Когда тип тренда установлен, необходимо вычислить оптимальные значения параметров тренда исходя из фактических уровней. Для этого обычно используют метод наименьших квадратов (МНК). Его значение уже рассмотрено в предыдущих главах учебного пособия, в данном случае оптимизация состоит в минимизации суммы квадратов отклонений фактических уровней ряда от выравненных уровней (от тренда). Для каждого типа тренда МНК дает систему нормальных уравнений, решая которую вычисляют параметры тренда. Рассмотрим лишь три такие системы: для прямой, для параболы 2-го порядка и для экспоненты. Приемы определения параметров других типов тренда рассматриваются в специальной монографической литературе.
Для линейного тренда нормальные уравнения МНК имеют вид:


Нормальные уравнения МНК для экспоненты имеют следующий вид:

По данным табл. 9.1 рассчитаем все три перечисленных тренда для динамического ряда урожайности картофеля с целью их сравнения (см. табл. 9.5).
Таблица 9.5
Расчет параметров трендов
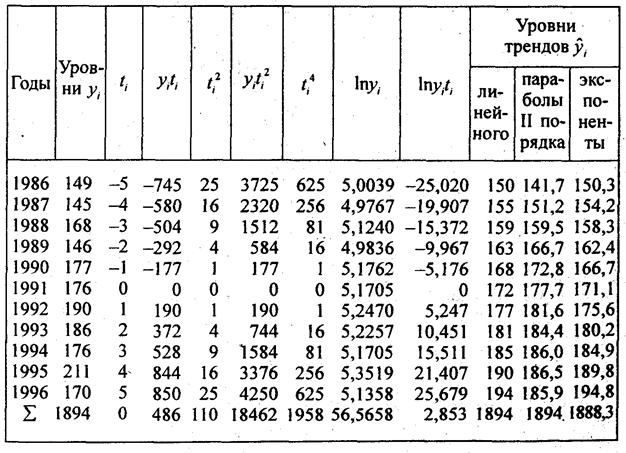
Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га; b = 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид:
у ̂ = 172,2 + 4,418t , где t = 0 в 1987 г Это означает,что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 ra a среднегодовой прирост составляет 4,418 ц/га в год
Параметры параболического тренда согласно (9.23) равны- b = 4,418; a = 177,75; с = -0,5571. Уравнение параболического тренда имеет вид у̃ = 177,75 + 4,418t - 0.5571t 2 ; t = 0 в 1991 г. Это означает, что абсолютный прирост урожайности замедляется в среднем на 2·0,56 ц/га в год за год. Сам же абсолютный прирост уже не является константой параболического тренда, а является средней величиной за период. В год, принятый за начало отсчета т.е. 1991 г., тренд проходит через точку с ординатой 77,75 ц/га; Свободный член параболического тренда не является средним уровнем за период. Параметры экспоненциального тренда вычисляются по формулам(9.32) и (9.33) lnа = 56,5658/11 = 5,1423; потенцируя, получаем а = 171,1; lnk = 2,853:110 = 0,025936; потенцируя, получаем k = 1,02628.
Уравнение экспоненциального тренда имеет вид: y ̅ = 171,1·1,02628 t .
Это означает, что среднегодовой темп поста урожайности за период составил 102,63%. В точке принятК начало отсчета, тренд проходит точку с ординатой 171,1 ц/га.
Рассчитанные по уравнениям трендов уровни записаны в трех последних графах табл. 9.5. Как видно по этим данным. расчетные значения уровней по всем трем видам трендов различаются ненамного, так как и ускорение параболы, и темп роста экспоненты невелики. Существенное отличие имеет парабола - рост уровней с 1995 г. прекращается, в то время как при линейном тренде уровни растут и далее, а при экспоненте их ост ускоряется. Поэтому для прогнозов на будущее эти три тренда неравноправны: при экстраполяции параболы на будущие годы уровни резко разойдутся с прямой и экспонентой, что видно из табл. 9.6. В этой таблице представлена распечатка решения на ПЭВМ по программе «Statgraphics» тех же трех трендов. Отличие их свободных членов от приведенных выше объясняется тем, что программа нумерует года не от середины, а от начала, так что свободные члены трендов относятся к 1986 г., для которого t = 0. Уравнение экспоненты на распечатке оставлено в логарифмированном виде. Прогноз сделан на 5 лет вперед, т.е. до 2001 г.. При изменении начала координат (отсчета времени) в уравнении параболы меняется и средний абсолютной прирост, параметр b . так как в результате отрицательного ускорения прирост все время сокращается, а его максимум - в начале периода. Константой параболы является только ускорение.

