Bestemmelse af den empiriske fordelingsfunktion
Lad $X$ være en tilfældig variabel. $F(x)$ er fordelingsfunktionen af en given stokastisk variabel. Vi vil udføre $n$ eksperimenter på en given stokastisk variabel under de samme betingelser, uafhængige af hinanden. I dette tilfælde får vi en sekvens af værdier $x_1,\ x_2\ $, ... ,$\ x_n$, som kaldes en prøve.
Definition 1
Hver værdi $x_i$ ($i=1,2\ $, ... ,$ \ n$) kaldes en variant.
Et estimat af den teoretiske fordelingsfunktion er den empiriske fordelingsfunktion.
Definition 3
En empirisk fordelingsfunktion $F_n(x)$ er en funktion, der bestemmer for hver værdi $x$ den relative frekvens af hændelsen $X \
hvor $n_x$ er antallet af muligheder mindre end $x$, $n$ er stikprøvestørrelsen.
Forskellen mellem den empiriske funktion og den teoretiske er, at den teoretiske funktion bestemmer sandsynligheden for hændelsen $X
Egenskaber ved den empiriske distributionsfunktion
Lad os nu overveje flere grundlæggende egenskaber ved fordelingsfunktionen.
Området for funktionen $F_n\left(x\right)$ er segmentet $$.
$F_n\left(x\right)$ er en ikke-aftagende funktion.
$F_n\left(x\right)$ er en venstre kontinuerlig funktion.
$F_n\left(x\right)$ er en stykkevis konstant funktion og stiger kun ved værdipunkter for den tilfældige variabel $X$
Lad $X_1$ være den mindste og $X_n$ den største variant. Derefter $F_n\left(x\right)=0$ for $(x\le X)_1$ og $F_n\left(x\right)=1$ for $x\ge X_n$.
Lad os introducere en sætning, der forbinder de teoretiske og empiriske funktioner.
Sætning 1
Lad $F_n\left(x\right)$ være den empiriske fordelingsfunktion, og $F\left(x\right)$ være den teoretiske fordelingsfunktion af den generelle prøve. Så gælder ligestillingen:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Eksempler på problemer med at finde den empiriske fordelingsfunktion
Eksempel 1
Lad stikprøvefordelingen have følgende data registreret ved hjælp af en tabel:
Billede 1.
Find stikprøvestørrelsen, opret en empirisk distributionsfunktion og plot den.
Prøvestørrelse: $n=5+10+15+20=50$.
Ved egenskab 5 har vi det for $x\le 1$ $F_n\left(x\right)=0$, og for $x>4$ $F_n\left(x\right)=1$.
$x værdi
$x værdi
$x værdi
Således får vi:
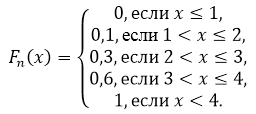
Figur 2.

Figur 3.
Eksempel 2
20 byer blev tilfældigt udvalgt fra byerne i den centrale del af Rusland, for hvilke følgende data om offentlige transportpriser blev opnået: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14.
Opret en empirisk distributionsfunktion for denne prøve og plot den.
Lad os skrive prøveværdierne ned i stigende rækkefølge og beregne frekvensen af hver værdi. Vi får følgende tabel:
Figur 4.
Prøvestørrelse: $n=20$.
Ved egenskab 5 har vi det for $x\le 12$ $F_n\left(x\right)=0$, og for $x>15$ $F_n\left(x\right)=1$.
$x værdi
$x værdi
$x værdi
Således får vi:
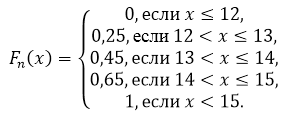
Figur 5.
Lad os plotte den empiriske fordeling:
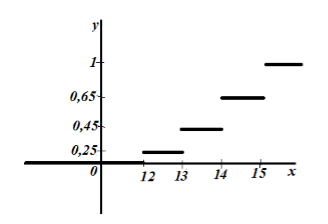
Figur 6.
