) ರೂಢಿಗೆ ಅನುರೂಪವಾಗಿದೆ ಎಂದು ನಂಬಲಾಗಿದೆ. ಸೂಚಕವು ಪ್ರಮಾಣಿತ ±2σ ಒಳಗೆ ಇದ್ದರೆ, ನಂತರ ರೂಢಿಯಿಂದ ಸ್ವಲ್ಪ ವಿಚಲನವಿದೆ. ಸೂಚಕವು ಈ ಮಿತಿಗಳನ್ನು ಮೀರಿ ಹೋದರೆ, ನಂತರ ಮಗುವಿನ ದೈಹಿಕ ಬೆಳವಣಿಗೆಯು ರೂಢಿಯಿಂದ ತೀವ್ರವಾಗಿ ಭಿನ್ನವಾಗಿರುತ್ತದೆ (ರೋಗಶಾಸ್ತ್ರವು ಸಾಧ್ಯ).
ಸಂಪೂರ್ಣ ಮೌಲ್ಯಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಲಾದ ವ್ಯತ್ಯಾಸ ಸೂಚಕಗಳ ಜೊತೆಗೆ, ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಸಂಶೋಧನೆಯು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಿದ ವ್ಯತ್ಯಾಸ ಸೂಚಕಗಳನ್ನು ಬಳಸುತ್ತದೆ. ಆಂದೋಲನ ಗುಣಾಂಕ -ಇದು ಗುಣಲಕ್ಷಣದ ಸರಾಸರಿ ಮೌಲ್ಯಕ್ಕೆ ವ್ಯತ್ಯಾಸದ ಶ್ರೇಣಿಯ ಅನುಪಾತವಾಗಿದೆ. ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ -ಇದು ವಿಶಿಷ್ಟತೆಯ ಸರಾಸರಿ ಮೌಲ್ಯಕ್ಕೆ ಪ್ರಮಾಣಿತ ವಿಚಲನದ ಅನುಪಾತವಾಗಿದೆ. ವಿಶಿಷ್ಟವಾಗಿ, ಈ ಮೌಲ್ಯಗಳನ್ನು ಶೇಕಡಾವಾರುಗಳಾಗಿ ವ್ಯಕ್ತಪಡಿಸಲಾಗುತ್ತದೆ.
ಸಾಪೇಕ್ಷ ವ್ಯತ್ಯಾಸ ಸೂಚಕಗಳನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು ಸೂತ್ರಗಳು:
ಮೇಲಿನ ಸೂತ್ರಗಳಿಂದ ಹೆಚ್ಚಿನ ಗುಣಾಂಕವು ಸ್ಪಷ್ಟವಾಗುತ್ತದೆ ವಿ ಶೂನ್ಯಕ್ಕೆ ಹತ್ತಿರದಲ್ಲಿದೆ, ಗುಣಲಕ್ಷಣದ ಮೌಲ್ಯಗಳಲ್ಲಿನ ವ್ಯತ್ಯಾಸವು ಚಿಕ್ಕದಾಗಿದೆ. ಹೆಚ್ಚು ವಿ, ಹೆಚ್ಚು ವೇರಿಯಬಲ್ ಚಿಹ್ನೆ.
ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಅಭ್ಯಾಸದಲ್ಲಿ, ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವನ್ನು ಹೆಚ್ಚಾಗಿ ಬಳಸಲಾಗುತ್ತದೆ. ಇದು ವ್ಯತ್ಯಾಸದ ತುಲನಾತ್ಮಕ ಮೌಲ್ಯಮಾಪನಕ್ಕೆ ಮಾತ್ರವಲ್ಲದೆ ಜನಸಂಖ್ಯೆಯ ಏಕರೂಪತೆಯನ್ನು ನಿರೂಪಿಸಲು ಸಹ ಬಳಸಲಾಗುತ್ತದೆ. ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವು 33% ಅನ್ನು ಮೀರದಿದ್ದರೆ (ಸಾಮಾನ್ಯಕ್ಕೆ ಹತ್ತಿರವಿರುವ ವಿತರಣೆಗಳಿಗೆ) ಜನಸಂಖ್ಯೆಯನ್ನು ಏಕರೂಪವೆಂದು ಪರಿಗಣಿಸಲಾಗುತ್ತದೆ. ಅಂಕಗಣಿತದ ಪ್ರಕಾರ, σ ಮತ್ತು ಅಂಕಗಣಿತದ ಸರಾಸರಿಯ ಅನುಪಾತವು ಈ ಗುಣಲಕ್ಷಣಗಳ ಸಂಪೂರ್ಣ ಮೌಲ್ಯದ ಪ್ರಭಾವವನ್ನು ತಟಸ್ಥಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ಶೇಕಡಾವಾರು ಅನುಪಾತವು ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವನ್ನು ಆಯಾಮರಹಿತ (ಹೆಸರಿಲ್ಲದ) ಮೌಲ್ಯವನ್ನಾಗಿ ಮಾಡುತ್ತದೆ.
ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕದ ಫಲಿತಾಂಶದ ಮೌಲ್ಯವನ್ನು ಗುಣಲಕ್ಷಣದ ವೈವಿಧ್ಯತೆಯ ಹಂತದ ಅಂದಾಜು ಹಂತಗಳಿಗೆ ಅನುಗುಣವಾಗಿ ಅಂದಾಜಿಸಲಾಗಿದೆ:
ದುರ್ಬಲ - 10% ವರೆಗೆ
ಸರಾಸರಿ - 10 - 20%
ಪ್ರಬಲ - 20% ಕ್ಕಿಂತ ಹೆಚ್ಚು
ಗಾತ್ರ ಮತ್ತು ಆಯಾಮದಲ್ಲಿ ವಿಭಿನ್ನವಾಗಿರುವ ಗುಣಲಕ್ಷಣಗಳನ್ನು ಹೋಲಿಸಲು ಅಗತ್ಯವಿರುವ ಸಂದರ್ಭಗಳಲ್ಲಿ ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವನ್ನು ಬಳಸುವುದು ಸೂಕ್ತವಾಗಿದೆ.
ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ ಮತ್ತು ಇತರ ಸ್ಕ್ಯಾಟರ್ ಮಾನದಂಡಗಳ ನಡುವಿನ ವ್ಯತ್ಯಾಸವನ್ನು ಸ್ಪಷ್ಟವಾಗಿ ಪ್ರದರ್ಶಿಸಲಾಗುತ್ತದೆ ಉದಾಹರಣೆ.
ಕೋಷ್ಟಕ 1
ಕೈಗಾರಿಕಾ ಉದ್ಯಮದ ಕಾರ್ಮಿಕರ ಸಂಯೋಜನೆ
ಉದಾಹರಣೆಯಲ್ಲಿ ನೀಡಲಾದ ಅಂಕಿಅಂಶಗಳ ಗುಣಲಕ್ಷಣಗಳ ಆಧಾರದ ಮೇಲೆ, ಸಮೀಕ್ಷೆಯ ಅನಿಶ್ಚಿತತೆಯ ಕಡಿಮೆ ವೃತ್ತಿಪರ ಸ್ಥಿರತೆಯನ್ನು ನೀಡಿದ ಉದ್ಯಮದ ಉದ್ಯೋಗಿಗಳ ವಯಸ್ಸಿನ ಸಂಯೋಜನೆ ಮತ್ತು ಶೈಕ್ಷಣಿಕ ಮಟ್ಟದ ಸಾಪೇಕ್ಷ ಏಕರೂಪತೆಯ ಬಗ್ಗೆ ನಾವು ತೀರ್ಮಾನವನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು. ಈ ಸಾಮಾಜಿಕ ಪ್ರವೃತ್ತಿಗಳನ್ನು ಪ್ರಮಾಣಿತ ವಿಚಲನದಿಂದ ನಿರ್ಣಯಿಸುವ ಪ್ರಯತ್ನವು ತಪ್ಪಾದ ತೀರ್ಮಾನಕ್ಕೆ ಕಾರಣವಾಗುತ್ತದೆ ಎಂದು ನೋಡುವುದು ಸುಲಭ, ಮತ್ತು ಲೆಕ್ಕಪರಿಶೋಧಕ ಗುಣಲಕ್ಷಣಗಳು "ಕೆಲಸದ ಅನುಭವ" ಮತ್ತು "ವಯಸ್ಸು" ಅನ್ನು ಲೆಕ್ಕಪರಿಶೋಧಕ ಸೂಚಕ "ಶಿಕ್ಷಣ" ದೊಂದಿಗೆ ಹೋಲಿಸುವ ಪ್ರಯತ್ನವು ಸಾಮಾನ್ಯವಾಗಿ ಇರುತ್ತದೆ. ಈ ಗುಣಲಕ್ಷಣಗಳ ವೈವಿಧ್ಯತೆಯ ಕಾರಣದಿಂದಾಗಿ ತಪ್ಪಾಗಿದೆ.
