Когда тип тренда установлен, необходимо вычислить оптимальные значения параметров тренда исходя из фактических уровней. Для этого обычно используют метод наименьших квадратов (МНК). Его значение уже рассмотрено в предыдущих главах учебного пособия, в данном случае оптимизация состоит в минимизации суммы квадратов отклонений фактических уровней ряда от выравненных уровней (от тренда). Для каждого типа тренда МНК дает систему нормальных уравнений, решая которую вычисляют параметры тренда. Рассмотрим лишь три такие системы: для прямой, для параболы 2-го порядка и для экспоненты. Приемы определения параметров других типов тренда рассматриваются в специальной монографической литературе.
Для линейного тренда нормальные уравнения МНК имеют вид:


Нормальные уравнения МНК для экспоненты имеют следующий вид:

По данным табл. 9.1 рассчитаем все три перечисленных тренда для динамического ряда урожайности картофеля с целью их сравнения (см. табл. 9.5).
Таблица 9.5
Расчет параметров трендов

Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га; b = 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид:
у ̂ = 172,2 + 4,418t , где t = 0 в 1987 г Это означает,что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 ra a среднегодовой прирост составляет 4,418 ц/га в год
Параметры параболического тренда согласно (9.23) равны- b = 4,418; a = 177,75; с = -0,5571. Уравнение параболического тренда имеет вид у̃ = 177,75 + 4,418t - 0.5571t 2 ; t = 0 в 1991 г. Это означает, что абсолютный прирост урожайности замедляется в среднем на 2·0,56 ц/га в год за год. Сам же абсолютный прирост уже не является константой параболического тренда, а является средней величиной за период. В год, принятый за начало отсчета т.е. 1991 г., тренд проходит через точку с ординатой 77,75 ц/га; Свободный член параболического тренда не является средним уровнем за период. Параметры экспоненциального тренда вычисляются по формулам(9.32) и (9.33) lnа = 56,5658/11 = 5,1423; потенцируя, получаем а = 171,1; lnk = 2,853:110 = 0,025936; потенцируя, получаем k = 1,02628.
Уравнение экспоненциального тренда имеет вид: y ̅ = 171,1·1,02628 t .
Это означает, что среднегодовой темп поста урожайности за период составил 102,63%. В точке принятК начало отсчета, тренд проходит точку с ординатой 171,1 ц/га.
Рассчитанные по уравнениям трендов уровни записаны в трех последних графах табл. 9.5. Как видно по этим данным. расчетные значения уровней по всем трем видам трендов различаются ненамного, так как и ускорение параболы, и темп роста экспоненты невелики. Существенное отличие имеет парабола - рост уровней с 1995 г. прекращается, в то время как при линейном тренде уровни растут и далее, а при экспоненте их ост ускоряется. Поэтому для прогнозов на будущее эти три тренда неравноправны: при экстраполяции параболы на будущие годы уровни резко разойдутся с прямой и экспонентой, что видно из табл. 9.6. В этой таблице представлена распечатка решения на ПЭВМ по программе «Statgraphics» тех же трех трендов. Отличие их свободных членов от приведенных выше объясняется тем, что программа нумерует года не от середины, а от начала, так что свободные члены трендов относятся к 1986 г., для которого t = 0. Уравнение экспоненты на распечатке оставлено в логарифмированном виде. Прогноз сделан на 5 лет вперед, т.е. до 2001 г.. При изменении начала координат (отсчета времени) в уравнении параболы меняется и средний абсолютной прирост, параметр b . так как в результате отрицательного ускорения прирост все время сокращается, а его максимум - в начале периода. Константой параболы является только ускорение.