Originalitet: $92,12\%$.
Bestemmelse af den empiriske fordelingsfunktion
Lad $X$ være en tilfældig variabel. $F(x)$ er fordelingsfunktionen af en given stokastisk variabel. Vi vil udføre $n$ eksperimenter på en given stokastisk variabel under de samme betingelser, uafhængige af hinanden. I dette tilfælde får vi en sekvens af værdier $x_1,\ x_2\ $, ... ,$\ x_n$, som kaldes en prøve.
Definition 1
Hver værdi $x_i$ ($i=1,2\ $, ... ,$ \ n$) kaldes en variant.
Et estimat af den teoretiske fordelingsfunktion er den empiriske fordelingsfunktion.
Definition 3
En empirisk fordelingsfunktion $F_n(x)$ er en funktion, der bestemmer for hver værdi $x$ den relative frekvens af hændelsen $X \
hvor $n_x$ er antallet af muligheder mindre end $x$, $n$ er stikprøvestørrelsen.
Forskellen mellem den empiriske funktion og den teoretiske er, at den teoretiske funktion bestemmer sandsynligheden for hændelsen $X
Egenskaber ved den empiriske distributionsfunktion
Lad os nu overveje flere grundlæggende egenskaber ved fordelingsfunktionen.
Området for funktionen $F_n\left(x\right)$ er segmentet $$.
$F_n\left(x\right)$ er en ikke-aftagende funktion.
$F_n\left(x\right)$ er en venstre kontinuerlig funktion.
$F_n\left(x\right)$ er en stykkevis konstant funktion og stiger kun ved værdipunkter for den tilfældige variabel $X$
Lad $X_1$ være den mindste og $X_n$ den største variant. Derefter $F_n\left(x\right)=0$ for $(x\le X)_1$ og $F_n\left(x\right)=1$ for $x\ge X_n$.
Lad os introducere en sætning, der forbinder de teoretiske og empiriske funktioner.
Sætning 1
Lad $F_n\left(x\right)$ være den empiriske fordelingsfunktion, og $F\left(x\right)$ være den teoretiske fordelingsfunktion af den generelle prøve. Så gælder ligestillingen:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Eksempler på problemer med at finde den empiriske fordelingsfunktion
Eksempel 1
Lad stikprøvefordelingen have følgende data registreret ved hjælp af en tabel:
Billede 1.
Find stikprøvestørrelsen, opret en empirisk distributionsfunktion og plot den.
Prøvestørrelse: $n=5+10+15+20=50$.
Ved egenskab 5 har vi det for $x\le 1$ $F_n\left(x\right)=0$, og for $x>4$ $F_n\left(x\right)=1$.
$x værdi
$x værdi
$x værdi
Således får vi:
Figur 2.
Figur 3.
Eksempel 2
20 byer blev tilfældigt udvalgt fra byerne i den centrale del af Rusland, for hvilke følgende data om offentlige transportpriser blev opnået: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14.
Opret en empirisk distributionsfunktion for denne prøve og plot den.
Lad os skrive prøveværdierne ned i stigende rækkefølge og beregne frekvensen af hver værdi. Vi får følgende tabel:
Figur 4.
Prøvestørrelse: $n=20$.
Ved egenskab 5 har vi det for $x\le 12$ $F_n\left(x\right)=0$, og for $x>15$ $F_n\left(x\right)=1$.
$x værdi
$x værdi
$x værdi
Således får vi:
Figur 5.
Lad os plotte den empiriske fordeling:
Figur 6.
Originalitet: $92,12\%$.
Find ud af, hvad den empiriske formel er. I kemi er EP den enkleste måde at beskrive en forbindelse på - i det væsentlige en liste over de elementer, der udgør en forbindelse baseret på deres procentdel. Det skal bemærkes, at denne enkle formel ikke beskriver bestille atomer i en forbindelse, angiver den blot, hvilke grundstoffer den består af. For eksempel:
- En forbindelse bestående af 40,92% kulstof; 4,58 % brint og 54,5 % oxygen vil have den empiriske formel C 3 H 4 O 3 (et eksempel på, hvordan man finder denne forbindelses EF vil blive diskuteret i anden del).