В строке «Data» приводятся уровни исходного ряда; «Forecast summary» означает сводные данные для прогноза. В следующих строках - уравнения прямой, параболы, экспоненты - в логарифмическом виде. Графа ME означает среднее расхождение между уровнями исходного ряда и уровнями тренда (выравненными). Для прямой и параболы это расхождение всегда равно нулю. Уровни экспоненты в среднем на 0,48852 ниже уровней исходного ряда. Точное совпадение возможно, если истинный тренд - экспонента; в данном случае совпадения нет, но различие, мало. Графа МАЕ -это дисперсия s 2 - мера колеблемости фактических уровней относительно тренда, о чем сказано в п. 9.7. Графа МАЕ - среднее линейное отклонение уровней от тренда по модулю (см. параграф 5.8); графа МАРЕ - относительное линейное отклонение в процентах. Здесь они приведены как показатели пригодности выбранного вида тренда. Меньшую дисперсию и модуль отклонения имеет парабола: она за период 1986 - 1996 гг. ближе к фактическим уровням. Но выбор типа тренда нельзя сводить лишь к этому критерию. На самом деле замедление прироста есть результат большого отрицательного отклонения, т. е. неурожая в 1996 г.
Вторая половина таблицы - это прогноз уровней урожайности по трем видам трендов на годы; t = 12, 13, 14, 15 и 16 от начала отсчета (1986 г.). Прогнозируемые уровни по экспоненте вплоть до 16-го года ненамного выше,.чем по прямой. Уровни тренда-параболы - снижаются, все более расходясь с другими трендами.
Как видно в табл. 9.4, при вычислении параметров тренда уровни исходного ряда входят с разными весами - значениями t p и их квадратов. Поэтому влияние колебаний уровней на параметры тренда зависит от того, на какой номер года приходится урожайный либо неурожайный год. Если резкое отклонение приходится на год с нулевым номером (t i = 0 ), то оно никакого влияния на параметры тренда не окажет, а если попадет на начало и конец ряда, то повлияет сильно. Следовательно, однократное аналитическое выравнивание неполно освобождает параметры тренда от влияния колеблемости, и при сильных колебаниях они могут быть сильно искажены, что в нашем примере случилось с параболой. Для дальнейшего исключения искажающего влияния колебаний на параметры тренда следует применить метод многократного скользящего выравнивания.
Этот прием состоит в том, что параметры тренда вычисляются не сразу по всему ряду, а скользящим методом, сначала за первые т периодов времени или моментов, затем за период от 2-го до т + 1, от 3-го до (т + 2)-го уровня и т.п. Если число исходных уровней ряда равно п, а длина каждой скользящей базы расчета параметров равна т, то число таких скользящих баз t или отдельных значений параметров, которые будут по ним определены, составит:
L = п + 1 - т.
Применение методики скользящего многократного выравнивания рассматривать, как видно из приведенных расчетов, возможно только при достаточно большом числе уровней ряда, как правило 15 и более. Рассмотрим эту методику на примере данных табл. 9.4 -динамики цен на нетопливные товары развивающихся стран, что опять же дает возможность читателю участвовать в небольшом научном исследовании. На этом же примере продолжим и методику прогнозирования в разделе 9.10.
Если вычислять в нашем ряду параметры по 11 -летним периодам (по 11 уровням), то t = 17 + 1 - 11 = 7. Смысл многократного скользящего выравнивания в том, что при последовательных сдвигах базы расчета параметров на концах ее и в середине окажутся разные уровни с разными по знаку и величине отклонениями от тренда. Поэтому при одних сдвигах базы параметры будут завышаться, при других - занижаться, а при последующем усреднении значений параметров по всем сдвигам базы расчета произойдет дальнейшее взаимопогашение искажений параметров тренда колебаниями уровней.
Многократное скользящее выравнивание не только позволяет получить более точную и надежную оценку параметров тренда, но и осуществить контроль правильности выбора типа уравнения тренда. Если окажется, что ведущий параметр тренда, его константа при расчете по скользящим базам не беспорядочно колеблется, а систематически изменяет свою величину существенным образом, значит, тип тренда был выбран неверно, данный параметр константой не является.
Что касается свободного члена при многократном выравнивании, то нет необходимости и, более того, просто неверно вычислять его величину как среднюю по всем сдвигам базы, ибо при таком способе отдельные уровни исходного ряда входили бы в расчет средней с разными весами, и сумма выравненных уровней разошлась бы с суммой членов исходного ряда. Свободный член тренда - это средняя величина уровня за период, при условии отсчета времени от середины периода. При отсчете от начала, если первый уровень t i = 1, свободный член будет равен: a 0 = у ̅ - b ((N-1)/2). Рекомендуется длину скользящей базы расчета параметров тренда выбирать не менее 9-11 уровней, чтобы в достаточной мере погасить колебания уровней. Если исходный ряд очень длинный, база может составлять до 0,7 - 0,8 его длины. Для устранения влияния долго-периодических (циклических) колебаний на параметры тренда, число сдвигов базы должно быть равно или кратно длине цикла колебаний. Тогда начало и конец базы будут последовательно «пробегать» все фазы цикла и при усреднении параметра по всем сдвигам его искажения от циклических колебаний будут взаимопогашаться. Другой способ - взять длину скользящей базы, равной длине цикла, чтобы начало базы и конец базы всегда приходились на одну и ту же фазу цикла колебаний.
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму, проводим расчет среднегодового абсолютного прироста, т. е. параметра b уравнения линейного тренда скользящим способом по 11-летним базам (см. табл. 9.7). В ней же приведен расчет данных, необходимых для последующего изучения колеблемости в параграфе 9.7. Остановимся подробнее на методике многократного выравнивания по скользящим базам. Рассчитаем параметр b по всем базам:

Таблица 9.7
Многократное скользящее выравнивание по прямой
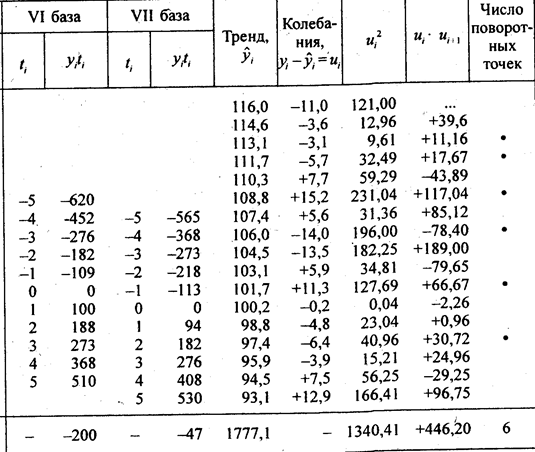