В строке «Data» приводятся уровни исходного ряда; «Forecast summary» означает сводные данные для прогноза. В следующих строках - уравнения прямой, параболы, экспоненты - в логарифмическом виде. Графа ME означает среднее расхождение между уровнями исходного ряда и уровнями тренда (выравненными). Для прямой и параболы это расхождение всегда равно нулю. Уровни экспоненты в среднем на 0,48852 ниже уровней исходного ряда. Точное совпадение возможно, если истинный тренд - экспонента; в данном случае совпадения нет, но различие, мало. Графа МАЕ -это дисперсия s 2 - мера колеблемости фактических уровней относительно тренда, о чем сказано в п. 9.7. Графа МАЕ - среднее линейное отклонение уровней от тренда по модулю (см. параграф 5.8); графа МАРЕ - относительное линейное отклонение в процентах. Здесь они приведены как показатели пригодности выбранного вида тренда. Меньшую дисперсию и модуль отклонения имеет парабола: она за период 1986 - 1996 гг. ближе к фактическим уровням. Но выбор типа тренда нельзя сводить лишь к этому критерию. На самом деле замедление прироста есть результат большого отрицательного отклонения, т. е. неурожая в 1996 г.
Вторая половина таблицы - это прогноз уровней урожайности по трем видам трендов на годы; t = 12, 13, 14, 15 и 16 от начала отсчета (1986 г.). Прогнозируемые уровни по экспоненте вплоть до 16-го года ненамного выше,.чем по прямой. Уровни тренда-параболы - снижаются, все более расходясь с другими трендами.
Как видно в табл. 9.4, при вычислении параметров тренда уровни исходного ряда входят с разными весами - значениями t p и их квадратов. Поэтому влияние колебаний уровней на параметры тренда зависит от того, на какой номер года приходится урожайный либо неурожайный год. Если резкое отклонение приходится на год с нулевым номером (t i = 0 ), то оно никакого влияния на параметры тренда не окажет, а если попадет на начало и конец ряда, то повлияет сильно. Следовательно, однократное аналитическое выравнивание неполно освобождает параметры тренда от влияния колеблемости, и при сильных колебаниях они могут быть сильно искажены, что в нашем примере случилось с параболой. Для дальнейшего исключения искажающего влияния колебаний на параметры тренда следует применить метод многократного скользящего выравнивания.
Этот прием состоит в том, что параметры тренда вычисляются не сразу по всему ряду, а скользящим методом, сначала за первые т периодов времени или моментов, затем за период от 2-го до т + 1, от 3-го до (т + 2)-го уровня и т.п. Если число исходных уровней ряда равно п, а длина каждой скользящей базы расчета параметров равна т, то число таких скользящих баз t или отдельных значений параметров, которые будут по ним определены, составит:
L = п + 1 - т.
Применение методики скользящего многократного выравнивания рассматривать, как видно из приведенных расчетов, возможно только при достаточно большом числе уровней ряда, как правило 15 и более. Рассмотрим эту методику на примере данных табл. 9.4 -динамики цен на нетопливные товары развивающихся стран, что опять же дает возможность читателю участвовать в небольшом научном исследовании. На этом же примере продолжим и методику прогнозирования в разделе 9.10.
Если вычислять в нашем ряду параметры по 11 -летним периодам (по 11 уровням), то t = 17 + 1 - 11 = 7. Смысл многократного скользящего выравнивания в том, что при последовательных сдвигах базы расчета параметров на концах ее и в середине окажутся разные уровни с разными по знаку и величине отклонениями от тренда. Поэтому при одних сдвигах базы параметры будут завышаться, при других - занижаться, а при последующем усреднении значений параметров по всем сдвигам базы расчета произойдет дальнейшее взаимопогашение искажений параметров тренда колебаниями уровней.
Многократное скользящее выравнивание не только позволяет получить более точную и надежную оценку параметров тренда, но и осуществить контроль правильности выбора типа уравнения тренда. Если окажется, что ведущий параметр тренда, его константа при расчете по скользящим базам не беспорядочно колеблется, а систематически изменяет свою величину существенным образом, значит, тип тренда был выбран неверно, данный параметр константой не является.
Что касается свободного члена при многократном выравнивании, то нет необходимости и, более того, просто неверно вычислять его величину как среднюю по всем сдвигам базы, ибо при таком способе отдельные уровни исходного ряда входили бы в расчет средней с разными весами, и сумма выравненных уровней разошлась бы с суммой членов исходного ряда. Свободный член тренда - это средняя величина уровня за период, при условии отсчета времени от середины периода. При отсчете от начала, если первый уровень t i = 1, свободный член будет равен: a 0 = у ̅ - b ((N-1)/2). Рекомендуется длину скользящей базы расчета параметров тренда выбирать не менее 9-11 уровней, чтобы в достаточной мере погасить колебания уровней. Если исходный ряд очень длинный, база может составлять до 0,7 - 0,8 его длины. Для устранения влияния долго-периодических (циклических) колебаний на параметры тренда, число сдвигов базы должно быть равно или кратно длине цикла колебаний. Тогда начало и конец базы будут последовательно «пробегать» все фазы цикла и при усреднении параметра по всем сдвигам его искажения от циклических колебаний будут взаимопогашаться. Другой способ - взять длину скользящей базы, равной длине цикла, чтобы начало базы и конец базы всегда приходились на одну и ту же фазу цикла колебаний.
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму, проводим расчет среднегодового абсолютного прироста, т. е. параметра b уравнения линейного тренда скользящим способом по 11-летним базам (см. табл. 9.7). В ней же приведен расчет данных, необходимых для последующего изучения колеблемости в параграфе 9.7. Остановимся подробнее на методике многократного выравнивания по скользящим базам. Рассчитаем параметр b по всем базам:

Таблица 9.7
Многократное скользящее выравнивание по прямой


Уравнение тренда: у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г. Итак, индекс цен в среднем за год снижался на 1,433 пункта. Однократное выравнивание по всем 17 уровням может исказить этот параметр, ибо начальный уровень содержит значительное отрицательное отклонение, а конечный уровень - положительное. В самом деле, однократное выравнивание дает величину среднегодового изменения индекса всего на 0,953 пункта.
9.7. Методика изучения и показатели колеблемости
Если при изучении и измерении тенденции динамики колебания уровней играли лишь роль помех, «информационного шума», от которого следовало по возможности абстрагироваться, то в дальнейшем сама колеблемость становится предметом статистического исследования. Значение изучения колебаний уровней динамического ряда очевидно: колебания урожайности, продуктивности скота, производства мяса экономически нежелательны, так как потребность в продукции агрокомплекса постоянна. Эти колебания следует уменьшать, применяя прогрессивную технологию и другие меры. Напротив, сезонные колебания объемов производства зимней и летней обуви, одежды, мороженого, зонтиков, коньков - необходимы и закономерны, так как спрос на эти товары тоже колеблется по сезонам и равномерное производство требует лишних затрат на хранение запасов. Регулирование рыночной экономики как со стороны государства, так и производителей в значительной мере состоит в регулировании колебаний экономических процессов.
Типы колебаний статистических показателей весьма разнообразны, но все же можно выделить три основных: пилообразную или маятниковую колеблемость, циклическую долгопериодическую и случайно распределенную во времени колеблемость. Их свойства и отличия друг от друга хорошо видны при графическом изображении рис. 9.2.
Пилообразная или маятниковая колеблемость состоит в попеременных отклонениях уровней от тренда в одну и в другую сторону. Таковы автоколебания маятника. Такие автоколебания можно наблюдать в динамике урожайности при невысоком уровне агротехники: высокий урожай при благоприятных условиях погоды выносит из почвы больше питательных веществ, чем их образуется естественным путем за год; почва обедняется, что вызывает снижение следу- ющего урожая ниже тренда, он выносит меньше питательных веществ, чем образуется за год, плодородие возрастает и т.д.