ಮಧ್ಯಮ ಮತ್ತು ಶೇಕಡಾವಾರು
ಆರ್ಡಿನಲ್ (ಶ್ರೇಣಿಯ) ವಿತರಣೆಗಳಿಗೆ, ಸರಣಿಯ ಮಧ್ಯದ ಮಾನದಂಡವು ಮಧ್ಯಮವಾಗಿದ್ದರೆ, ಪ್ರಮಾಣಿತ ವಿಚಲನ ಮತ್ತು ಪ್ರಸರಣವು ರೂಪಾಂತರದ ಪ್ರಸರಣದ ಗುಣಲಕ್ಷಣಗಳಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುವುದಿಲ್ಲ.
ತೆರೆದ ಬದಲಾವಣೆಯ ಸರಣಿಗಳಿಗೆ ಇದು ನಿಜವಾಗಿದೆ. ಈ ಸನ್ನಿವೇಶವು ವ್ಯತ್ಯಾಸ ಮತ್ತು σ ಅನ್ನು ಲೆಕ್ಕಹಾಕುವ ವಿಚಲನಗಳನ್ನು ಅಂಕಗಣಿತದ ಸರಾಸರಿಯಿಂದ ಅಳೆಯಲಾಗುತ್ತದೆ, ಇದನ್ನು ಮುಕ್ತ ವ್ಯತ್ಯಾಸ ಸರಣಿಯಲ್ಲಿ ಮತ್ತು ಗುಣಾತ್ಮಕ ಗುಣಲಕ್ಷಣಗಳ ವಿತರಣೆಗಳ ಸರಣಿಯಲ್ಲಿ ಲೆಕ್ಕಹಾಕಲಾಗುವುದಿಲ್ಲ. ಆದ್ದರಿಂದ, ವಿತರಣೆಗಳ ಸಂಕುಚಿತ ವಿವರಣೆಗಾಗಿ, ಮತ್ತೊಂದು ಸ್ಕ್ಯಾಟರ್ ಪ್ಯಾರಾಮೀಟರ್ ಅನ್ನು ಬಳಸಲಾಗುತ್ತದೆ - ಪರಿಮಾಣಾತ್ಮಕ(ಸಮಾನಾರ್ಥಕ - "ಪರ್ಸೆಂಟೈಲ್"), ಅವುಗಳ ವಿತರಣೆಯ ಯಾವುದೇ ರೂಪದಲ್ಲಿ ಗುಣಾತ್ಮಕ ಮತ್ತು ಪರಿಮಾಣಾತ್ಮಕ ಗುಣಲಕ್ಷಣಗಳನ್ನು ವಿವರಿಸಲು ಸೂಕ್ತವಾಗಿದೆ. ಈ ನಿಯತಾಂಕವನ್ನು ಪರಿಮಾಣಾತ್ಮಕ ಗುಣಲಕ್ಷಣಗಳನ್ನು ಗುಣಾತ್ಮಕವಾಗಿ ಪರಿವರ್ತಿಸಲು ಸಹ ಬಳಸಬಹುದು. ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಅಂತಹ ರೇಟಿಂಗ್ಗಳನ್ನು ನಿರ್ದಿಷ್ಟ ಆಯ್ಕೆಯು ಯಾವ ಕ್ರಮಾಂಕಕ್ಕೆ ಅನುಗುಣವಾಗಿರುತ್ತದೆ ಎಂಬುದರ ಆಧಾರದ ಮೇಲೆ ನಿಗದಿಪಡಿಸಲಾಗಿದೆ.
ಬಯೋಮೆಡಿಕಲ್ ಸಂಶೋಧನೆಯ ಅಭ್ಯಾಸದಲ್ಲಿ, ಈ ಕೆಳಗಿನ ಪ್ರಮಾಣಗಳನ್ನು ಹೆಚ್ಚಾಗಿ ಬಳಸಲಾಗುತ್ತದೆ:
- ಮಧ್ಯಮ;
, - ಕ್ವಾರ್ಟೈಲ್ಸ್ (ಕ್ವಾರ್ಟರ್ಸ್), ಅಲ್ಲಿ - ಕಡಿಮೆ ಕ್ವಾರ್ಟೈಲ್, – ಅಗ್ರ ಕ್ವಾರ್ಟೈಲ್.
ಕ್ವಾಂಟೈಲ್ಗಳು ಬದಲಾವಣೆಯ ಸರಣಿಯಲ್ಲಿನ ಸಂಭವನೀಯ ಬದಲಾವಣೆಗಳ ಪ್ರದೇಶವನ್ನು ಕೆಲವು ಮಧ್ಯಂತರಗಳಾಗಿ ವಿಭಜಿಸುತ್ತದೆ. ಮೀಡಿಯನ್ (ಕ್ವಾಂಟೈಲ್) ಒಂದು ಆಯ್ಕೆಯಾಗಿದ್ದು ಅದು ವ್ಯತ್ಯಾಸ ಸರಣಿಯ ಮಧ್ಯದಲ್ಲಿದೆ ಮತ್ತು ಈ ಸರಣಿಯನ್ನು ಅರ್ಧದಷ್ಟು ಎರಡು ಸಮಾನ ಭಾಗಗಳಾಗಿ ವಿಂಗಡಿಸುತ್ತದೆ ( 0,5 ಮತ್ತು 0,5 ) ಒಂದು ಕ್ವಾರ್ಟೈಲ್ ಸರಣಿಯನ್ನು ನಾಲ್ಕು ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುತ್ತದೆ: ಮೊದಲ ಭಾಗ (ಕೆಳಗಿನ ಕ್ವಾರ್ಟೈಲ್) ಒಂದು ಆಯ್ಕೆಯಾಗಿದೆ, ಅದರ ಸಂಖ್ಯಾತ್ಮಕ ಮೌಲ್ಯಗಳು ಒಂದು ನಿರ್ದಿಷ್ಟ ಸರಣಿಯಲ್ಲಿ ಗರಿಷ್ಠ ಸಂಭವನೀಯತೆಯ 25% ಕ್ಕಿಂತ ಹೆಚ್ಚಿಲ್ಲದ ಆಯ್ಕೆಗಳನ್ನು ಪ್ರತ್ಯೇಕಿಸುತ್ತದೆ; ಸಾಧ್ಯವಿರುವ ಗರಿಷ್ಠ 50% ವರೆಗೆ. ಮೇಲಿನ ಕ್ವಾರ್ಟೈಲ್ () ಗರಿಷ್ಠ ಸಂಭವನೀಯ ಮೌಲ್ಯಗಳ 75% ವರೆಗಿನ ಆಯ್ಕೆಗಳನ್ನು ಪ್ರತ್ಯೇಕಿಸುತ್ತದೆ.