Forstå udtrykket "procentsammensætning.""Procentsammensætning" refererer til procentdelen af hvert enkelt atom i hele den pågældende forbindelse. For at finde den empiriske formel for en forbindelse, skal du kende den procentvise sammensætning af forbindelsen. Hvis du slår en empirisk formel for lektier op, så vil der højst sandsynligt blive givet procenter.
- For at finde den procentvise sammensætning af en kemisk forbindelse i laboratoriet, udsættes den for nogle fysiske eksperimenter og derefter kvantitativ analyse. Medmindre du er i et laboratorium, behøver du ikke at udføre disse eksperimenter.
Husk på, at du bliver nødt til at beskæftige dig med gramatomer. Et gramatom er en specifik mængde af et stof, hvis masse er lig med dets atommasse. For at finde gramatomet skal du bruge følgende ligning: Procentdelen af et grundstof i en forbindelse divideres med grundstoffets atommasse.
- Lad os for eksempel sige, at vi har en forbindelse, der indeholder 40,92 % kulstof. Atommassen af kulstof er 12, så vores ligning ville være 40,92 / 12 = 3,41.
Vide, hvordan man finder atomforhold. Når du arbejder med en forbindelse, vil du ende med mere end et gramatom. Når du har fundet alle gramatomerne i din forbindelse, skal du se på dem. For at finde atomforholdet skal du vælge den mindste gram-atom værdi, du har beregnet. Så bliver du nødt til at opdele alle gram-atomerne i det mindste gram-atom. For eksempel:
- Lad os sige, at du arbejder med en forbindelse, der indeholder tre gramatomer: 1,5; 2 og 2.5. Det mindste af disse tal er 1,5. For at finde forholdet mellem atomer skal du derfor dividere alle tallene med 1,5 og sætte et forholdstegn imellem dem : .
- 1,5 / 1,5 = 1. 2 / 1,5 = 1,33. 2,5 / 1,5 = 1,66. Derfor er forholdet mellem atomer 1: 1,33: 1,66 .
Forstå, hvordan man konverterer atomforholdsværdier til heltal. Når du skriver en empirisk formel, skal du bruge hele tal. Det betyder, at du ikke kan bruge tal som 1,33. Når du har fundet forholdet mellem atomerne, skal du konvertere brøker (som 1,33) til hele tal (som 3). For at gøre dette skal du finde et heltal og gange hvert tal i det atomare forhold, som du får heltal med. For eksempel:
- Prøv 2. Gang atomforholdstallene (1, 1,33 og 1,66) med 2. Du får 2, 2,66 og 3,32. Disse er ikke heltal, så 2 er ikke passende.
- Prøv 3. Hvis du ganger 1, 1,33 og 1,66 med 3, får du henholdsvis 3, 4 og 5. Derfor har atomforholdet mellem heltal formen 3: 4: 5 .
Forelæsning 13. Begrebet statistiske estimater af stokastiske variable
Lad den statistiske frekvensfordeling af en kvantitativ karakteristik X være kendt. Lad os betegne ved antallet af observationer, hvor værdien af karakteristikken blev observeret til at være mindre end x og med n det samlede antal observationer. Det er klart, den relative hyppighed af begivenhed X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirisk distributionsfunktion(sampling distribution funktion) er en funktion, der bestemmer for hver værdi x den relative frekvens af hændelsen X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
I modsætning til en stikprøves empiriske fordelingsfunktion kaldes populationsfordelingsfunktionen teoretisk fordelingsfunktion. Forskellen på disse funktioner er, at den teoretiske funktion bestemmer sandsynlighed begivenheder X< x, тогда как эмпирическая – relativ hyppighed samme begivenhed.
Når n stiger, vil den relative frekvens af hændelsen X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Egenskaber ved den empiriske distributionsfunktion:
1) Værdierne af den empiriske funktion hører til segmentet
2) - ikke-aftagende funktion
3) Hvis er den mindste mulighed, så = 0 for , hvis er den største mulighed, så = 1 for .