Рис. 9.2. Виды колебаний
Циклическая долгопериодическая колеблемость свойственна, например, солнечной активности (10-11-летние циклы), а значит, и связанным с ней на Земле процессам - полярным сияниям, грозовой деятельности, урожайности отдельных культур в ряде районов, некоторым заболеваниям людей, растений. Для этого типа характерны редкая смена знаков отклонений от тренда и кумулятивный (накапливающийся) эффект отклонений одного знака, который может тяжело отражаться на экономике. Зато колебания хорошо прогнозируются.
Случайно распределенная во времени колеблемость - нерегулярная, хаотическая. Она может возникать при наложении (интерференции) множества колебаний с разными по длительности циклами. Но может возникать в результате столь же хаотической колеблемости главной причины существования колебаний, например суммы осадков за летний период, температуры воздуха в среднем за месяц в разные годы.
Для определения типа колебаний применяются графическое изображение, метод «поворотных точек» М. Кендэла, вычисление коэффициентов автокорреляции отклонений от тренда. Эти методы будут рассмотрены далее.
Основными показателями, характеризующими силу колеблемости уровней, выступают уже известные по главе 5 показатели, характеризующие вариацию значений признака в пространственной совокупности. Однако вариация в пространстве и колеблемость во времени принципиально различны. Прежде всего различны их основные причины. Вариация значений признака у одновременно существующих единиц возникает из-за различий в условиях существования единиц совокупности. Например, разная урожайность картофеля в совхозах области в 1990 г. вызвана различиями в плодородии почв, в качестве семян, в агротехнике. А вот суммы эффективных температур за вегетационный период и осадков не являются причинами пространственной вариации, так как в одном и том же году на территории области эти факторы почти не варьируют. Напротив, главными причинами колебания урожайности картофеля в области за ряд лет как раз являются колебания метеорологических факторов, а качество почв колебаний почти не имеет. Что же касается общего прогресса агротехники, то он является причиной тренда, но не колеблемости.
Второе коренное отличие состоит в том, что значения варьирующего признака в пространственной совокупности можно считать в основном не зависимыми друг от друга, напротив, уровни динамического ряда, как правило, являются зависимыми: это показатели развивающегося процесса, каждая стадия которого связана с предыдущими состояниями.
В-третьих, вариация в пространственной совокупности измеряется отклонениями индивидуальных значений признака от среднего значения, а колеблемость уровней динамического ряда измеряется не их отличиями от среднего уровня (эти отличия включают и тренд, и колебания), а отклонениями уровней от тренда.
Поэтому лучше использовать разные термины: различия признака в пространственной совокупности называть только вариацией, но не колебаниями: никто же не станет называть различия численности населения Москвы, Петербурга, Киева и Ташкента «колебаниями числа жителей»! Отклонения уровней динамического ряда от тренда будем называть всегда колеблемостью. Колебания всегда происходят во времени, не может существовать колебаний вне времени, в фиксированный момент.
На основе качественного содержания понятия колеблемости строится и система ее показателей. Показателями силы колебании уровней являются: амплитуда отклонений уровней отдельных периодов или моментов от тренда (по модулю), среднее абсолютное отклонение уровней от тренда (по модулю), среднее квадратическое откло;-нение уровней от тренда. Относительные меры колеблемости: относительное линейное отклонение от тренда и коэффициент колеблемости - аналог коэффициента вариации.
Особенностью методики вычисления средних отклонений от тренда является необходимость учета потерь степеней свободы колебаний на величину, равную числу параметров уравнения тренда. Например, прямая линия имеет два параметра, и, как известно из геометрии, через любые две точки можно провести прямую линию. Значит, имея лишь два уровня, мы проведем линию тренда точно через эти два уровня, и никаких отклонений уровней от тренда не окажется, хотя на самом деле и эти два уровня включали колебания, не были свободны от действия факторов колеблемости. Парабола второго порядка пройдет точно через любые три точки и т.п.
Учитывая потерю степеней свободы, основные абсолютные показатели колеблемости вычисляются по формулам (9.34) и (9.35):
среднее линейное отклонение
 (9.34)
(9.34)
среднее квадратичное отклонение
 (9.35)
(9.35)
где y i - фактический уровень;
y ̂ i - выравненный уровень, тренд;
n - число уровней;
р - число параметров тренда.
Знак времени «t » в скобках после показателя означает, что это показатель не обычной пространственной вариации, как в главе V, а показатель колеблемости во времени.
Относительные показатели колеблемости вычисляются делением абсолютных показателей на средний уровень за весь изучаемый период. Расчет показателей колеблемости проведем по результатам анализа динамики индекса цен (см. табл. 9.7). Тренд примем по результатам многократного скользящего выравнивания, т. е. у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г.
1. Амплитуда колебаний составила от -14,0 в 1986 г. до +15,2 в 1984 г., т.е. 29,2 пункта.
2. Среднее линейное отклонение по модулю найдем, сложив модули |u i | (их сумма равна 132,3), и разделив на (п - р), согласно формуле (9.34):
 =8,82 пункта.
=8,82 пункта.
3. Среднее квадратическое отклонение уровней от тренда по формуле (9.35) составило:
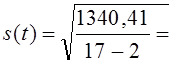 = 9,45 пункта.
= 9,45 пункта.
Небольшое превышение среднего квадратического отклонения над линейным указывает на отсутствие среди отклонений резко выделяющихся по абсолютной величине.
4. Коэффициент колеблемости:  или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
s (t ) = 14,38 ц с 1 га, v (t ) = 8,35%.
Для выявления типа колебаний воспользуемся приемом, предложенным М. Кендэлом. Он состоит в подсчете так называемых «поворотных точек» в ряду отклонений от тренда и i т. е. локальных экстремумов. Отклонение, либо большее по алгебраической величине, либо меньшее двух соседних, отмечается точкой. Обратимся к рис. 9.2. При маятниковой колеблемости все отклонения, кроме двух крайних, будут «поворотными», следовательно, их число составит п - 1. При долгопериодических циклах на цикл приходятся один минимум и один максимум, а общее число точек составит 2(n : l ), где l - длительность цикла. При случайно распределенной во времени колеблемости, как доказал М. Кендэл, число поворотных точек в среднем составит: 2/3 (n - 2). В нашем примере при маятниковой колеблемости было бы 15 точек, при связанной с 11-летним циклом было бы 2-(17: 11) ≈ 3 точки, при случайно распределенной во времени в среднем было бы (2/3)·(17-2) =10 точек.
Фактическое число точек 6 выходит за границы двукратного среднего квадратического отклонения числа поворотных точек, которое по Кендэлу равно , в нашем случае  .
.
Наличие 6 точек, при 2 точках за цикл, означает, что в ряду могут быть примерно 3 цикла, продолжительность периода которых 5,5 - 6 лет. Возможно сочетание таких циклических колебаний со случайными.
Другой метод анализа типа колеблемости и поиска длины цикла основан на вычислении коэффициентов автокорреляции отклонений от тренда.
Автокорреляция - это корреляция между уровнями ряда или отклонениями от тренда, взятыми со сдвигом во времени: на 1 период (год), на 2, на 3 и т. д., поэтому говорят о коэффициентах автокорреляции разных порядков: первого, второго и т. д. Рассмотрим сначала коэффициент автокорреляции отклонений от тренда первого порядка.
Одна из основных формул для расчета коэффициента автокорреляции отклонений от тренда имеет вид:
 (9.36)
(9.36)
Как легко видеть по табл. 9.7, первое и последнее в ряду отклонения участвуют только в одном произведении в числителе, а все прочие отклонения от второго до (п - 1)-го - в двух. Поэтому и в знаменателе квадраты первого и последнего отклонений следует взять с половинным весом, как в хронологической средней. По данным табл. 9.7 имеем:
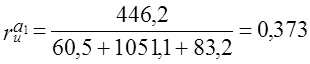
Теперь обратимся к рис. 9.2. При маятниковой колеблемости все произведения в числителе будут отрицательными величинами, и коэффициент автокорреляции первого порядка будет близок к -1. При долголериодических циклах будут преобладать положительные произведения соседних отклонений, а смена знака происходит лишь дважды за цикл. Чем длиннее Цикл, тем больше перевес положительных произведений в числителе, и коэффициент автокорреляции первого порядка ближе к +1. При случайно распределенной во времени колеблемости знаки отклонений чередуются хаотически, число положительных произведений близко к числу отрицательных, ввиду чего коэффициент автокорреляции близок к нулю. Полученное значение говорит о наличии как случайно распределенных во времени колебаний, так и циклических. Коэффициенты автокорреляции следующих порядков: II = - 0,577; Ш = -0,611; IV == -0,095; V = +0,376; VI = +0,404; VII = +0,044. Следовательно, противофаза цикла ближе всего кЗ годам (наибольший отрицательный коэффициент при сдвиге на 3 года), а совпадающие фазы ближе к б годам, что и дает длину цикла колебаний. Эти максимальные по абсолютной величине коэффициенты не близки к единице. Это означает, что циклическая колеблемость смешана со значительной случайной колеблемостью. Таким образом, подробный автокорреляционный анализ в целом дал те же результаты, что и выводы по автокорреляции первого порядка.
Если динамический ряд достаточно длинен, можно поставить и решить задачу об изменении показателей колеблемости с течением времени. Для этого рассчитывают эти показатели по подпериодам, но длительностью не менее 9-11 лет, иначе измерения колеблемости ненадежны. Кроме того, можно рассчитывать показатели колеблемости скользящим способом, а затем произвести их выравнивание, т. е. вычислить тренд показателей колеблемости. Это полезно, чтобы сделать вывод о действенности мер, применявшихся для уменьшения колебаний урожайности и других нежелательных колебаний, а также для того, чтобы по тренду сделать прогноз ожидаемых в будущем размеров колебаний.
9.8. Измерение устойчивости в динамике
Понятие «устойчивость» используется в весьма различных смыслах. По отношению к статистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивость как категория, противоположная колеблемости; 2) устойчивость направленности изменений, т. е. устойчивость тенденции.
В первом понимании показатель устойчивости, который может быть только относительным, должен изменяться от нуля до единицы (100%). Это разность между единицей и относительным показателем колеблемости. Коэффициент колеблемости составил 9,0%. Следовательно, коэффициент устойчивости равен 100% - 9,0% = 91,0%. Этот показатель характеризует близость фактических уровней к тренду и совершенно не зависит от характера последнего. Слабая колеблемость и высокая устойчивость уровней в данном смысле могут существовать даже при полном застое в развитии, когда тренд выражен горизонтальной прямой.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс их направленного изменения. Можно узнать, например, насколько устойчив процесс сокращения удельных затрат ресурсов на производство единицы продукции, является ли устойчивой тенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостью направленного изменения уровней динамического ряда следует считать такое изменение, в процессе которого каждый следующий уровень либо выше всех предшествующих (устойчивый рост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строго ранжированной последовательности уровней свидетельствует о неполной устойчивости изменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя. В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч. Спирмэна (Spearman) - r x .
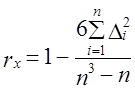
где п - число уровней;
Δ i - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов) времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Это значение соответствует случаю полной устойчивости возрастания уровней. При полной противоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означает полную устойчивость процесса сокращения уровней. При хаотическом чередовании рангов уровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции. Приведем расчет коэффициента корреляции Спирмэна по данным о динамике индекса цен (табл. 9.7) в табл. 9.8.
Таблица 9.8
Расчет коэффициентов корреляции рангов Спирмена
|
Ранг лет, Р x |
Ранг уровней, Р у |
Р x -Р y |
(P x -P y ) 2 |
||
Ввиду наличия трех пар «связанных рангов» применяем формулу (8.26):