ಅಸಮಪಾರ್ಶ್ವದ ವಿತರಣೆಯ ಸಂದರ್ಭದಲ್ಲಿ ಅಂಕಗಣಿತದ ಸರಾಸರಿಗೆ ಸಂಬಂಧಿಸಿದಂತೆ ವೇರಿಯೇಬಲ್, ಸರಾಸರಿ ಮತ್ತು ಕ್ವಾರ್ಟೈಲ್ಸ್ ಅನ್ನು ನಿರೂಪಿಸಲು ಬಳಸಲಾಗುತ್ತದೆ.ಈ ಸಂದರ್ಭದಲ್ಲಿ, ಸರಾಸರಿ ಮೌಲ್ಯವನ್ನು ಪ್ರದರ್ಶಿಸುವ ಕೆಳಗಿನ ರೂಪವನ್ನು ಬಳಸಲಾಗುತ್ತದೆ - ಮೆಹ್ (;). ಉದಾಹರಣೆಗೆ, ಅಧ್ಯಯನ ಮಾಡಿದ ವೈಶಿಷ್ಟ್ಯ - "ಮಗು ಸ್ವತಂತ್ರವಾಗಿ ನಡೆಯಲು ಪ್ರಾರಂಭಿಸಿದ ಅವಧಿ" - ಅಧ್ಯಯನದ ಗುಂಪಿನಲ್ಲಿ ಅಸಮಪಾರ್ಶ್ವದ ವಿತರಣೆಯನ್ನು ಹೊಂದಿದೆ. ಅದೇ ಸಮಯದಲ್ಲಿ, ಕಡಿಮೆ ಕ್ವಾರ್ಟೈಲ್ () ವಾಕಿಂಗ್ ಪ್ರಾರಂಭಕ್ಕೆ ಅನುರೂಪವಾಗಿದೆ - 9.5 ತಿಂಗಳುಗಳು, ಸರಾಸರಿ - 11 ತಿಂಗಳುಗಳು, ಮೇಲಿನ ಕ್ವಾರ್ಟೈಲ್ () - 12 ತಿಂಗಳುಗಳು. ಅಂತೆಯೇ, ನಿರ್ದಿಷ್ಟಪಡಿಸಿದ ಗುಣಲಕ್ಷಣದ ಸರಾಸರಿ ಪ್ರವೃತ್ತಿಯ ಗುಣಲಕ್ಷಣವನ್ನು 11 (9.5; 12) ತಿಂಗಳುಗಳಾಗಿ ಪ್ರಸ್ತುತಪಡಿಸಲಾಗುತ್ತದೆ.
ಅಧ್ಯಯನದ ಫಲಿತಾಂಶಗಳ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮಹತ್ವವನ್ನು ನಿರ್ಣಯಿಸುವುದು
ದತ್ತಾಂಶದ ಅಂಕಿಅಂಶಗಳ ಪ್ರಾಮುಖ್ಯತೆಯು ಪ್ರದರ್ಶಿತ ರಿಯಾಲಿಟಿಗೆ ಅನುಗುಣವಾಗಿರುವ ಮಟ್ಟ ಎಂದು ತಿಳಿಯಲಾಗುತ್ತದೆ, ಅಂದರೆ. ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯವಾಗಿ ಮಹತ್ವದ ಡೇಟಾವು ವಸ್ತುನಿಷ್ಠ ವಾಸ್ತವತೆಯನ್ನು ವಿರೂಪಗೊಳಿಸದ ಮತ್ತು ಸರಿಯಾಗಿ ಪ್ರತಿಬಿಂಬಿಸುವುದಿಲ್ಲ.
ಸಂಶೋಧನಾ ಫಲಿತಾಂಶಗಳ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮಹತ್ವವನ್ನು ನಿರ್ಣಯಿಸುವುದು ಎಂದರೆ ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಿಂದ ಪಡೆದ ಫಲಿತಾಂಶಗಳನ್ನು ಇಡೀ ಜನಸಂಖ್ಯೆಗೆ ವರ್ಗಾಯಿಸಲು ಸಾಧ್ಯವಿರುವ ಸಂಭವನೀಯತೆಯೊಂದಿಗೆ ನಿರ್ಧರಿಸುವುದು. ಒಟ್ಟಾರೆಯಾಗಿ ವಿದ್ಯಮಾನವನ್ನು ಮತ್ತು ಅದರ ಮಾದರಿಗಳನ್ನು ನಿರ್ಣಯಿಸಲು ಎಷ್ಟು ವಿದ್ಯಮಾನವನ್ನು ಬಳಸಬಹುದು ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮಹತ್ವವನ್ನು ನಿರ್ಣಯಿಸುವುದು ಅವಶ್ಯಕ.
ಸಂಶೋಧನಾ ಫಲಿತಾಂಶಗಳ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಪ್ರಾಮುಖ್ಯತೆಯ ಮೌಲ್ಯಮಾಪನವು ಒಳಗೊಂಡಿದೆ:
1. ಪ್ರಾತಿನಿಧ್ಯದ ದೋಷಗಳು (ಸರಾಸರಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ದೋಷಗಳು) - ಮೀ;
2. ಸರಾಸರಿ ಅಥವಾ ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳು;
3. ಮಾನದಂಡದ ಪ್ರಕಾರ ಸರಾಸರಿ ಅಥವಾ ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳಲ್ಲಿನ ವ್ಯತ್ಯಾಸದ ವಿಶ್ವಾಸಾರ್ಹತೆ ಟಿ.
ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷಅಥವಾ ಪ್ರಾತಿನಿಧ್ಯ ದೋಷಸರಾಸರಿಯ ಏರಿಳಿತಗಳನ್ನು ನಿರೂಪಿಸುತ್ತದೆ. ಮಾದರಿಯ ಗಾತ್ರವು ದೊಡ್ಡದಾಗಿದೆ, ಸರಾಸರಿ ಮೌಲ್ಯಗಳ ಹರಡುವಿಕೆಯು ಚಿಕ್ಕದಾಗಿದೆ ಎಂದು ಗಮನಿಸಬೇಕು. ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷವನ್ನು ಸೂತ್ರವನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ:
ಆಧುನಿಕ ವೈಜ್ಞಾನಿಕ ಸಾಹಿತ್ಯದಲ್ಲಿ, ಅಂಕಗಣಿತದ ಸರಾಸರಿಯನ್ನು ಪ್ರತಿನಿಧಿತ್ವ ದೋಷದೊಂದಿಗೆ ಬರೆಯಲಾಗಿದೆ:
ಅಥವಾ ಪ್ರಮಾಣಿತ ವಿಚಲನದೊಂದಿಗೆ:
ಉದಾಹರಣೆಯಾಗಿ, ದೇಶದ 1,500 ಸಿಟಿ ಕ್ಲಿನಿಕ್ಗಳ ಡೇಟಾವನ್ನು ಪರಿಗಣಿಸಿ (ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆ). ಚಿಕಿತ್ಸಾಲಯದಲ್ಲಿ ಸೇವೆ ಸಲ್ಲಿಸಿದ ರೋಗಿಗಳ ಸರಾಸರಿ ಸಂಖ್ಯೆ 18,150 ಜನರು. 10% ಸೈಟ್ಗಳ (150 ಕ್ಲಿನಿಕ್ಗಳು) ಯಾದೃಚ್ಛಿಕ ಆಯ್ಕೆಯು 20,051 ಜನರಿಗೆ ಸಮಾನವಾದ ರೋಗಿಗಳ ಸರಾಸರಿ ಸಂಖ್ಯೆಯನ್ನು ನೀಡುತ್ತದೆ. ಮಾದರಿ ದೋಷ, ಎಲ್ಲಾ 1500 ಚಿಕಿತ್ಸಾಲಯಗಳನ್ನು ಮಾದರಿಯಲ್ಲಿ ಸೇರಿಸಲಾಗಿಲ್ಲ ಎಂಬ ಅಂಶದಿಂದಾಗಿ, ಈ ಸರಾಸರಿಗಳ ನಡುವಿನ ವ್ಯತ್ಯಾಸಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ - ಸಾಮಾನ್ಯ ಸರಾಸರಿ ( ಎಂಜೀನ್) ಮತ್ತು ಮಾದರಿ ಸರಾಸರಿ ( ಎಂಆಯ್ಕೆ ಮಾಡಲಾಗಿದೆ). ನಮ್ಮ ಜನಸಂಖ್ಯೆಯಿಂದ ಅದೇ ಗಾತ್ರದ ಮತ್ತೊಂದು ಮಾದರಿಯನ್ನು ನಾವು ರಚಿಸಿದರೆ, ಅದು ವಿಭಿನ್ನ ದೋಷ ಮೌಲ್ಯವನ್ನು ನೀಡುತ್ತದೆ. ಈ ಎಲ್ಲಾ ಮಾದರಿ ವಿಧಾನಗಳು, ಸಾಕಷ್ಟು ದೊಡ್ಡ ಮಾದರಿಗಳೊಂದಿಗೆ, ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ ಅದೇ ಸಂಖ್ಯೆಯ ವಸ್ತುಗಳ ಮಾದರಿಯ ಸಾಕಷ್ಟು ದೊಡ್ಡ ಸಂಖ್ಯೆಯ ಪುನರಾವರ್ತನೆಗಳೊಂದಿಗೆ ಸಾಮಾನ್ಯ ಸರಾಸರಿ ಸುತ್ತಲೂ ಸಾಮಾನ್ಯವಾಗಿ ವಿತರಿಸಲಾಗುತ್ತದೆ. ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷ ಮೀ- ಇದು ಸಾಮಾನ್ಯ ಸರಾಸರಿಯ ಸುತ್ತ ಮಾದರಿ ವಿಧಾನಗಳ ಅನಿವಾರ್ಯ ಹರಡುವಿಕೆಯಾಗಿದೆ.