Уравнение тренда: у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г. Итак, индекс цен в среднем за год снижался на 1,433 пункта. Однократное выравнивание по всем 17 уровням может исказить этот параметр, ибо начальный уровень содержит значительное отрицательное отклонение, а конечный уровень - положительное. В самом деле, однократное выравнивание дает величину среднегодового изменения индекса всего на 0,953 пункта.
9.7. Методика изучения и показатели колеблемости
Если при изучении и измерении тенденции динамики колебания уровней играли лишь роль помех, «информационного шума», от которого следовало по возможности абстрагироваться, то в дальнейшем сама колеблемость становится предметом статистического исследования. Значение изучения колебаний уровней динамического ряда очевидно: колебания урожайности, продуктивности скота, производства мяса экономически нежелательны, так как потребность в продукции агрокомплекса постоянна. Эти колебания следует уменьшать, применяя прогрессивную технологию и другие меры. Напротив, сезонные колебания объемов производства зимней и летней обуви, одежды, мороженого, зонтиков, коньков - необходимы и закономерны, так как спрос на эти товары тоже колеблется по сезонам и равномерное производство требует лишних затрат на хранение запасов. Регулирование рыночной экономики как со стороны государства, так и производителей в значительной мере состоит в регулировании колебаний экономических процессов.
Типы колебаний статистических показателей весьма разнообразны, но все же можно выделить три основных: пилообразную или маятниковую колеблемость, циклическую долгопериодическую и случайно распределенную во времени колеблемость. Их свойства и отличия друг от друга хорошо видны при графическом изображении рис. 9.2.
Пилообразная или маятниковая колеблемость состоит в попеременных отклонениях уровней от тренда в одну и в другую сторону. Таковы автоколебания маятника. Такие автоколебания можно наблюдать в динамике урожайности при невысоком уровне агротехники: высокий урожай при благоприятных условиях погоды выносит из почвы больше питательных веществ, чем их образуется естественным путем за год; почва обедняется, что вызывает снижение следу- ющего урожая ниже тренда, он выносит меньше питательных веществ, чем образуется за год, плодородие возрастает и т.д.