Отрицательное значение r x указывает на наличие тенденции снижения уровней, причем устойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в ряду динамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже 100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокий коэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. В целом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большая устойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
Устойчивость тенденции развития или комплексная устойчивость, в динамике может быть охарактеризована соотношением между среднегодовым абсолютным изменением и средним квадратическим (либо линейным) отклонением уровней от тренда:
Если, как нередко бывает, распределение отклонений уровней ряда от тренда близко к нормальному, то с вероятностью 0,95 отклонение от тренда вниз не превысит 1,645s (t ) по величине. Следовательно, если в ряду динамики
с > 1,64, то уровни, более низкие, чем предыдущие, в среднем будут встречаться менее 5раз за 100 периодов, или 1 раз из 20, т. е. устойчивость тренда будет высока. При с = 1 нарушения ранжированности уровней будут встречаться в среднем 16 раз из 100, а при с = 0,5 – уже 31 раз из 100, т. е. устойчивость тенденции будет низкой. Можно также пользоваться отношением среднего темпа прироста к коэффициенту колеблемости, что дает показатель, близкий к с - показателю устойчивости. Этот показатель более пригоден для экспоненциального тренда. О показателях устойчивости нелинейных трендов и об общих проблемах устойчивости экономических и социальных процессов можно подробнее прочесть в рекомендуемой к данной главе литературе .
При использовании полиномов разных степеней оценка параметров уравнения тренда производится методом наименьших квадратов (МНК) точно так же, как оценки параметров уравнения регрессии на основе пространственных данных. В качестве зависимой переменной рассматриваются уровни динамического ряда, а в качестве независимой переменной – фактор времени t, который обычно выражается рядом натуральных чисел 1, 2, ..., п.
Оценка параметров нелинейных функций проводится МНК после линеаризации, т.е. приведения их к линейному виду. Рассмотрим применение МНК для некоторых нелинейных функций, которые не излагались подробно в главе, посвященной регрессии.
Для оценки параметров показательной кривой у = ab 1 или экспоненты у = е а+ы (либо у = ае ы) путем логарифмирования функции приводятся к линейному виду lny = ln a + t ln b или экспоненты: lny = a + bt. Далее строится система нормальных уравнений
Пример 5.1
Число зарегистрированных ДТП (на 100 000 человек населения) по Новгородской области за 2000–2008 гг. характеризуется данными:
Исходя из графика была выбрана показательная кривая / Для построения системы нормальных уравнений были рассчитаны вспомогательные величины