Den empiriske fordelingsfunktion af stikprøven tjener til at estimere populationens teoretiske fordelingsfunktion.
Eksempel. Lad os konstruere en empirisk funktion baseret på stikprøvefordelingen:
| Muligheder | |||
| Frekvenser |
Lad os finde prøvestørrelsen: 12+18+30=60. Den mindste mulighed er 2, så =0 for x £ 2. Værdien af x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Den ønskede empiriske funktion har således formen:
De vigtigste egenskaber ved statistiske estimater
Lad det være nødvendigt at studere nogle kvantitative karakteristika for den generelle befolkning. Lad os antage, at det ud fra teoretiske overvejelser har været muligt at fastslå det hvilken præcis fordelingen har et fortegn, og det er nødvendigt at evaluere de parametre, som den bestemmes af. For eksempel, hvis karakteristikken, der undersøges, er normalfordelt i befolkningen, så er det nødvendigt at estimere den matematiske forventning og standardafvigelse; hvis karakteristikken har en Poisson-fordeling, er det nødvendigt at estimere parameteren l.
Typisk er kun prøvedata tilgængelige, for eksempel værdier af en kvantitativ karakteristik opnået som et resultat af n uafhængige observationer. I betragtning af som uafhængige stokastiske variable kan vi sige det at finde et statistisk estimat af en ukendt parameter af en teoretisk fordeling betyder at finde en funktion af observerede stokastiske variable, der giver en tilnærmet værdi af den estimerede parameter. For at estimere den matematiske forventning til en normalfordeling for eksempel, spilles funktionen af det aritmetiske middelværdi
For at statistiske estimater kan give korrekte tilnærmelser af de estimerede parametre, skal de opfylde visse krav, blandt hvilke de vigtigste er kravene uforskudt Og solvens vurderinger.
Lad være et statistisk estimat af den ukendte parameter for den teoretiske fordeling. Lad estimatet findes fra en stikprøve af størrelse n. Lad os gentage eksperimentet, dvs. lad os udtrække en anden stikprøve af samme størrelse fra den generelle befolkning og, baseret på dens data, opnå et andet skøn. Gentager vi eksperimentet mange gange, får vi forskellige tal. Scoren kan opfattes som en tilfældig variabel, og tallene som dens mulige værdier.
Hvis estimatet giver en omtrentlig værdi i overflod, dvs. hvert tal er større end den sande værdi, og som følge heraf er den matematiske forventning (gennemsnitsværdi) for den stokastiske variabel større end:. Ligeledes hvis det giver et skøn med en ulempe, At .
Således ville brugen af et statistisk estimat, hvis matematiske forventning ikke er lig med den estimerede parameter, føre til systematiske (med samme fortegn) fejl. Hvis det derimod er garanteret mod systematiske fejl.
Uvildigt kaldet et statistisk estimat, hvis matematiske forventning er lig med den estimerede parameter for enhver stikprøvestørrelse.
Fordrevet kaldes et skøn, der ikke opfylder denne betingelse.
Estimatets objektivitet garanterer endnu ikke en god tilnærmelse for den estimerede parameter, da mulige værdier kan være meget spredt omkring dens gennemsnitsværdi, dvs. variansen kan være betydelig. I dette tilfælde kan estimatet fundet fra dataene fra en prøve, for eksempel, vise sig at være væsentligt langt fra gennemsnitsværdien og derfor fra den parameter, der estimeres.
Effektiv er et statistisk estimat, der for en given stikprøvestørrelse n har mindst mulige afvigelse .
Når man overvejer store stikprøver, kræves der statistiske estimater solvens .
Velhavende kaldes et statistisk estimat, som, da n®¥ tenderer i sandsynlighed til den estimerede parameter. For eksempel, hvis variansen af et upartisk estimat har en tendens til nul som n®¥, så viser et sådant estimat sig at være konsistent.