Рис. 9.2. Виды колебаний
Циклическая долгопериодическая колеблемость свойственна, например, солнечной активности (10-11-летние циклы), а значит, и связанным с ней на Земле процессам - полярным сияниям, грозовой деятельности, урожайности отдельных культур в ряде районов, некоторым заболеваниям людей, растений. Для этого типа характерны редкая смена знаков отклонений от тренда и кумулятивный (накапливающийся) эффект отклонений одного знака, который может тяжело отражаться на экономике. Зато колебания хорошо прогнозируются.
Случайно распределенная во времени колеблемость - нерегулярная, хаотическая. Она может возникать при наложении (интерференции) множества колебаний с разными по длительности циклами. Но может возникать в результате столь же хаотической колеблемости главной причины существования колебаний, например суммы осадков за летний период, температуры воздуха в среднем за месяц в разные годы.
Для определения типа колебаний применяются графическое изображение, метод «поворотных точек» М. Кендэла, вычисление коэффициентов автокорреляции отклонений от тренда. Эти методы будут рассмотрены далее.
Основными показателями, характеризующими силу колеблемости уровней, выступают уже известные по главе 5 показатели, характеризующие вариацию значений признака в пространственной совокупности. Однако вариация в пространстве и колеблемость во времени принципиально различны. Прежде всего различны их основные причины. Вариация значений признака у одновременно существующих единиц возникает из-за различий в условиях существования единиц совокупности. Например, разная урожайность картофеля в совхозах области в 1990 г. вызвана различиями в плодородии почв, в качестве семян, в агротехнике. А вот суммы эффективных температур за вегетационный период и осадков не являются причинами пространственной вариации, так как в одном и том же году на территории области эти факторы почти не варьируют. Напротив, главными причинами колебания урожайности картофеля в области за ряд лет как раз являются колебания метеорологических факторов, а качество почв колебаний почти не имеет. Что же касается общего прогресса агротехники, то он является причиной тренда, но не колеблемости.
Второе коренное отличие состоит в том, что значения варьирующего признака в пространственной совокупности можно считать в основном не зависимыми друг от друга, напротив, уровни динамического ряда, как правило, являются зависимыми: это показатели развивающегося процесса, каждая стадия которого связана с предыдущими состояниями.
В-третьих, вариация в пространственной совокупности измеряется отклонениями индивидуальных значений признака от среднего значения, а колеблемость уровней динамического ряда измеряется не их отличиями от среднего уровня (эти отличия включают и тренд, и колебания), а отклонениями уровней от тренда.
Поэтому лучше использовать разные термины: различия признака в пространственной совокупности называть только вариацией, но не колебаниями: никто же не станет называть различия численности населения Москвы, Петербурга, Киева и Ташкента «колебаниями числа жителей»! Отклонения уровней динамического ряда от тренда будем называть всегда колеблемостью. Колебания всегда происходят во времени, не может существовать колебаний вне времени, в фиксированный момент.
На основе качественного содержания понятия колеблемости строится и система ее показателей. Показателями силы колебании уровней являются: амплитуда отклонений уровней отдельных периодов или моментов от тренда (по модулю), среднее абсолютное отклонение уровней от тренда (по модулю), среднее квадратическое откло;-нение уровней от тренда. Относительные меры колеблемости: относительное линейное отклонение от тренда и коэффициент колеблемости - аналог коэффициента вариации.
Особенностью методики вычисления средних отклонений от тренда является необходимость учета потерь степеней свободы колебаний на величину, равную числу параметров уравнения тренда. Например, прямая линия имеет два параметра, и, как известно из геометрии, через любые две точки можно провести прямую линию. Значит, имея лишь два уровня, мы проведем линию тренда точно через эти два уровня, и никаких отклонений уровней от тренда не окажется, хотя на самом деле и эти два уровня включали колебания, не были свободны от действия факторов колеблемости. Парабола второго порядка пройдет точно через любые три точки и т.п.
Учитывая потерю степеней свободы, основные абсолютные показатели колеблемости вычисляются по формулам (9.34) и (9.35):
среднее линейное отклонение
 (9.34)
(9.34)
среднее квадратичное отклонение
 (9.35)
(9.35)
где y i - фактический уровень;
y ̂ i - выравненный уровень, тренд;
n - число уровней;
р - число параметров тренда.
Знак времени «t » в скобках после показателя означает, что это показатель не обычной пространственной вариации, как в главе V, а показатель колеблемости во времени.
Относительные показатели колеблемости вычисляются делением абсолютных показателей на средний уровень за весь изучаемый период. Расчет показателей колеблемости проведем по результатам анализа динамики индекса цен (см. табл. 9.7). Тренд примем по результатам многократного скользящего выравнивания, т. е. у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г.
1. Амплитуда колебаний составила от -14,0 в 1986 г. до +15,2 в 1984 г., т.е. 29,2 пункта.
2. Среднее линейное отклонение по модулю найдем, сложив модули |u i | (их сумма равна 132,3), и разделив на (п - р), согласно формуле (9.34):
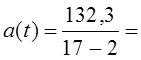 =8,82 пункта.
=8,82 пункта.
3. Среднее квадратическое отклонение уровней от тренда по формуле (9.35) составило:
 = 9,45 пункта.
= 9,45 пункта.
Небольшое превышение среднего квадратического отклонения над линейным указывает на отсутствие среди отклонений резко выделяющихся по абсолютной величине.
4. Коэффициент колеблемости:  или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
s (t ) = 14,38 ц с 1 га, v (t ) = 8,35%.
Для выявления типа колебаний воспользуемся приемом, предложенным М. Кендэлом. Он состоит в подсчете так называемых «поворотных точек» в ряду отклонений от тренда и i т. е. локальных экстремумов. Отклонение, либо большее по алгебраической величине, либо меньшее двух соседних, отмечается точкой. Обратимся к рис. 9.2. При маятниковой колеблемости все отклонения, кроме двух крайних, будут «поворотными», следовательно, их число составит п - 1. При долгопериодических циклах на цикл приходятся один минимум и один максимум, а общее число точек составит 2(n : l ), где l - длительность цикла. При случайно распределенной во времени колеблемости, как доказал М. Кендэл, число поворотных точек в среднем составит: 2/3 (n - 2). В нашем примере при маятниковой колеблемости было бы 15 точек, при связанной с 11-летним циклом было бы 2-(17: 11) ≈ 3 точки, при случайно распределенной во времени в среднем было бы (2/3)·(17-2) =10 точек.
Фактическое число точек 6 выходит за границы двукратного среднего квадратического отклонения числа поворотных точек, которое по Кендэлу равно , в нашем случае 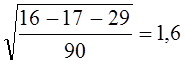 .
.
Наличие 6 точек, при 2 точках за цикл, означает, что в ряду могут быть примерно 3 цикла, продолжительность периода которых 5,5 - 6 лет. Возможно сочетание таких циклических колебаний со случайными.
Другой метод анализа типа колеблемости и поиска длины цикла основан на вычислении коэффициентов автокорреляции отклонений от тренда.
Автокорреляция - это корреляция между уровнями ряда или отклонениями от тренда, взятыми со сдвигом во времени: на 1 период (год), на 2, на 3 и т. д., поэтому говорят о коэффициентах автокорреляции разных порядков: первого, второго и т. д. Рассмотрим сначала коэффициент автокорреляции отклонений от тренда первого порядка.
Одна из основных формул для расчета коэффициента автокорреляции отклонений от тренда имеет вид:
 (9.36)
(9.36)
Как легко видеть по табл. 9.7, первое и последнее в ряду отклонения участвуют только в одном произведении в числителе, а все прочие отклонения от второго до (п - 1)-го - в двух. Поэтому и в знаменателе квадраты первого и последнего отклонений следует взять с половинным весом, как в хронологической средней. По данным табл. 9.7 имеем:

Теперь обратимся к рис. 9.2. При маятниковой колеблемости все произведения в числителе будут отрицательными величинами, и коэффициент автокорреляции первого порядка будет близок к -1. При долголериодических циклах будут преобладать положительные произведения соседних отклонений, а смена знака происходит лишь дважды за цикл. Чем длиннее Цикл, тем больше перевес положительных произведений в числителе, и коэффициент автокорреляции первого порядка ближе к +1. При случайно распределенной во времени колеблемости знаки отклонений чередуются хаотически, число положительных произведений близко к числу отрицательных, ввиду чего коэффициент автокорреляции близок к нулю. Полученное значение говорит о наличии как случайно распределенных во времени колебаний, так и циклических. Коэффициенты автокорреляции следующих порядков: II = - 0,577; Ш = -0,611; IV == -0,095; V = +0,376; VI = +0,404; VII = +0,044. Следовательно, противофаза цикла ближе всего кЗ годам (наибольший отрицательный коэффициент при сдвиге на 3 года), а совпадающие фазы ближе к б годам, что и дает длину цикла колебаний. Эти максимальные по абсолютной величине коэффициенты не близки к единице. Это означает, что циклическая колеблемость смешана со значительной случайной колеблемостью. Таким образом, подробный автокорреляционный анализ в целом дал те же результаты, что и выводы по автокорреляции первого порядка.
Если динамический ряд достаточно длинен, можно поставить и решить задачу об изменении показателей колеблемости с течением времени. Для этого рассчитывают эти показатели по подпериодам, но длительностью не менее 9-11 лет, иначе измерения колеблемости ненадежны. Кроме того, можно рассчитывать показатели колеблемости скользящим способом, а затем произвести их выравнивание, т. е. вычислить тренд показателей колеблемости. Это полезно, чтобы сделать вывод о действенности мер, применявшихся для уменьшения колебаний урожайности и других нежелательных колебаний, а также для того, чтобы по тренду сделать прогноз ожидаемых в будущем размеров колебаний.
9.8. Измерение устойчивости в динамике
Понятие «устойчивость» используется в весьма различных смыслах. По отношению к статистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивость как категория, противоположная колеблемости; 2) устойчивость направленности изменений, т. е. устойчивость тенденции.
В первом понимании показатель устойчивости, который может быть только относительным, должен изменяться от нуля до единицы (100%). Это разность между единицей и относительным показателем колеблемости. Коэффициент колеблемости составил 9,0%. Следовательно, коэффициент устойчивости равен 100% - 9,0% = 91,0%. Этот показатель характеризует близость фактических уровней к тренду и совершенно не зависит от характера последнего. Слабая колеблемость и высокая устойчивость уровней в данном смысле могут существовать даже при полном застое в развитии, когда тренд выражен горизонтальной прямой.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс их направленного изменения. Можно узнать, например, насколько устойчив процесс сокращения удельных затрат ресурсов на производство единицы продукции, является ли устойчивой тенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостью направленного изменения уровней динамического ряда следует считать такое изменение, в процессе которого каждый следующий уровень либо выше всех предшествующих (устойчивый рост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строго ранжированной последовательности уровней свидетельствует о неполной устойчивости изменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя. В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч. Спирмэна (Spearman) - r x .