Система нормальных уравнений составила ![]()
Решая ее, получим значения
![]()
Соответственно имеем экспоненту или показательную кривую
За период с 2000 по 2008 г. число дорожно-транспортных происшествий возрастало в среднем ежегодно на 13,5%. Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9202. Следовательно, данный тренд объясняет 92% колеблемости уровней ряда и лишь 8% ее связаны со случайными факторами.
Некоторую специфику имеет оценка параметров кривых с насыщением: модификационной экспоненты, логистической кривой, кривой Гомперца, гиперболы вида По этим функциям должна быть сначала определена асимптота. Если она может быть задана исследователем на основе анализа временного ряда, то другие параметры могут быть оценены по МНК. В этих случаях данные функции приводятся к линейному виду. Рассмотрим оценку параметров этих кривых на отдельных примерах, начиная с модифицированной экспоненты.
Пример 5.2
Уровень механизации труда (в %) характеризуется динамическим рядом (табл. 5.2)
Таблица 5.2. Расчет параметров модифицированной экспоненты у = с ab" t
|
У = с-у |
|||||||
Так как уровень механизации труда не может превышать 100%, то имеется объективно заданная верхняя асимптота с = 100. Для оценки параметров а и b приведем рассматриваемую функцию к линейному виду ; обозначим (с-у) через Y и прологарифмируем:
![]()
Для нашего примера, исходя из данных итоговой строки табл. 3, имеем систему уравнений
![]()
Решив ее, получим ln а = 3,06311; ln b = -0,19744. Соответственно потенцируя, получим: т.е. уравнение .
Если перейти от Y к исходным уровням ряда, уравнение модифицированной экспоненты составит , где параметр показывает средний коэффициент снижения уровня использования ручного труда за 1998–2005 гг. Расчетные значения у, т.е. могут быть найдены путем подстановки в уравнение 0,8208" соответствующих значений t. Либо на основе уравнения In 7= 3,06311 – 0,19744 г при компьютерной обработке определяется In У и далее 100 – е 1пу. Так, при t = 8 In Y = = 1,48363 и 100 – e1"48363 = 100 – 4,40892 = 95,59108 = 95,6 (см. последнюю графу таблицы). Ввиду некоторой смещенности оценок (так как МНК применяется к логарифмам) Ху, Ф Ху, хотя в примере эти величины достаточно близки друг другу.
Если асимптота с не задана, то оценка параметров модифицированной экспоненты усложняется. В этих случаях могут использоваться разные методы оценивания: метод трех сумм, метод трех точек , с помощью регрессии , метод Брианта . Рассмотрим применение метода регрессии для оценки параметров модифицированной экспоненты вида у = с – ab c.
Пример 5.3
В таблице представлены данные о расходах предприятия на рекламу за 10 мес. года.
Таблица 5.3. Данные о расходах предприятия на рекламу за 10 мес. года (в тыс. руб.)
Найдем по нашему ряду цепные абсолютные приростыг и представим их через параметры нашей функции, T.e.z = c-ab" – с + ab"~ l = ab" 1 (1 – b). Известно, что для модифицированной экспоненты логарифм абсолютных приростов линейно зависит от фактора времени t. Следовательно, можно записать, что lnz = Ιηα + (f – 1) lnb + ln(l – b). Обозначим Ιηα + ln(l – b) через d. Тогда lnz = d + (t- 1) lnb, т.е. линейное в логарифмах уравнение. Применяя МНК, получим оценки параметров d, lnb, а соответственно и параметра Ь. В рассматриваемом примере на основании граф табл. 5.3 lnz и (t – 1) было найдено уравнение регрессии: lnz = 4,519641 – 0,20882 (t – 1). Исходя из него получаем lnb = -0,20882; b = 0,811538. 4,519641 = In a + In (1 – b) = In [α (1 – b)]. Тогда α (1 – b) = e4,519641, откуда параметра =91,80264/(1-0,811538) = 487,1145.
Далее можно найти оценку параметра с как среднее значение из величин с = у + ab", найденных для каждого месяца (см. последнюю графу табл. 5.3). Предельная величина расходов на рекламу составит 516,4 тыс. руб. Искомое уравнение тренда примет вид
Рассмотренный метод применим, если абсолютные приросты – величины положительные. Если же некоторые приросты окажутся меньше нуля, то нужно проводить сглаживание уровней временного ряда методом скользящей средней.
Для логистической кривой Перла – Рида аналогично параметры а и b могут быть найдены МНК, если асимптота с задана. Тогда данная функция преобразовывается в линейную из логарифмов ![]() обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
Для логистической кривой вида параметры а и b могут быть оценены МНК, если асимптота с задана, так как в этом случае функция линеаризуема: ; обозначим через Y величину и прологарифмируем: Далее, применяя МНК, оцениваем параметры а и b.
При практических расчетах значение верхней асимптоты логистической кривой может быть определено исходя из существа развития явления, различного рода ограничений для его роста (нормативы потребления, законодательные акты), а также графически.
Если верхняя асимптота не задана, то для оценки параметров могут использоваться разные методы: Фишера, Юла, Родса, Нейра и др. Сравнительная оценка и обзор этих методов изложены в работе E. М. Четыркина .
Покажем на примере расчет параметров логистической кривой по методу Фишера.
Пример 5.4
Производство продукции характеризуется данными, представленными в табл. 5.4.
Таблица 5.4. Расчет параметров логистической кривой
Метод Фишера основан на определении производной для логистической кривой. Дифференцируя данную функцию по t, получим уравнение
Обозначим темп прироста логистической кривой через . Тогда , т.е. для z,
имеем линейную функцию с параметрами а
и . Чтобы найти решение, необходимо оценить z,. Предполагая, что интервалы между уровнями в ряду динамики равны, Фишер предложил приближенно оценивать в виде уравнения , где п
- 1. Для нашего примера значения z, представлены в графе 3 табл. 5.4. Далее применяем МНК к уравнению: , т.е. строим регрессию z(оту(, беря данные от t = 2 до f = 8. Уравнение регрессии запишется в виде Исходя из него находим параметры а и с для логистической кривой. Параметр а =
0,806. Данное уравнение статистически значимо: F-критерий равен 689,6; R
2 = 0,996. Соответственно для него значимы и параметры: f-критерий для параметра а
равен 47,2 и для параметра – равен -26,2. Так как , то и ![]() т.е. верхняя асимптота производства продукции составляет 403 ед.
т.е. верхняя асимптота производства продукции составляет 403 ед.
После того, как найдены параметры а и с, находим параметр b . Для этого функциюпредставим как Обозначим через Y выражение в левой части равенства, т.е..-Тогда имеем уравнение Прологарифмируем его:. В этом уравнении свободным членом является In Ь. Его можно определить из первого уравнения системы нормальных уравнений, а именно Для нашего примера имеем уравнение . Соответственно Таким образом, логистическая кривая запишется в виде
![]()
Теоретические значения данной функции представлены в графе 6 табл. 5.4 (найдены путем подстановки соответствующих значений t). Они достаточно близко подходят к исходным данным: коэффициент корреляции между ними равен 0,999; ввиду того, что в расчетах использовались логарифмы. Если предположить, что предельное значение объема производства продукции равно 400 ед., т.е. применить МНК к уравнению , то получим и b = =67,5; параметр а при компьютерной обработке определяется как -а = -0,8. Соответственно уравнение тренда запишется в виде . Результаты двух уравнений достаточно близки.
Параметры кривой Гомперца также могут быть оценены МНК, если асимптота с задана, так как в этом случае данная функция сводима к линейному виду Прологарифмировав ее, получим уравнение .
Вторично прологарифмировав, получим уравнение ![]() , Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
, Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
При практическом применении кривой Гомперца могут возникнуть некоторые сложности по динамическому ряду с повышающейся тенденцией. В этом случае задается верхняя асимптота с и логарифмы При повторном логарифмировании в расчетах используются лишь положительные значения Продемонстрируем возможность оценки параметров кривой Гомперца с верхней асимптотой на примере динамики по предприятию товарных запасов на начало каждого месяца (тыс. долл.).
Таблица 5.5. Расчет параметров кривой Гомперца
Кривые роста, описывающие закономерности развития явлений во времени – это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценка) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выровненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут, в общем, существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1. Линейная форма тренда:
где – уровень ряда, полученный в результате выравнивания по прямой; – начальный уровень тренда; – средний абсолютный прирост, константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2. Параболическая (полином 2-ой степени) форма тренда:
 (3.6)
(3.6)
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t .
3. Логарифмическая форма тренда:
 , (3.7)
, (3.7)
где – константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
4. Мультипликативная (степенная) форма тренда:
 (3.8)
(3.8)
5. Полином 3-ей степени:
Естественно, кривых, описывающих основные тенденции, гораздо больше. Однако формат учебного пособия не позволяет описать все их многообразие. Показанные далее приемы построения моделей позволят пользователю самостоятельно использовать другие функции, в частности обратные.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать дополнительную переменную на листе с исходными данными переменной «ВГ2001-2010», который следует сделать активным.
Нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Создаем переменную «Т», содержащую интервалы времени, 10 годам (с 2001 по 2010). Переменная «Т» будет состоять из натуральных чисел от 1 до 10, соответствующих указанным годам.
В итоге получается следующий рабочий лист (рис. 3.6)