ಸಂಶೋಧನೆಯ ಫಲಿತಾಂಶಗಳನ್ನು ಸಾಪೇಕ್ಷ ಪ್ರಮಾಣದಲ್ಲಿ ಪ್ರಸ್ತುತಪಡಿಸಿದಾಗ (ಉದಾಹರಣೆಗೆ, ಶೇಕಡಾವಾರು) - ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ ಭಿನ್ನರಾಶಿಯ ಪ್ರಮಾಣಿತ ದೋಷ:

ಇಲ್ಲಿ P ಎಂಬುದು % ನಲ್ಲಿ ಸೂಚಕವಾಗಿದೆ, n ಎಂಬುದು ವೀಕ್ಷಣೆಗಳ ಸಂಖ್ಯೆ.
ಫಲಿತಾಂಶವನ್ನು ಹೀಗೆ ಪ್ರದರ್ಶಿಸಲಾಗುತ್ತದೆ (P ± m)%. ಉದಾಹರಣೆಗೆ,ರೋಗಿಗಳಲ್ಲಿ ಚೇತರಿಕೆಯ ಶೇಕಡಾವಾರು (95.2±2.5)%.
ಈ ಸಂದರ್ಭದಲ್ಲಿ ಜನಸಂಖ್ಯೆಯ ಅಂಶಗಳ ಸಂಖ್ಯೆ, ನಂತರ ಸರಾಸರಿ ಮತ್ತು ಭಿನ್ನರಾಶಿಯ ಛೇದದಲ್ಲಿನ ಭಿನ್ನರಾಶಿಯ ಪ್ರಮಾಣಿತ ದೋಷಗಳನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವಾಗ, ಬದಲಿಗೆಹಾಕಬೇಕು.
ಸಾಮಾನ್ಯ ವಿತರಣೆಗಾಗಿ (ಮಾದರಿಯ ವಿತರಣೆಯು ಸಾಮಾನ್ಯವಾಗಿದೆ), ಜನಸಂಖ್ಯೆಯ ಯಾವ ಭಾಗವು ಸರಾಸರಿ ಸುತ್ತಲಿನ ಯಾವುದೇ ಮಧ್ಯಂತರದಲ್ಲಿ ಬರುತ್ತದೆ ಎಂದು ನಮಗೆ ತಿಳಿದಿದೆ. ನಿರ್ದಿಷ್ಟವಾಗಿ:
ಪ್ರಾಯೋಗಿಕವಾಗಿ, ಸಮಸ್ಯೆಯೆಂದರೆ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯ ಗುಣಲಕ್ಷಣಗಳು ನಮಗೆ ತಿಳಿದಿಲ್ಲ, ಮತ್ತು ಅವುಗಳನ್ನು ಅಂದಾಜು ಮಾಡುವ ಉದ್ದೇಶಕ್ಕಾಗಿ ಮಾದರಿಯನ್ನು ನಿಖರವಾಗಿ ತಯಾರಿಸಲಾಗುತ್ತದೆ. ಇದರರ್ಥ ನಾವು ಒಂದೇ ಗಾತ್ರದ ಮಾದರಿಗಳನ್ನು ಮಾಡಿದರೆ ಎನ್ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಿಂದ, ನಂತರ 68.3% ಪ್ರಕರಣಗಳಲ್ಲಿ ಮಧ್ಯಂತರವು ಮೌಲ್ಯವನ್ನು ಹೊಂದಿರುತ್ತದೆ ಎಂ(95.5% ಪ್ರಕರಣಗಳಲ್ಲಿ ಇದು ಮಧ್ಯಂತರದಲ್ಲಿರುತ್ತದೆ ಮತ್ತು 99.7% ಪ್ರಕರಣಗಳಲ್ಲಿ - ಮಧ್ಯಂತರದಲ್ಲಿರುತ್ತದೆ).
ಕೇವಲ ಒಂದು ಮಾದರಿಯನ್ನು ವಾಸ್ತವವಾಗಿ ತೆಗೆದುಕೊಳ್ಳಲಾಗಿರುವುದರಿಂದ, ಈ ಹೇಳಿಕೆಯನ್ನು ಸಂಭವನೀಯತೆಯ ದೃಷ್ಟಿಯಿಂದ ರೂಪಿಸಲಾಗಿದೆ: 68.3% ಸಂಭವನೀಯತೆಯೊಂದಿಗೆ, ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಗುಣಲಕ್ಷಣದ ಸರಾಸರಿ ಮೌಲ್ಯವು ಮಧ್ಯಂತರದಲ್ಲಿದೆ, 95.5% ಸಂಭವನೀಯತೆಯೊಂದಿಗೆ - ಮಧ್ಯಂತರದಲ್ಲಿ, ಇತ್ಯಾದಿ.
ಪ್ರಾಯೋಗಿಕವಾಗಿ, ಮಾದರಿ ಮೌಲ್ಯದ ಸುತ್ತ ಮಧ್ಯಂತರವನ್ನು ನಿರ್ಮಿಸಲಾಗಿದೆ, ಅಂದರೆ, ನಿರ್ದಿಷ್ಟ (ಸಾಕಷ್ಟು ಹೆಚ್ಚಿನ) ಸಂಭವನೀಯತೆಯೊಂದಿಗೆ, ವಿಶ್ವಾಸಾರ್ಹ ಸಂಭವನೀಯತೆ -ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಈ ನಿಯತಾಂಕದ ನಿಜವಾದ ಮೌಲ್ಯವನ್ನು "ಕವರ್" ಮಾಡುತ್ತದೆ. ಈ ಮಧ್ಯಂತರವನ್ನು ಕರೆಯಲಾಗುತ್ತದೆ ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರ.
ವಿಶ್ವಾಸ ಸಂಭವನೀಯತೆಪ – ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರವು ವಾಸ್ತವವಾಗಿ ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ನಿಯತಾಂಕದ ನಿಜವಾದ (ಅಜ್ಞಾತ) ಮೌಲ್ಯವನ್ನು ಹೊಂದಿರುತ್ತದೆ ಎಂಬ ವಿಶ್ವಾಸದ ಮಟ್ಟವಾಗಿದೆ.
ಉದಾಹರಣೆಗೆ, ವಿಶ್ವಾಸಾರ್ಹ ಸಂಭವನೀಯತೆ ಆರ್ 90% ಆಗಿದೆ, ಇದರರ್ಥ 100 ರಲ್ಲಿ 90 ಮಾದರಿಗಳು ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ನಿಯತಾಂಕದ ಸರಿಯಾದ ಅಂದಾಜನ್ನು ನೀಡುತ್ತದೆ. ಅಂತೆಯೇ, ದೋಷದ ಸಂಭವನೀಯತೆ, ಅಂದರೆ. ಮಾದರಿಯ ಸಾಮಾನ್ಯ ಸರಾಸರಿಯ ತಪ್ಪಾದ ಅಂದಾಜು ಶೇಕಡಾವಾರು ಸಮಾನವಾಗಿರುತ್ತದೆ: . ಈ ಉದಾಹರಣೆಗಾಗಿ, ಇದರರ್ಥ 100 ರಲ್ಲಿ 10 ಮಾದರಿಗಳು ತಪ್ಪಾದ ಅಂದಾಜನ್ನು ನೀಡುತ್ತವೆ.