где п - число уровней;
Δ i - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов) времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Это значение соответствует случаю полной устойчивости возрастания уровней. При полной противоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означает полную устойчивость процесса сокращения уровней. При хаотическом чередовании рангов уровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции. Приведем расчет коэффициента корреляции Спирмэна по данным о динамике индекса цен (табл. 9.7) в табл. 9.8.
Таблица 9.8
Расчет коэффициентов корреляции рангов Спирмена
|
Ранг лет, Р x |
Ранг уровней, Р у |
Р x -Р y |
(P x -P y ) 2 |
||
Ввиду наличия трех пар «связанных рангов» применяем формулу (8.26):
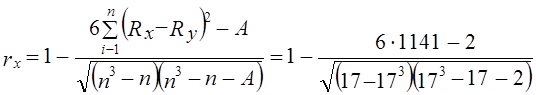
Отрицательное значение r x указывает на наличие тенденции снижения уровней, причем устойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в ряду динамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже 100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокий коэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. В целом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большая устойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
Устойчивость тенденции развития или комплексная устойчивость, в динамике может быть охарактеризована соотношением между среднегодовым абсолютным изменением и средним квадратическим (либо линейным) отклонением уровней от тренда:
Если, как нередко бывает, распределение отклонений уровней ряда от тренда близко к нормальному, то с вероятностью 0,95 отклонение от тренда вниз не превысит 1,645s (t ) по величине. Следовательно, если в ряду динамики
с > 1,64, то уровни, более низкие, чем предыдущие, в среднем будут встречаться менее 5раз за 100 периодов, или 1 раз из 20, т. е. устойчивость тренда будет высока. При с = 1 нарушения ранжированности уровней будут встречаться в среднем 16 раз из 100, а при с = 0,5 – уже 31 раз из 100, т. е. устойчивость тенденции будет низкой. Можно также пользоваться отношением среднего темпа прироста к коэффициенту колеблемости, что дает показатель, близкий к с - показателю устойчивости. Этот показатель более пригоден для экспоненциального тренда. О показателях устойчивости нелинейных трендов и об общих проблемах устойчивости экономических и социальных процессов можно подробнее прочесть в рекомендуемой к данной главе литературе .
Тренд - это закономерность описывающая подъем или падение показателя в динамике. Если изобразить любой динамический ряд (статистические данные, представляющие собой список зафиксированных значений изменяемого показателя во времени) на графике, часто выделяется определенный угол – кривая либо постепенно идет на увеличение или на уменьшение, в таких случаях принято говорить, что ряд динамики имеет тенденцию (к росту или падению соответственно).
Тренд как модель
Если же построить модель, описывающую это явление, то получается довольно простой и очень удобный инструмент для прогнозирования не требующий каких-либо сложных вычислений или временных затрат на проверку значимости или адекватности влияющих факторов.
Итак, что же собой представляет тренд как модель? Это совокупность расчетных коэффициентов уравнения, которые выражают регрессионную зависимость показателя (Y) от изменения времени (t). То есть, это точно такая же регрессия, как и те, что мы рассматривали ранее, только влияющим фактором здесь выступает именно показатель времени.
Важно!
В расчетах под t обычно подразумевается не год, номер месяца или недели, а именно порядковый номер периода в изучаемой статистической совокупности – динамическом ряде. К примеру, если динамический ряд изучается за несколько лет, а данные фиксировались ежемесячно, то использовать обнуляющуюся нумерацию месяцев, с 1 по 12 и опять сначала, в корне неверно. Также неверно в случае, если изучение ряда начинается, к примеру, с марта месяца в качестве значения t использовать 3 (третий месяц в году), если это первое значение в изучаемой совокупности, то его порядковый номер должен быть 1.
Модель линейного тренда
Как и любая другая регрессия, тренд может быть как линейным (степень влияющего фактора t равна 1) так и нелинейным (степень больше или меньше единицы). Так как линейная регрессия является самой простейшей, хотя далеко не всегда самой точной, то рассмотрим более детально именно этот тип тренда.
Общий вид уравнения линейного тренда:
Y(t) = a 0 + a 1 *t + Ɛ
Где a 0 – это нулевой коэффициент регрессии, то есть, то каким будет Y в случае, если влияющий фактор будет равен нулю, a 1 – коэффициент регрессии, который выражает степень зависимости исследуемого показателя Y от влияющего фактора t, Ɛ – случайная компонента или стандартная ошибка, по сути являет собой разницу между реально существующими значениями Y и расчетными. t – это единственный влияющий фактор – время.
Чем более выраженная тенденция роста показателя или его падения, тем будет больше коэффициент a 1 . Соответственно, предполагается, что константа a 0 совместно со случайной компонентой Ɛ отражают остальные регрессионные влияния, помимо времени, то есть всех прочих возможных влияющих факторов.
Рассчитать коэффициенты модели можно стандартным Методом наименьших квадратов (МНК). Со всеми этими расчетами Microsoft Excel справляется на ура самостоятельно, при чем, чтобы получить модель линейного тренда либо готовый прогноз существует целых пять способов, которые мы по отдельности разберем ниже.
Графический способ получения линейного тренда
В этом и во всех дальнейших примерах будем использовать один и тот же динамический ряд – уровень ВВП, который вычисляется и фиксируется ежегодно, в нашем случае исследование будет проходить на периоде с 2004-го по 2012-й гг.