Рис. 3.6. Рабочий лист с созданной переменной времени
Далее рассмотрим процедуру, позволяющую строить регрессионные модели как линейного, так и нелинейного типа. Для этого выбираем: Statistics/Advanced Linear/Nonlinear Models/Nonlinear Estimation (рис. 3.7). В появившемся окне (рис. 3.8) выбираем функцию User-specified Regression, Least Squares (построение моделей регрессии пользователем вручную, параметры уравнения находятся по методу наименьших квадратов (МНК)).
В следующем диалоговом окне (рис. 3.9) нажимаем на кнопку Function to be estimated , чтобы попасть на экран для задания модели вручную (рис. 3.10).

Рис. 3.7. Запуск процедуры Statistics/Advanced Linear/
Nonlinear Models/Nonlinear Estimation

Рис. 3.8. Окно процедуры Nonlinear Estimation

Рис. 3.9ю Окно процедуры User-Specified Regression, Least Squares

Рис. 3.10. Окно для реализации процедуры
задания уравнения тренда вручную
В верхней части экрана находится поле для ввода функции, в нижней части располагаются примеры ввода функций для различных ситуаций.
Прежде чем сформировать интересующие нас модели, необходимо пояснить некоторые условные обозначения. Переменные уравнений задаются в формате «v №», где «v » обозначает переменную (от англ. «variable »), а «№» – номер столбца, в котором она расположена в таблице на рабочем листе с исходными данными. Если переменных очень много, то справа находится кнопка Review vars , позволяющая выбирать их из списка по названиям и просматривать их параметры с помощью кнопки Zoom (рис. 3.11).