ನಿಸ್ಸಂಶಯವಾಗಿ, ವಿಶ್ವಾಸಾರ್ಹತೆಯ ಮಟ್ಟವು (ವಿಶ್ವಾಸ ಸಂಭವನೀಯತೆ) ಮಧ್ಯಂತರದ ಗಾತ್ರವನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ: ವಿಶಾಲವಾದ ಮಧ್ಯಂತರ, ಜನಸಂಖ್ಯೆಗೆ ಅಜ್ಞಾತ ಮೌಲ್ಯವು ಅದರಲ್ಲಿ ಬೀಳುತ್ತದೆ ಎಂಬ ವಿಶ್ವಾಸವು ಹೆಚ್ಚಾಗುತ್ತದೆ. ಪ್ರಾಯೋಗಿಕವಾಗಿ, ಕನಿಷ್ಠ 95.5% ವಿಶ್ವಾಸವನ್ನು ಒದಗಿಸಲು ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರವನ್ನು ನಿರ್ಮಿಸಲು ಕನಿಷ್ಠ ಎರಡು ಬಾರಿ ಮಾದರಿ ದೋಷವನ್ನು ಬಳಸಲಾಗುತ್ತದೆ.
ಸರಾಸರಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳನ್ನು ನಿರ್ಧರಿಸುವುದು ಅವುಗಳ ಎರಡು ವಿಪರೀತ ಮೌಲ್ಯಗಳನ್ನು ಕಂಡುಹಿಡಿಯಲು ನಮಗೆ ಅನುಮತಿಸುತ್ತದೆ - ಕನಿಷ್ಠ ಸಂಭವನೀಯ ಮತ್ತು ಗರಿಷ್ಠ ಸಾಧ್ಯ, ಅದರೊಳಗೆ ಅಧ್ಯಯನ ಮಾಡಿದ ಸೂಚಕವು ಇಡೀ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಸಂಭವಿಸಬಹುದು. ಇದರ ಆಧಾರದ ಮೇಲೆ, ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳು (ಅಥವಾ ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರ)- ಇವುಗಳು ಸರಾಸರಿ ಅಥವಾ ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ಗಡಿಗಳಾಗಿವೆ, ಅದನ್ನು ಮೀರಿ ಯಾದೃಚ್ಛಿಕ ಏರಿಳಿತಗಳ ಕಾರಣದಿಂದಾಗಿ ಅತ್ಯಲ್ಪ ಸಂಭವನೀಯತೆ ಇರುತ್ತದೆ.
ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರವನ್ನು ಹೀಗೆ ಪುನಃ ಬರೆಯಬಹುದು: , ಅಲ್ಲಿ ಟಿ- ವಿಶ್ವಾಸಾರ್ಹ ಮಾನದಂಡ.
ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಅಂಕಗಣಿತದ ಸರಾಸರಿ ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳನ್ನು ಸೂತ್ರದಿಂದ ನಿರ್ಧರಿಸಲಾಗುತ್ತದೆ:
ಎಂ ಜೀನ್ = ಎಂ ಆಯ್ಕೆ ಮಾಡಿ + ಟಿ ಎಂ ಎಂ
ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಕ್ಕಾಗಿ:
ಆರ್ ಜೀನ್ = ಪಿ ಆಯ್ಕೆ ಮಾಡಿ + ಟಿ ಎಂ ಆರ್
ಎಲ್ಲಿ ಎಂ ಜೀನ್ಮತ್ತು ಆರ್ ಜೀನ್- ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಗೆ ಸರಾಸರಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ಮೌಲ್ಯಗಳು; ಎಂ ಆಯ್ಕೆ ಮಾಡಿಮತ್ತು ಆರ್ ಆಯ್ಕೆ ಮಾಡಿ- ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಿಂದ ಪಡೆದ ಸರಾಸರಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ಮೌಲ್ಯಗಳು; ಮೀ ಎಂಮತ್ತು ಮೀ ಪ- ಸರಾಸರಿ ಮತ್ತು ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ದೋಷಗಳು; ಟಿ- ವಿಶ್ವಾಸಾರ್ಹ ಮಾನದಂಡ (ನಿಖರತೆಯ ಮಾನದಂಡ, ಇದು ಅಧ್ಯಯನವನ್ನು ಯೋಜಿಸುವಾಗ ಸ್ಥಾಪಿಸಲ್ಪಡುತ್ತದೆ ಮತ್ತು 2 ಅಥವಾ 3 ಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ); ಟಿ ಎಂ- ಇದು ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರ ಅಥವಾ Δ - ಮಾದರಿ ಅಧ್ಯಯನದಲ್ಲಿ ಪಡೆದ ಸೂಚಕದ ಗರಿಷ್ಠ ದೋಷ.
ಮಾನದಂಡದ ಮೌಲ್ಯವನ್ನು ಗಮನಿಸಬೇಕು ಟಿದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ (p) ಸಂಭವನೀಯತೆಗೆ ಸಂಬಂಧಿಸಿದ ಒಂದು ನಿರ್ದಿಷ್ಟ ಮಟ್ಟಿಗೆ, % ನಲ್ಲಿ ವ್ಯಕ್ತಪಡಿಸಲಾಗಿದೆ. ಇದನ್ನು ಸಂಶೋಧಕರು ಸ್ವತಃ ಆಯ್ಕೆ ಮಾಡುತ್ತಾರೆ, ಅಗತ್ಯವಾದ ನಿಖರತೆಯ ಫಲಿತಾಂಶವನ್ನು ಪಡೆಯುವ ಅಗತ್ಯದಿಂದ ಮಾರ್ಗದರ್ಶನ ನೀಡುತ್ತಾರೆ. ಹೀಗಾಗಿ, 95.5% ನಷ್ಟು ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ ಸಂಭವನೀಯತೆಗಾಗಿ, ಮಾನದಂಡದ ಮೌಲ್ಯ ಟಿ 2, 99.7% - 3.
ಕೊಟ್ಟಿರುವ ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರ ಅಂದಾಜುಗಳು 30 ಕ್ಕಿಂತ ಹೆಚ್ಚು ವೀಕ್ಷಣೆಗಳನ್ನು ಹೊಂದಿರುವ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಜನಸಂಖ್ಯೆಗೆ ಮಾತ್ರ ಸ್ವೀಕಾರಾರ್ಹವಾಗಿವೆ (ಸಣ್ಣ ಮಾದರಿಗಳು), ಟಿ ಮಾನದಂಡವನ್ನು ನಿರ್ಧರಿಸಲು ವಿಶೇಷ ಕೋಷ್ಟಕಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ. ಈ ಕೋಷ್ಟಕಗಳಲ್ಲಿ, ಅಪೇಕ್ಷಿತ ಮೌಲ್ಯವು ಜನಸಂಖ್ಯೆಯ ಗಾತ್ರಕ್ಕೆ ಅನುಗುಣವಾದ ರೇಖೆಯ ಛೇದಕದಲ್ಲಿದೆ (ಎನ್-1), ಮತ್ತು ಸಂಶೋಧಕರು ಆಯ್ಕೆ ಮಾಡಿದ ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ (95.5%; 99.7%) ಸಂಭವನೀಯತೆಯ ಮಟ್ಟಕ್ಕೆ ಅನುಗುಣವಾದ ಕಾಲಮ್. ವೈದ್ಯಕೀಯ ಸಂಶೋಧನೆಯಲ್ಲಿ, ಯಾವುದೇ ಸೂಚಕಕ್ಕೆ ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳನ್ನು ಸ್ಥಾಪಿಸುವಾಗ, ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ ಸಂಭವನೀಯತೆ 95.5% ಅಥವಾ ಹೆಚ್ಚಿನದು. ಇದರರ್ಥ ಮಾದರಿ ಜನಸಂಖ್ಯೆಯಿಂದ ಪಡೆದ ಸೂಚಕದ ಮೌಲ್ಯವು ಕನಿಷ್ಠ 95.5% ಪ್ರಕರಣಗಳಲ್ಲಿ ಸಾಮಾನ್ಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಕಂಡುಬರಬೇಕು.
ಪಾಠದ ವಿಷಯದ ಕುರಿತು ಪ್ರಶ್ನೆಗಳು:
ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಗುಣಲಕ್ಷಣ ವೈವಿಧ್ಯತೆಯ ಸೂಚಕಗಳ ಪ್ರಸ್ತುತತೆ.
ಸಂಪೂರ್ಣ ವ್ಯತ್ಯಾಸ ಸೂಚಕಗಳ ಸಾಮಾನ್ಯ ಗುಣಲಕ್ಷಣಗಳು.
ಪ್ರಮಾಣಿತ ವಿಚಲನ, ಲೆಕ್ಕಾಚಾರ, ಅಪ್ಲಿಕೇಶನ್.
ವ್ಯತ್ಯಾಸದ ಸಾಪೇಕ್ಷ ಕ್ರಮಗಳು.
ಮಧ್ಯಮ, ಕ್ವಾರ್ಟೈಲ್ ಸ್ಕೋರ್.
ಅಧ್ಯಯನದ ಫಲಿತಾಂಶಗಳ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮಹತ್ವವನ್ನು ನಿರ್ಣಯಿಸುವುದು.
ಅಂಕಗಣಿತದ ಸರಾಸರಿ ಪ್ರಮಾಣಿತ ದೋಷ, ಲೆಕ್ಕಾಚಾರದ ಸೂತ್ರ, ಬಳಕೆಯ ಉದಾಹರಣೆ.
ಅನುಪಾತದ ಲೆಕ್ಕಾಚಾರ ಮತ್ತು ಅದರ ಪ್ರಮಾಣಿತ ದೋಷ.
ವಿಶ್ವಾಸಾರ್ಹ ಸಂಭವನೀಯತೆಯ ಪರಿಕಲ್ಪನೆ, ಬಳಕೆಯ ಉದಾಹರಣೆ.
10. ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರದ ಪರಿಕಲ್ಪನೆ, ಅದರ ಅನ್ವಯ.
ಪ್ರಮಾಣಿತ ಉತ್ತರಗಳೊಂದಿಗೆ ವಿಷಯದ ಪರೀಕ್ಷೆಯ ಕಾರ್ಯಗಳು:
1. ಬದಲಾವಣೆಯ ಸಂಪೂರ್ಣ ಸೂಚಕಗಳು ಇದನ್ನು ಉಲ್ಲೇಖಿಸುತ್ತವೆ
1) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
2) ಆಂದೋಲನ ಗುಣಾಂಕ
4) ಮಧ್ಯಮ
2. ವ್ಯತ್ಯಾಸ ಸಂಬಂಧಿತ ಸೂಚಕಗಳು
1) ಪ್ರಸರಣ
4) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
3. ಬದಲಾವಣೆಯ ಸರಣಿಯಲ್ಲಿನ ಆಯ್ಕೆಯ ವಿಪರೀತ ಮೌಲ್ಯಗಳಿಂದ ನಿರ್ಧರಿಸಲ್ಪಡುವ ಮಾನದಂಡ
2) ವೈಶಾಲ್ಯ
3) ಪ್ರಸರಣ
4) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
4. ಎಕ್ಸ್ಟ್ರೀಮ್ ಆಯ್ಕೆಗಳ ವ್ಯತ್ಯಾಸ
2) ವೈಶಾಲ್ಯ
3) ಪ್ರಮಾಣಿತ ವಿಚಲನ
4) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
5. ಅದರ ಸರಾಸರಿ ಮೌಲ್ಯಗಳಿಂದ ವಿಶಿಷ್ಟತೆಯ ವೈಯಕ್ತಿಕ ಮೌಲ್ಯಗಳ ವಿಚಲನಗಳ ಸರಾಸರಿ ಚೌಕವು
1) ಆಂದೋಲನ ಗುಣಾಂಕ
2) ಮಧ್ಯಮ
3) ಪ್ರಸರಣ
6. ಒಂದು ಪಾತ್ರದ ಸರಾಸರಿ ಮೌಲ್ಯಕ್ಕೆ ವ್ಯತ್ಯಾಸದ ಪ್ರಮಾಣದ ಅನುಪಾತ
1) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
2) ಪ್ರಮಾಣಿತ ವಿಚಲನ
4) ಆಂದೋಲನ ಗುಣಾಂಕ
7. ಸರಾಸರಿ ಚದರ ವಿಚಲನದ ಅನುಪಾತವು ಗುಣಲಕ್ಷಣದ ಸರಾಸರಿ ಮೌಲ್ಯಕ್ಕೆ
1) ಪ್ರಸರಣ
2) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
3) ಆಂದೋಲನ ಗುಣಾಂಕ
4) ವೈಶಾಲ್ಯ
8. ಬದಲಾವಣೆಯ ಸರಣಿಯ ಮಧ್ಯದಲ್ಲಿ ಇರುವ ಮತ್ತು ಅದನ್ನು ಎರಡು ಸಮಾನ ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುವ ಆಯ್ಕೆಯು
1) ಮಧ್ಯಮ
3) ವೈಶಾಲ್ಯ
9. ವೈದ್ಯಕೀಯ ಸಂಶೋಧನೆಯಲ್ಲಿ, ಯಾವುದೇ ಸೂಚಕಕ್ಕೆ ವಿಶ್ವಾಸಾರ್ಹ ಮಿತಿಗಳನ್ನು ಸ್ಥಾಪಿಸಿದಾಗ, ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ ಸಂಭವನೀಯತೆಯನ್ನು ಸ್ವೀಕರಿಸಲಾಗುತ್ತದೆ
10. 100 ರಲ್ಲಿ 90 ಮಾದರಿಗಳು ಜನಸಂಖ್ಯೆಯಲ್ಲಿನ ಪ್ಯಾರಾಮೀಟರ್ನ ಸರಿಯಾದ ಅಂದಾಜನ್ನು ನೀಡಿದರೆ, ಇದರರ್ಥ ವಿಶ್ವಾಸಾರ್ಹತೆಯ ಸಂಭವನೀಯತೆ ಪಸಮಾನ
11. 100 ರಲ್ಲಿ 10 ಮಾದರಿಗಳು ತಪ್ಪಾದ ಅಂದಾಜನ್ನು ನೀಡಿದರೆ, ದೋಷದ ಸಂಭವನೀಯತೆಯು ಸಮಾನವಾಗಿರುತ್ತದೆ
12. ಸರಾಸರಿ ಅಥವಾ ಸಾಪೇಕ್ಷ ಮೌಲ್ಯಗಳ ಮಿತಿಗಳು, ಯಾದೃಚ್ಛಿಕ ಆಂದೋಲನಗಳ ಕಾರಣದಿಂದಾಗಿ ಅತ್ಯಲ್ಪ ಸಂಭವನೀಯತೆಯನ್ನು ಹೊಂದಿದೆ - ಇದು
1) ವಿಶ್ವಾಸಾರ್ಹ ಮಧ್ಯಂತರ
2) ವೈಶಾಲ್ಯ
4) ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕ
13. ಒಂದು ಸಣ್ಣ ಮಾದರಿಯನ್ನು ಪರಿಗಣಿಸಲಾಗುತ್ತದೆ ಆ ಜನಸಂಖ್ಯೆ
1) n 100 ಕ್ಕಿಂತ ಕಡಿಮೆ ಅಥವಾ ಸಮಾನವಾಗಿರುತ್ತದೆ
2) n 30 ಕ್ಕಿಂತ ಕಡಿಮೆ ಅಥವಾ ಸಮಾನವಾಗಿರುತ್ತದೆ
3) n 40 ಕ್ಕಿಂತ ಕಡಿಮೆ ಅಥವಾ ಸಮಾನವಾಗಿರುತ್ತದೆ
4) n 0 ಗೆ ಹತ್ತಿರದಲ್ಲಿದೆ
14. ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ ಸಂಭವನೀಯತೆಗಾಗಿ 95% ಮಾನದಂಡದ ಮೌಲ್ಯ ಟಿಇದೆ