Добавим к исходным данным еще один столбец, который назовем t и пометим цифрами по возрастающей порядковые номера всех зафиксированных значений ВВП за указанный период с 2004-го по 2012-й гг. – 9 лет или 9 периодов .

Эксель добавит пустое поле – разметку под будущий график, выделяем этот график и активируем появившуюся вкладку в панели меню – Конструктор , ищем кнопку Выбрать данные , в отрывшемся окне жмем кнопочку Добавить . Всплывшее окошко предложит выбрать данные для построения диаграммы. В качестве значения поля Имя ряда выбираем ячейку, которая содержит текст, наиболее полно отвечающий названию графика. В поле Значения X указываем интервал ячеек стобца t – влияющего фактора. В поле Значения Y указываем интервал ячеек столбца с известными значениями ВВП (Y) – исследуемого показателя.

Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда

Откроется окошко для настройки параметров построения линии тренда, где среди типов моделей выбираем Линейная , ставим галочки напротив пунктов Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации R2 , этого будет достаточно чтобы на графике отобразилась уже построенная линия тренда, а также математический вариант отображения модели в виде готового уравнения и показатель качества модели R 2 . Если вас интересует отображение на графике прогноза, чтобы визуально оценить отрыв исследуемого показателя укажите в поле Прогноз вперед на количество интересующих периодов.

Собственно это все, что касается этого способа, можно конечно добавить, что отображаемое уравнение линейного тренда это и есть непосредственно сама модель, которую можно использовать, в качестве формулы, чтобы получить расчетные значения по модели и соответственно точные значения прогноза (прогноз отображаемый на графике, оценить можно лишь приблизительно), что мы и сделали в приложенному к статье примере.
Построение линейного тренда с помощью формулы ЛИНЕЙН

Суть этого метода сводится к поиску коэффициентов линейного тренда с помощью функции ЛИНЕЙН , затем, подставляя эти влияющие коэффициенты в уравнение, получим прогнозную модель.
Нам потребуется выделить две рядом стоящие ячейки (на скриншоте это ячейки A38 и B38), далее в строке формул вверху (выделено красным на скриншоте выше) вызываем функцию, написав «=ЛИНЕЙН(», после чего эксель выведет подсказки того, что требуется для этой функции, а именно:
- выделяем диапазон с известными значениями описываемого показателя Y (в нашем случае ВВП, на скриншоте диапазон выделен синим) и ставим точку с запятой
- указываем диапазон влияющих факторов X (в нашем случае это показатель t, порядковый номер периодов, на скриншоте выделено зеленым) и ставим точку с запятой
- следующий по порядку требуемый параметр для функции – это определение того нужно ли рассчитывать константу, так как мы изначально рассматриваем модель с константой (коэффициент a 0 ), то ставим либо «ИСТИНА» либо «1» и точку с запятой
- далее нужно указать требуется ли расчет параметров статистики (в случае, если бы мы рассматривали этот вариант, то изначально пришлось бы выделить диапазон «под формулу» на несколько строк ниже). Указывать необходимость расчета параметров статистики, а именно стандартного значение ошибки для коэффициентов, коэффициента детерминированности, стандартной ошибки для Y, критерия Фишера, степеней свободы и пр. , есть смысл только тогда, когда вы понимаете, что они означают, в этом случае ставим либо «ИСТИНА», либо «1». В случае упрощенного моделирования, которому мы пытаемся научиться, на этом этапе прописывания формулы, ставим «ЛОЖЬ» либо «0» и добавляем после закрывающую скобочку «)»
- чтобы «оживить» формулу, то есть заставить ее работать после прописывания всех необходимых параметров, не достаточно нажать кнопку Enter, необходимо последовательно зажать три клавиши: Ctrl, Shift, Enter

Как видим на скриншоте выше, выделенные нами под формулу ячейки заполнились расчетными значениями коэффициентов регрессии для линейного тренда, в ячейке B38 находится коэффициент a 0 , а в ячейке A38 - коэффициент зависимости от параметра t (или x ), то есть a 1 . Подставляем полученные значения в уравнение линейной функции и получаем готовую модель в математическом выражении – y = 169 572,2+138 454,3*t
Чтобы получить расчетные значения Y по модели и, соответственно, чтобы получить прогноз, нужно просто подставить формулу в ячейку экселя, а вместо t указать ссылку на ячейку с требуемым номером периода (смотрите на скриншоте ячейку D25 ).
Для сравнения полученной модели с реальными данными, можно построить два графика, где в качестве Х указать порядковый номер периода, а в качестве Y в одном случае – реальный ВВП, а, в другом – расчетный (на скриншоте диаграмма справа).
Построение линейного тренда с помощью инструмента Регрессия в Пакете анализа
В статье , по сути, полностью описан этот метод, единственная же разница в том, что в наших исходных данных только один влияющий фактор Х (номер периода – t ).