Рис. 3.11. Окно выбора переменной с помощью кнопки Review vars
Параметры уравнений обозначаются любыми латинскими буквами, не обозначающими какое-либо математическое действие. Для упрощения работы предлагается обозначать параметры уравнения так, как в описании уравнений тренда – латинской буквой «а », последовательно присваивая им порядковые номера. Знаки математических действий (вычитания, сложения, умножения и пр.) задаются в обычном для Windows -приложений формате. Пробелы между элементами уравнения не требуются.
Итак, рассмотрим первую модель тренда – линейную, .
Следовательно, после набора она будет выглядеть следующим образом:
![]() ,
,
где v 1 – это столбец на листе с исходными данными, в котором находятся значения исходного динамического ряда; а 0 и а 1 – параметры уравнения; v 2 – столбец на листе с исходными данными, в котором находятся значения интервалов времени (переменная Т) (рис. 3.12).
После этого дважды нажимаем кнопку ОК .

Рис. 3.12. Окно процедуры задания уравнения линейного тренда

Рис. 3.13. Закладка Quick процедуры оценки уравнения тренда.
В появившемся окне (рис. 3.13) можно выбрать метод оценки параметров уравнения регрессии (Estimation method ), если это необходимо. В нашем случае нужно перейти к закладке Advanced и нажать на кнопку Start values (рис. 3.14). В этом диалоге задаются стартовые значения параметров уравнения для их нахождения по МНК, т.е. их минимальные значения. Изначально они заданы как 0,1 для всех параметров. В нашем случае можно оставить эти значения в том же виде, но если значения в наших исходных данных меньше единицы, то необходимо задать их в виде 0,001 для всех параметров уравнения тренда (рис. 3.15). Далее нажимаем кнопку ОК .

Рис. 3.14. Закладка Advanced процедуры оценки уравнения тренда

Рис. 3.15. Окно задания стартовыхзначений параметров уравнения тренда

Рис. 3.16. Закладка Quick окна результатов регрессионного анализа
На закладке Quick (рис.3.16) очень важным является значение строчки Proportion of variance accounted for , которое соответствует коэффициенту детерминации; это значение лучше записать отдельно, так как в дальнейшем оно выводиться не будет, и пользователю придется рассчитывать коэффициент вручную, при этом достаточно трех знаков после запятой. Далее нажимаем кнопку Summary: Parameter estimates для получения данных о параметрах линейного уравнения тренда (рис. 3.17).

Рис. 3.17. Результаты расчета параметров линейной модели тренда
Столбец Estimate – числовые значения параметров уравнения; Standard еrror – стандартная ошибка параметра; t-value – расчетное значение t -критерия; df – число степеней свободы (n -2); p-level – расчетный уровень значимости; Lo. Conf. Limit и Up. Conf. Limit – соответственно нижняя и верхняя граница доверительных интервалов для параметров уравнения с установленной вероятностью (указана как Level of Confidence в верхнем поле таблицы).
Соответственно уравнение линейно модели тренда имеет вид .
После этого возвращаемся к анализу и нажимаем на кнопку Analysis of Variance (дисперсионный анализ) на той же закладке Quick (см. рис. 3.16).