15. ದೋಷ-ಮುಕ್ತ ಮುನ್ಸೂಚನೆಯ ಸಂಭವನೀಯತೆಗಾಗಿ 99% ಮಾನದಂಡದ ಮೌಲ್ಯ ಟಿಇದೆ
16. ಸಾಮಾನ್ಯಕ್ಕೆ ಹತ್ತಿರವಿರುವ ವಿತರಣೆಗಳಿಗೆ, ವ್ಯತ್ಯಾಸದ ಗುಣಾಂಕವು ಮೀರದಿದ್ದರೆ ಜನಸಂಖ್ಯೆಯನ್ನು ಏಕರೂಪವೆಂದು ಪರಿಗಣಿಸಲಾಗುತ್ತದೆ
17. ಆಯ್ಕೆ, ವಿಭಜಿಸುವ ಆಯ್ಕೆಗಳು, ಇವುಗಳ ಸಾಂಖ್ಯಿಕ ಮೌಲ್ಯಗಳು ನೀಡಲಾದ ಸರಣಿಯಲ್ಲಿ ಸಂಭವನೀಯ ಗರಿಷ್ಠ 25% ಅನ್ನು ಮೀರುವುದಿಲ್ಲ - ಇದು
2) ಕಡಿಮೆ ಕ್ವಾರ್ಟೈಲ್
3) ಮೇಲಿನ ಕ್ವಾರ್ಟೈಲ್
4) ಕ್ವಾರ್ಟೈಲ್
18. ವಿರೂಪಗೊಳಿಸದ ಮತ್ತು ಉದ್ದೇಶದ ವಾಸ್ತವತೆಯನ್ನು ಸರಿಯಾಗಿ ಪ್ರತಿಬಿಂಬಿಸುವ ಡೇಟಾವನ್ನು ಕರೆಯಲಾಗುತ್ತದೆ
1) ಅಸಾಧ್ಯ
2) ಸಮಾನವಾಗಿ ಸಾಧ್ಯ
3) ವಿಶ್ವಾಸಾರ್ಹ
4) ಯಾದೃಚ್ಛಿಕ
19. "ಮೂರು ಸಿಗ್ಮಾ" ನಿಯಮದ ಪ್ರಕಾರ, ಅದರೊಳಗೆ ಒಂದು ವಿಶಿಷ್ಟತೆಯ ಸಾಮಾನ್ಯ ವಿತರಣೆಯೊಂದಿಗೆ
 ಲೊಕೇಟೆಡ್ ಆಗಿರುತ್ತದೆ
ಲೊಕೇಟೆಡ್ ಆಗಿರುತ್ತದೆ1) 68.3% ಆಯ್ಕೆ
ನಿರೀಕ್ಷೆ ಮತ್ತು ವ್ಯತ್ಯಾಸ
ನಾವು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಅನ್ನು ಅಳೆಯೋಣ ಎನ್ಬಾರಿ, ಉದಾಹರಣೆಗೆ, ನಾವು ಗಾಳಿಯ ವೇಗವನ್ನು ಹತ್ತು ಬಾರಿ ಅಳೆಯುತ್ತೇವೆ ಮತ್ತು ಸರಾಸರಿ ಮೌಲ್ಯವನ್ನು ಕಂಡುಹಿಡಿಯಲು ಬಯಸುತ್ತೇವೆ. ವಿತರಣಾ ಕಾರ್ಯಕ್ಕೆ ಸರಾಸರಿ ಮೌಲ್ಯವು ಹೇಗೆ ಸಂಬಂಧಿಸಿದೆ?
ನಾವು ದಾಳವನ್ನು ದೊಡ್ಡ ಸಂಖ್ಯೆಯ ಬಾರಿ ಸುತ್ತಿಕೊಳ್ಳುತ್ತೇವೆ. ಪ್ರತಿ ಎಸೆಯುವಿಕೆಯೊಂದಿಗೆ ಡೈಸ್ನಲ್ಲಿ ಗೋಚರಿಸುವ ಬಿಂದುಗಳ ಸಂಖ್ಯೆಯು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಆಗಿದೆ ಮತ್ತು 1 ರಿಂದ 6 ರವರೆಗೆ ಯಾವುದೇ ನೈಸರ್ಗಿಕ ಮೌಲ್ಯವನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು. ಎಲ್ಲಾ ಡೈಸ್ ಥ್ರೋಗಳಿಗೆ ಲೆಕ್ಕಹಾಕಿದ ಡ್ರಾಪ್ ಪಾಯಿಂಟ್ಗಳ ಅಂಕಗಣಿತದ ಸರಾಸರಿಯು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಆಗಿದೆ, ಆದರೆ ದೊಡ್ಡದು ಎನ್ಇದು ಒಂದು ನಿರ್ದಿಷ್ಟ ಸಂಖ್ಯೆಗೆ ಒಲವು ತೋರುತ್ತದೆ - ಗಣಿತದ ನಿರೀಕ್ಷೆ M x. ಈ ವಿಷಯದಲ್ಲಿ M x = 3,5.
ಈ ಮೌಲ್ಯವನ್ನು ನೀವು ಹೇಗೆ ಪಡೆದುಕೊಂಡಿದ್ದೀರಿ? ಒಳಗೆ ಬಿಡಿ ಎನ್ಪರೀಕ್ಷೆಗಳು, ಒಮ್ಮೆ ನೀವು 1 ಅಂಕವನ್ನು ಪಡೆದರೆ, ಒಮ್ಮೆ ನೀವು 2 ಅಂಕಗಳನ್ನು ಪಡೆದರೆ, ಹೀಗೆ. ಮತ್ತೆ ಯಾವಾಗ ಎನ್→ ∞ ಫಲಿತಾಂಶಗಳ ಸಂಖ್ಯೆ, ಇದರಲ್ಲಿ ಒಂದು ಬಿಂದು ಸುತ್ತಿಕೊಂಡಿತು, ಹಾಗೆಯೇ, ಆದ್ದರಿಂದ
ಮಾದರಿ 4.5. ದಾಳ
ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವಿತರಣಾ ನಿಯಮವನ್ನು ನಾವು ತಿಳಿದಿದ್ದೇವೆ ಎಂದು ಈಗ ಊಹಿಸೋಣ X, ಅಂದರೆ, ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಎಂದು ನಮಗೆ ತಿಳಿದಿದೆ Xಮೌಲ್ಯಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು X 1 , X 2 , ..., x ಕೆಸಂಭವನೀಯತೆಗಳೊಂದಿಗೆ ಪ 1 , ಪ 2 , ..., ಪಿ ಕೆ.
ನಿರೀಕ್ಷಿತ ಮೌಲ್ಯ M xಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ Xಸಮನಾಗಿರುತ್ತದೆ:
ಉತ್ತರ. 2,8.
ಗಣಿತದ ನಿರೀಕ್ಷೆಯು ಯಾವಾಗಲೂ ಕೆಲವು ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ಸಮಂಜಸವಾದ ಅಂದಾಜು ಆಗಿರುವುದಿಲ್ಲ. ಹೀಗಾಗಿ, ಸರಾಸರಿ ವೇತನವನ್ನು ಅಂದಾಜು ಮಾಡಲು, ಸರಾಸರಿಯ ಪರಿಕಲ್ಪನೆಯನ್ನು ಬಳಸುವುದು ಹೆಚ್ಚು ಸಮಂಜಸವಾಗಿದೆ, ಅಂದರೆ, ಸರಾಸರಿಗಿಂತ ಕಡಿಮೆ ಮತ್ತು ಹೆಚ್ಚಿನ ಸಂಬಳ ಪಡೆಯುವ ಜನರ ಸಂಖ್ಯೆಯು ಹೊಂದಿಕೆಯಾಗುವ ಅಂತಹ ಮೌಲ್ಯ.
ಮಧ್ಯಮಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ ಅನ್ನು ಸಂಖ್ಯೆ ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ X 1/2 ಅಂದರೆ ಪ (X < X 1/2) = 1/2.