Как видно на рисунке выше, диапазон данных с известными значениями ВВП выделен как входной интервал Y , а соответствующий ему диапазон с номерами периодов t – как входной интервал Х . Итоги расчетов Пакетом анализа выносятся на отдельный лист и выглядит как набор таблиц (см. рисунок ниже) на котором нас интересуют ячейки, которые были закрашены мною в желтый и зеленый цвета. По аналогии с порядком, расписанным в указанной выше статье, из полученных коэффициентов собирается модель линейного тренда y=169 572,2+138 454,3*t , на основе которой и делаются прогнозы.

Прогнозирование с помощью линейного тренда через функцию ТЕНДЕНЦИЯ
Этот метод отличается от предыдущих тем, что он пропускает необходимые ранее этапы расчета параметров модели и подстановки полученных коэффициентов вручную в качестве формулы в ячейку, чтобы получить прогноз, эта функция как раз и выдает уже готовое рассчитанное прогнозное значение на основе известных исходных данных.

В целевую ячейку (ту ячейку, где хотим видеть результат) ставим знак равно и вызываем волшебную функцию, прописав «ТЕНДЕНЦИЯ(», далее необходимо выделить , то есть , после ставим точку с запятой и выделяем диапазон с известными значениями Х, то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП, опять ставим точку с запятой и выделяем ячейку с номером периода, для которого мы делаем прогноз (правда, в нашем случае, номер периода можно указать не ссылкой на ячейку, а просто цифрой прямо в формуле), далее ставим еще одну точку с запятой и указываем ИСТИНА или 1 , в качестве подтверждения для расчета коэффициента a 0 , наконец, ставим закрывающую скобочку и нажимаем клавишу Enter .
Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.
Прогнозирование с помощью линейного тренда через функцию ПРЕДСКАЗ
Суть данной функции целиком и полностью идентична предыдущей, разница лишь в порядке прописывания исходных данных в формуле и в том, что нет настройки для наличия или отсутствия коэффициента a 0 (то есть функция подразумевает, что этот коэффициент, в любом случае, есть)