Рис. 3.18. Результаты дисперсионного анализа линейной модели тренда
В верхней заголовочной строке таблицы выдаются пять оценок:
Sum of Squares – сумма квадратов отклонений; df – число степеней свободы; Mean Squares – средний квадрат; F-value – критерий Фишера; p-value – расчетный уровень значимости F -критерия.
В левом столбце указывается источник вариации:
Regression – вариация, объясненная уравнением тренда; Residual – вариация остатков – отклонений фактических значений от выровненных (полученных по уравнению тренда); Total – общая вариация переменной.
На пересечении столбцов и строк получаем однозначно определенные показатели, расчетные формулы для которых представлены в табл. 3.2,
Таблица 3.2
Расчет показателей вариации трендовых моделей
| Source | df | Sum of Squares | Mean squares | F-value |
| Regression | m |  |  |  |
| Residual | n-m |  |  | |
| Total | n |  | ||
| Corrected Total | n-1 |  |  | |
| Regresion vs. Corrected Total | m | SSR | MSR |  |
где – выровненные значения уровней динамического ряда; – фактические значения уровней динамического ряда; – среднее значение уровней динамического ряда.
SSR (Regression Sum of Squares) – сумма квадратов прогнозных значений; SSE (Residual Sum of Squares) – сумма квадратов отклонений теоретических и фактических значений (для расчета остаточной, необъясненной дисперсии); SST (TotalSum of Squares) – сумма первой и второй строчки (сумма квадратов фактических значений); SSCT (Corrected TotalSum of Squares) – сумма квадратов отклонений фактических значений от средней величины (для расчета общей дисперсии); Regression vs. Corrected Total Sum of Squares – повторение первой строчки; MSR (Regression Mean Squares) – объясненная дисперсия; MSE (Residual Mean Squares) – остаточная, необъясненная дисперсия; MSCT (Mean Squares Corrected Total) – скорректированная общая дисперсия; Regression vs. Corrected Total Mean Squares – повторение первой строчки; Regression F-value – расчетное значение F -критерия; Regression vs. Corrected Total F-value – скорректированное расчетное значение F -критерия; n – число уровней ряда; m – число параметров уравнения тренда.
Далее опять же на закладке Quick (см. рис. 3.16) нажимаем кнопку Predicted values, Residuals, etc . После ее нажатия система строит таблицу, состоящую из трех столбцов (рис. 3.19).
Observed – наблюдаемые значения (то есть уровни исходного динамического ряда);
ПРИМЕР . Статистическое изучение динамики численности населения.
С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
Метод аналитического выравнивания а) Линейное уравнение тренда имеет вид y = bt + a 1. Находим параметры уравнения методом наименьших квадратов . Используем способ отсчета времени от условного начала. Система уравнений МНК для линейного тренда имеет вид: a 0 n + a 1 ∑t = ∑y a 0 ∑t + a 1 ∑t 2 = ∑y t
Для наших данных система уравнений примет вид: 10a 0 + 0a 1 = 10400 0a 0 + 330a 1 = -4038 Из первого уравнения выражаем а 0 и подставим во второе уравнение Получаем a 0 = -12.236, a 1 = 1040 Уравнение тренда: y = -12.236 t + 1040
Оценим
качество уравнения тренда с помощью
ошибки абсолютной аппроксимации.
Ошибка
аппроксимации в пределах 5%-7% свидетельствует
о хорошем подборе уравнения тренда к
исходным данным.![]()
б) выравнивание по параболе Уравнение тренда имеет вид y = at 2 + bt + c 1. Находим параметры уравнения методом наименьших квадратов. Система уравнений МНК: a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
Для наших данных система уравнений имеет вид 10a 0 + 0a 1 + 330a 2 = 10400 0a 0 + 330a 1 + 0a 2 = -4038 330a 0 + 0a 1 + 19338a 2 = 353824 Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5 Уравнение тренда: y = 1.258t 2 -12.236t+998.5
Ошибка
аппроксимации для параболического
уравнения тренда.
![]() Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный
прогноз.
Определим среднеквадратическую
ошибку прогнозируемого показателя.
![]() m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
![]() L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)
L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
и таблица следующего вида:
| t | y | t 2 | y 2 | t y | y(t) |
| 1 | |||||
| ... | ... | ... | ... | ... | ... |
| N | |||||
| ИТОГО | ∑ | ∑ | ∑ | ∑ | ∑ |
Инструкция . Укажите количество данных (количество строк). Полученное решение сохраняется в файле Word и Excel .
Тенденция временного ряда характеризует совокупность факторов, оказывающих долговременное влияние и формирующих общую динамику изучаемого показателя.
Способ отсчета времени от условного начала
Для определения параметров математической функции при анализе тренда в рядах динамики используется способ отсчета времени от условного начала. Он основан на обозначении в ряду динамики показаний времени таким образом, чтобы ∑t i . При этом в ряду динамики с нечетным числом уровней порядковый номер уровня, находящегося в середине ряда, обозначают через нулевое значение и принимают его за условное начало отсчета времени с интервалом +1 всех последующих уровней и –1 всех предыдущих уровней. Например, при обозначения времени будут: –2, –1, 0, +1, +2 . При четном числе уровней порядковые номера верхней половины ряда (от середины) обозначаются числами: –1, –3, –5 , а нижней половины ряда обозначаются +1, +3, +5 .Пример . Статистическое изучение динамики численности населения.
- С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
- С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
- Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
| 1990 | 1996 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| 1249 | 1133 | 1043 | 1030 | 1016 | 1005 | 996 | 985 | 975 | 968 |
а) Линейное уравнение тренда имеет вид y = bt + a
1. Находим параметры уравнения методом наименьших квадратов
. Используем способ отсчета времени от условного начала.
Система уравнений МНК для линейного тренда имеет вид:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y |
| -9 | 1249 | 81 | 1560001 | -11241 |
| -7 | 1133 | 49 | 1283689 | -7931 |
| -5 | 1043 | 25 | 1087849 | -5215 |
| -3 | 1030 | 9 | 1060900 | -3090 |
| -1 | 1016 | 1 | 1032256 | -1016 |
| 1 | 1005 | 1 | 1010025 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 |
| 5 | 985 | 25 | 970225 | 4925 |
| 7 | 975 | 49 | 950625 | 6825 |
| 9 | 968 | 81 | 937024 | 8712 |
| 0 | 10400 | 330 | 10884610 | -4038 |
Для наших данных система уравнений примет вид:
10a 0 + 0a 1 = 10400
0a 0 + 330a 1 = -4038
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.236, a 1 = 1040
Уравнение тренда:
y = -12.236 t + 1040
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
![]()
б) выравнивание по параболе
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y
a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt
a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
| t | y | t 2 | y 2 | t y | t 3 | t 4 | t 2 y |
| -9 | 1249 | 81 | 1560001 | -11241 | -729 | 6561 | 101169 |
| -7 | 1133 | 49 | 1283689 | -7931 | -343 | 2401 | 55517 |
| -5 | 1043 | 25 | 1087849 | -5215 | -125 | 625 | 26075 |
| -3 | 1030 | 9 | 1060900 | -3090 | -27 | 81 | 9270 |
| -1 | 1016 | 1 | 1032256 | -1016 | -1 | 1 | 1016 |
| 1 | 1005 | 1 | 1010025 | 1005 | 1 | 1 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 | 27 | 81 | 8964 |
| 5 | 985 | 25 | 970225 | 4925 | 125 | 625 | 24625 |
| 7 | 975 | 49 | 950625 | 6825 | 343 | 2401 | 47775 |
| 9 | 968 | 81 | 937024 | 8712 | 729 | 6561 | 78408 |
| 0 | 10400 | 330 | 10884610 | -4038 | 0 | 19338 | 353824 |
Для наших данных система уравнений имеет вид
10a 0 + 0a 1 + 330a 2 = 10400
0a 0 + 330a 1 + 0a 2 = -4038
330a 0 + 0a 1 + 19338a 2 = 353824
Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5
Уравнение тренда:
y = 1.258t 2 -12.236t+998.5
Ошибка аппроксимации для параболического уравнения тренда.
![]()
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.

m = 1 - количество влияющих факторов в уравнении тренда.
Uy = y n+L ± K
где

L - период упреждения; у n+L - точечный прогноз по модели на (n + L)-й момент времени; n - количество наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого показателя; T табл - табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2
.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (8;0.025) = 2.306
Точечный прогноз, t = 10: y(10) = 1.26*10 2 -12.24*10 + 998.5 = 1001.89 тыс. чел.
1001.89 - 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный прогноз:
t = 9+1 = 10: (930.76;1073.02)