ಬೇರೆ ರೀತಿಯಲ್ಲಿ ಹೇಳುವುದಾದರೆ, ಸಂಭವನೀಯತೆ ಪ 1 ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ Xಚಿಕ್ಕದಾಗಿರುತ್ತದೆ X 1/2, ಮತ್ತು ಸಂಭವನೀಯತೆ ಪ 2 ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ Xಹೆಚ್ಚಾಗಿರುತ್ತದೆ X 1/2 ಒಂದೇ ಮತ್ತು 1/2 ಗೆ ಸಮಾನವಾಗಿರುತ್ತದೆ. ಎಲ್ಲಾ ವಿತರಣೆಗಳಿಗೆ ಸರಾಸರಿಯನ್ನು ಅನನ್ಯವಾಗಿ ನಿರ್ಧರಿಸಲಾಗುವುದಿಲ್ಲ.
ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ಗೆ ಹಿಂತಿರುಗೋಣ X, ಇದು ಮೌಲ್ಯಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಬಹುದು X 1 , X 2 , ..., x ಕೆಸಂಭವನೀಯತೆಗಳೊಂದಿಗೆ ಪ 1 , ಪ 2 , ..., ಪಿ ಕೆ.
ವ್ಯತ್ಯಾಸಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ Xಅದರ ಗಣಿತದ ನಿರೀಕ್ಷೆಯಿಂದ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವರ್ಗದ ವಿಚಲನದ ಸರಾಸರಿ ಮೌಲ್ಯವನ್ನು ಕರೆಯಲಾಗುತ್ತದೆ:
ಉದಾಹರಣೆ 2
ಹಿಂದಿನ ಉದಾಹರಣೆಯ ಪರಿಸ್ಥಿತಿಗಳಲ್ಲಿ, ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವ್ಯತ್ಯಾಸ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಿ X.
ಉತ್ತರ. 0,16, 0,4.
ಮಾದರಿ 4.6. ಗುರಿಯತ್ತ ಗುಂಡು ಹಾರಿಸುವುದು
ಉದಾಹರಣೆ 3
ಮೊದಲ ಎಸೆತದಲ್ಲಿ ಡೈಸ್ನಲ್ಲಿ ಕಂಡುಬರುವ ಬಿಂದುಗಳ ಸಂಖ್ಯೆಯ ಸಂಭವನೀಯತೆ ವಿತರಣೆ, ಸರಾಸರಿ, ಗಣಿತದ ನಿರೀಕ್ಷೆ, ವ್ಯತ್ಯಾಸ ಮತ್ತು ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ಕಂಡುಹಿಡಿಯಿರಿ.
ಯಾವುದೇ ಅಂಚು ಸಮಾನವಾಗಿ ಬೀಳುವ ಸಾಧ್ಯತೆಯಿದೆ, ಆದ್ದರಿಂದ ವಿತರಣೆಯು ಈ ರೀತಿ ಕಾಣುತ್ತದೆ:
ಪ್ರಮಾಣಿತ ವಿಚಲನ ಸರಾಸರಿ ಮೌಲ್ಯದಿಂದ ಮೌಲ್ಯದ ವಿಚಲನವು ತುಂಬಾ ದೊಡ್ಡದಾಗಿದೆ ಎಂದು ನೋಡಬಹುದು.
ಗಣಿತದ ನಿರೀಕ್ಷೆಯ ಗುಣಲಕ್ಷಣಗಳು:
- ಸ್ವತಂತ್ರ ಯಾದೃಚ್ಛಿಕ ಅಸ್ಥಿರಗಳ ಮೊತ್ತದ ಗಣಿತದ ನಿರೀಕ್ಷೆಯು ಅವುಗಳ ಗಣಿತದ ನಿರೀಕ್ಷೆಗಳ ಮೊತ್ತಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ:
ಉದಾಹರಣೆ 4
ಎರಡು ದಾಳಗಳ ಮೇಲೆ ಸುತ್ತಿದ ಬಿಂದುಗಳ ಮೊತ್ತ ಮತ್ತು ಉತ್ಪನ್ನದ ಗಣಿತದ ನಿರೀಕ್ಷೆಯನ್ನು ಕಂಡುಹಿಡಿಯಿರಿ.
ಉದಾಹರಣೆ 3 ರಲ್ಲಿ ನಾವು ಒಂದು ಘನಕ್ಕಾಗಿ ಅದನ್ನು ಕಂಡುಕೊಂಡಿದ್ದೇವೆ ಎಂ (X) = 3.5. ಆದ್ದರಿಂದ ಎರಡು ಘನಗಳಿಗೆ
ಪ್ರಸರಣ ಗುಣಲಕ್ಷಣಗಳು:
- ಸ್ವತಂತ್ರ ಯಾದೃಚ್ಛಿಕ ಅಸ್ಥಿರಗಳ ಮೊತ್ತದ ವ್ಯತ್ಯಾಸವು ವ್ಯತ್ಯಾಸಗಳ ಮೊತ್ತಕ್ಕೆ ಸಮಾನವಾಗಿರುತ್ತದೆ:
Dx + ವೈ = Dx + ಡೈ.
ಅವಕಾಶ ಎನ್ಉರುಳಿಸಿದ ದಾಳದ ಮೇಲೆ ಉರುಳುತ್ತದೆ ವೈಅಂಕಗಳು. ನಂತರ
ಈ ಫಲಿತಾಂಶವು ಡೈಸ್ ರೋಲ್ಗಳಿಗೆ ಮಾತ್ರವಲ್ಲ. ಅನೇಕ ಸಂದರ್ಭಗಳಲ್ಲಿ, ಇದು ಗಣಿತದ ನಿರೀಕ್ಷೆಯನ್ನು ಪ್ರಾಯೋಗಿಕವಾಗಿ ಅಳೆಯುವ ನಿಖರತೆಯನ್ನು ನಿರ್ಧರಿಸುತ್ತದೆ. ಹೆಚ್ಚುತ್ತಿರುವ ಅಳತೆಗಳೊಂದಿಗೆ ಇದನ್ನು ಕಾಣಬಹುದು ಎನ್ಸರಾಸರಿ ಮೌಲ್ಯಗಳ ಹರಡುವಿಕೆ, ಅಂದರೆ, ಪ್ರಮಾಣಿತ ವಿಚಲನವು ಪ್ರಮಾಣಾನುಗುಣವಾಗಿ ಕಡಿಮೆಯಾಗುತ್ತದೆ
ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವ್ಯತ್ಯಾಸವು ಈ ಕೆಳಗಿನ ಸಂಬಂಧದಿಂದ ಈ ಯಾದೃಚ್ಛಿಕ ವೇರಿಯಬಲ್ನ ವರ್ಗದ ಗಣಿತದ ನಿರೀಕ್ಷೆಗೆ ಸಂಬಂಧಿಸಿದೆ:
ಈ ಸಮಾನತೆಯ ಎರಡೂ ಬದಿಗಳ ಗಣಿತದ ನಿರೀಕ್ಷೆಗಳನ್ನು ಕಂಡುಹಿಡಿಯೋಣ. ಎ-ಪ್ರಿಯರಿ,
ಸಮಾನತೆಯ ಬಲಭಾಗದ ಗಣಿತದ ನಿರೀಕ್ಷೆಯು ಗಣಿತದ ನಿರೀಕ್ಷೆಗಳ ಆಸ್ತಿಯ ಪ್ರಕಾರ ಸಮಾನವಾಗಿರುತ್ತದೆ
ಪ್ರಮಾಣಿತ ವಿಚಲನ
ಪ್ರಮಾಣಿತ ವಿಚಲನವ್ಯತ್ಯಾಸದ ವರ್ಗಮೂಲಕ್ಕೆ ಸಮ:
ಅಧ್ಯಯನ ಮಾಡಲಾದ ಜನಸಂಖ್ಯೆಯ ಸಾಕಷ್ಟು ದೊಡ್ಡ ಪ್ರಮಾಣದ ಪ್ರಮಾಣಿತ ವಿಚಲನವನ್ನು ನಿರ್ಧರಿಸುವಾಗ (n > 30), ಈ ಕೆಳಗಿನ ಸೂತ್ರಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ:ಸಂಬಂಧಿಸಿದ ಮಾಹಿತಿ.