Как видно с рисунка выше, в целевую ячейку прописываем «=ПРЕДСКАЗ(» и затем указываем ячейку с номером периода , для которого необходимо просчитать значение по линейному тренду, то есть прогноз, после ставим точку с запятой, далее выделяем диапазон известных значений Y , то есть столбец с известными значениями ВВП , после ставим точку с запятой и выделяем диапазон с известными значениями Х , то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП и, наконец, ставим закрывающую скобочку и жмем клавишу Enter .
Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении.
Подводя итог к статье
Можно сказать, что каждый из методов может быть наиболее приемлемым среди прочих в зависимости от текущей цели, которую мы ставим перед собой. Первые три метода пересекаются между собой как по смыслу, так и по результату, и годятся для любой более или менее серьезной работы, где необходимо описание модели и ее качества. В свою очередь, последние два метода также идентичны между собой и максимально быстро вам дадут ответ, например, на вопрос: «Какой прогноз продаж на следующий год?».
Линейное уравнение тренда имеет вид y = at + b.
Параметры уравнений функции тренда находят с помощью теории корреляции методом наименьших квадратов.
1.Метод наименьших квадратов.
Метод наименьших квадратов МНК), является одним из способов противостоять ошибкам измерений.(Как в Физике погрешность отклонений)
Этот метод как правило используют для нахождения параметров уравнений (Линий, гипербол парабол и т.д.)
Этот способ заключается в минимизации суммы квадратов отклонений.
Смысл МНК можно выразить через вот этот график
2. Анализ точности определения оценок параметров уравнения тренда(по таблице стьюдента находим ТТабл и делаем интервальный прогноз,т.е. выявляем реднеквадратическую ошибку)
3.Проверка гипотез относительно коэффициентов линейного уравнения тренда(статистика критерий стьюдента,фишера)
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена.
Коэффициент ранговой корреляции Спирмена.
36. Методы измерения устойчивости тенденций динамики (коэффициент рангов Спирмена).
Понятие «устойчивость» используется в весьма различных смыслах. По отношению кстатистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивостькак категория, противоположная колеблемости; 2) устойчивость направленности изменений, т.е. устойчивость тенденции.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс ихнаправленного изменения. Можно узнать, например, насколько устойчив процесс сокращенияудельных затрат ресурсов на производство единицы продукции, является ли устойчивойтенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостьюнаправленного изменения уровней динамического ряда следует считать такое изменение, впроцессе которого каждый следующий уровень либо выше всех предшествующих (устойчивыйрост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строгоранжированной последовательности уровней свидетельствует о неполной устойчивостиизменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя.В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч.Спирмэна (Spearman) - rx.
где п - число уровней;
I - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов)времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Этозначение соответствует случаю полной устойчивости возрастания уровней. При полнойпротивоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означаетполную устойчивость процесса сокращения уровней. При хаотическом чередовании ранговуровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции.
Отрицательное значение rx указывает на наличие тенденции снижения уровней, причемустойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в рядудинамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокийкоэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. Вцелом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большаяустойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
37. Моделирование тенденции ряда динамики при наличии структурных изменений.
От сезонных и циклических колебаний следует отличать единовременные изменения характера тенденции временного ряда, вызванные структурными изменениями в экономике или иными факторами. В этом случае, начиная с некоторого момента времени t, происходит изменение характера динамики изучаемого показателя, что приводит к изменению параметров тренда, описывающего эту динамику.
Момент t сопровождается значительными изменениями ряда факторов, оказывающих сильное воздействие на изучаемый показатель Моделирование тенденции временного ряда при наличии структурных изменений.. Чаще всего эти изменения вызваны изменениями в общеэкономической ситуации или событиями глобального характера, приведшими к изменению структуры экономики. Если исследуемый временной ряд включает в себя соответствующий момент времени, то одной из задач его изучения становится выяснение вопроса о том, значительно ли повлияли общие структурные изменения на характер этой тенденции.
Если это влияние значимо, то для моделирования тенденции данного временного ряда следует использовать кусочно-линейные модели регрессии, т.е. разделить исходную совокупность на 2 подсовокупности (до момента времени t и после) и строить отдельно по каждой подсовокупности уравнения линейной регрессии.
Если структурные изменения незначительно повлияли на характер тенденции ряда Моделирование тенденции временного ряда при наличии структурных изменений., то ее можно писать с помощью единого для всей совокупности данных уравнения тренда.
Каждый из описанных выше подходов имеет свои положительные и отрицательные стороны. При построении кусочно-линейной модели снижается остаточная сумма квадратов по сравнению с единым для всей совокупности уравнением тренда. Но разделение совокупности на части ведет к потере числа наблюдений, и к снижению числа степеней свободы в каждом уравнении кусочно-линейной модели. Построение единого уравнения тренда позволяет сохранить число наблюдений исходной совокупности, но остаточная сумма квадратов по этому уравнению будет выше по сравнению с кусочно-линейной моделью. Очевидно, что выбор модели зависит от соотношения между снижением остаточной дисперсии и потерей числа степеней свободы при переходе от единого уравнения регрессии к кусочно-линейной модели.
38. Регрессионный анализ связных динамических рядов.
Многомерные временные ряды, показывающие зависимость результативного признака от одного или нескольких факторных, называютсвязными рядами динамики. Применение методов наименьших квадратов для обработки рядов динамики не требует выдвижения никаких предположений о законах распределения исходных данных. Однако при использовании метода наименьших квадратов для обработки связных рядов следует учитывать наличие автокорреляции (авторегрессии), которая не учитывалась при обработке одномерных рядов динамики, поскольку ее наличие способствовало более плотному и четкому выявлению тенденции развития рассматриваемого социально – экономического явления во времени.
Выявление автокорреляции в уровнях ряда динамики
В рядах динамики экономических процессов между уровнями, особенно близко расположенными, существует взаимосвязь. Ее удобно представить в виде корреляционной зависимости между рядами y1,y2,y3,…..yn h y1+h, y2+h,…, yn+h. Временное смещение L называется сдвигом,а само явление взаимосвязи – автокорреляцией.
Автокорреляционная зависимость особенно существенна между последующими и предшествующими уровнями ряда динамики.
Различают два вида автокорреляции:
Автокорреляция в наблюдениях за одной или более переменными;
Автокорреляция ошибок или автокорреляция в отклонениях от тренда.
Наличие последней приводит к искажению величин средних квадратических ошибок коэффициентов регрессии, что затрудняет построение доверительных интервалов для коэффициентов регрессии, а так же проверку их значимости.
Автокорреляцию измеряют при помощи циклического коэффициента автокорреляции, который может рассчитываться не только между соседними уровнями, т.е. сдвинутыми на один период, но и между сдвинутыми на любое число единиц времени (L). Этот сдвиг, именуемыйвременным лагом, определяет и порядок коэффициентов автокорреляции: первого порядка (при L=1), второго порядка (при L=2) и т.д. Однако наибольший интерес для исследования представляет вычисление нециклического коэффициента (первого порядка), так как наиболее сильные искажения результатов анализа возникают при корреляции между исходными уровнями ряда и теми же уровнями, сдвинутыми на одну единицу времени.
Для суждения о наличии или отсутствия автокорреляции в исследуемом ряду фактическое значение коэффициентов автокорреляции сопоставляется с табличным (критическим) для 5% - го или 1% - го уровня значимости.
Если фактическое значение коэффициента автокорреляции меньше табличного, то гипотеза об отсутствии автокорреляции в ряду может быть принята. Когда же фактическое значение больше табличного, можно сделать вывод о наличии автокорреляции в ряду динамики.
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
St =aYt +(1−α)St−1,
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
ПРИМЕР . Статистическое изучение динамики численности населения.
С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
Метод аналитического выравнивания а) Линейное уравнение тренда имеет вид y = bt + a 1. Находим параметры уравнения методом наименьших квадратов . Используем способ отсчета времени от условного начала. Система уравнений МНК для линейного тренда имеет вид: a 0 n + a 1 ∑t = ∑y a 0 ∑t + a 1 ∑t 2 = ∑y t
Для наших данных система уравнений примет вид: 10a 0 + 0a 1 = 10400 0a 0 + 330a 1 = -4038 Из первого уравнения выражаем а 0 и подставим во второе уравнение Получаем a 0 = -12.236, a 1 = 1040 Уравнение тренда: y = -12.236 t + 1040
Оценим
качество уравнения тренда с помощью
ошибки абсолютной аппроксимации.
Ошибка
аппроксимации в пределах 5%-7% свидетельствует
о хорошем подборе уравнения тренда к
исходным данным.![]()
б) выравнивание по параболе Уравнение тренда имеет вид y = at 2 + bt + c 1. Находим параметры уравнения методом наименьших квадратов. Система уравнений МНК: a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
Для наших данных система уравнений имеет вид 10a 0 + 0a 1 + 330a 2 = 10400 0a 0 + 330a 1 + 0a 2 = -4038 330a 0 + 0a 1 + 19338a 2 = 353824 Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5 Уравнение тренда: y = 1.258t 2 -12.236t+998.5
Ошибка
аппроксимации для параболического
уравнения тренда.
![]() Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный
прогноз.
Определим среднеквадратическую
ошибку прогнозируемого показателя.
![]() m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
![]() L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)
L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)