Дисперсией случайной величины называют математическое ожидание квадрата отклонения случайной величины от своего математического ожидания (если последнее существует):
D(x) = M((x-M(x)) 2).
Для дискретной случайной величины:
Если дискретная случайная величина может принимать бесконечное число значений, сумма в правой части будет представлять собой ряд.
Для чего подсчитывают дисперсию? Математическое ожидание само по себе не дает нам верного представления о характере исследуемого явления, о том, как может изменяться случайная величина. Мы узнаем только ее среднее значение при большом числе экспериментов, но не можем судить о том, каков в среднем разброс ее значений вокруг этого числа. Судить об этом позволяет дисперсия. Отклонения при ее вычислении берутся в квадрате, так как в противном случае отклонения в разные стороны (значения больше и меньше среднего) компенсировали бы друг друга. Выбор для избавления от знака именно возведения в квадрат, а не какого-либо другого действия (например, взятия по модулю) объясняется тем, что на этом факте основывается доказательство некоторых важных свойств дисперсии, изучаемых математической статистикой.
Приведенное выше выражение для дисперсии является неудобным при проведении практических вычислений, поэтому выведем другое.

Приведем без доказательства некоторые свойства дисперсии:
1) Дисперсия неотрицательна (по определению):
2) Дисперсия постоянной равна нулю:
с – const D(c) = 0
Например, если работник получает постоянную зарплату х = 30 (тыс. руб.), то ее дисперсия будет равна нулю (в самом деле, характеристика рассеяния нулевая).
3) Постоянный множитель можно выносить за знак дисперсии, возводя его в квадрат:
с – const D(cx) = c 2 D(x)
Например, пусть дисперсия заработной платы работника равна 4 (х –заработная плата, D(х) = 4). Другой работник всегда получает на 20% больше, чем первый, т.е. заработная плата второго работника равна 1,2*х. Тогда дисперсия заработной платы второго работника равна D(1,2*х) =
= 1,2 2 *D(х) = 1,44*4 = 5,76.
4) Для независимых случайных величин дисперсия их суммы равна сумме дисперсий:
D(x + y) = D(x) + D(y) (для независимых х и y)
Например, пусть дисперсия заработной платы одного работника равна 4 (х – его заработная плата, D(х) = 4), а другого – 5 (y – его заработная плата, D(y) = 5). Тогда дисперсия суммарной заработной платы составит D(x +
+ y) = D(x) + D(y) = 4 + 5 = 9. Однако, выполнить расчет таким образом можно лишь в случае, когда заработные платы этих работников не зависят друг от друга. Если они зависимы, воспользоваться формулой нельзя.
Следует отметить, что дисперсия разности двух случайных величин будет равна тоже сумме дисперсий (а не разности). Это следует из свойств (3) и (4), поскольку при возведении в квадрат сомножителя (-1) получают 1.
Свойство (4) будет верным не только для двух, но для любого конечного числа случайных величин.
5) При увеличении (уменьшении) всех значений случайной величины на константу, ее дисперсия не изменится (это следует из свойств (2) и (4):
с – const D(x - с) = D(x)
Например, если дисперсия среднемесячной зарплаты равна 4, и из зарплаты каждый месяц вычитают 800 руб. на оплату проездного билета, то дисперсия зарплаты за вычетом оплаты проездного будет все равно равна 4.
Например, рассмотрим случайную величину х – количество проданных в день автомобилей. Эта величина измерялась в течение 100 дней, и за это время принимала значения {0; 1; 2; 3; 4} соответственно 18, 15, 28, 15 и 24 число раз. Необходимо определить дисперсию вероятностного распределения х.
Будем считать, что число экспериментов – 100 - достаточно велико, чтобы можно было рассматривать относительную частоту в качестве эмпирической оценки вероятности. Поэтому чтобы определить вероятности, разделим каждую из частот на 100. Представим вероятностное распределение в виде табл.2, приписав к ней две строки для вспомогательных вычислений.
Таблица 2
6,46-2,12 2 1,97.
Использовать полученную оценку все же представляется затруднительным. Ее нельзя сравнить с математическим ожиданием, так как ее единицы измерения не имеют экономического смысла (“автомобили в квадрате”). Поэтому, чтобы определить, действительно ли разброс количества продаж вокруг величины 2,12 так велик, извлечем корень из дисперсии  . Полученный результат имеет те же единицы измерения, что и рассматриваемая случайная величина (в данном случае он измеряется в количестве автомобилей, т.е. в штуках).
. Полученный результат имеет те же единицы измерения, что и рассматриваемая случайная величина (в данном случае он измеряется в количестве автомобилей, т.е. в штуках).
Эту величину называют средним квадратическим отклонением
(СКО) и обозначают  .
.
СКО = 1,4 (шт.) – много это или мало? Вероятно, если бы объем продаж составлял в среднем, например, 10 машин в день, то такая величина характеризовала бы небольшой разброс. В рассматриваемом случае
М = 2,12 (шт.). Чтобы оценить полученный результат, необходимо подсчитать относительный показатель, который позволит сравнить СКО с математическим ожиданием.
Отношение СКО к математическому ожиданию случайной величины называют коэффициентом вариации
:  . Он представляет собой безразмерную величину (можно перевести его в проценты, умножив на 100%).
. Он представляет собой безразмерную величину (можно перевести его в проценты, умножив на 100%).
Для рассмотренного примера коэффициент вариации равен 1,4/2,12 =
= 0,66 или 66%.
Рассмотренные выше математическое ожидание, дисперсия, СКО и коэффициент вариации представляют собой числовые характеристики случайной величины. Кроме них, существуют и другие числовые характеристики, которые пока рассматривать не будем.
Дисперсия случайной величины является мерой разброса значений этой величины. Малая дисперсия означает, что значения сгруппированы близко друг к другу. Большая дисперсия свидетельствует о сильном разбросе значений. Понятие дисперсии случайной величины применяется в статистике. Например, если сравнить дисперсию значений двух величин (таких как результаты наблюдений за пациентами мужского и женского пола), можно проверить значимость некоторой переменной. Также дисперсия используется при построении статистических моделей, так как малая дисперсия может быть признаком того, что вы чрезмерно подгоняете значения.Шаги
Вычисление дисперсии выборки
-
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
- s 2 {\displaystyle s^{2}} = ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ] / (n - 1)
- s 2 {\displaystyle s^{2}} – это дисперсия. Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в выборке.
- x i {\displaystyle x_{i}} нужно вычесть x̅, возвести в квадрат, а затем сложить полученные результаты.
- x̅ – выборочное среднее (среднее значение выборки).
- n – количество значений в выборке.
-
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
- В нашем примере:
x 1 {\displaystyle x_{1}} - x̅ = 17 - 14 = 3
x 2 {\displaystyle x_{2}} - x̅ = 15 - 14 = 1
x 3 {\displaystyle x_{3}} - x̅ = 23 - 14 = 9
x 4 {\displaystyle x_{4}} - x̅ = 7 - 14 = -7
x 5 {\displaystyle x_{5}} - x̅ = 9 - 14 = -5
x 6 {\displaystyle x_{6}} - x̅ = 13 - 14 = -1 - Правильность полученных результатов легко проверить, так как их сумма должна равняться нулю. Это связано с определением среднего значения, так как отрицательные значения (расстояния от среднего значения до меньших значений) полностью компенсируются положительными значениями (расстояниями от среднего значения до больших значений).
- В нашем примере:
-
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
- В нашем примере:
( x 1 {\displaystyle x_{1}} - x̅) 2 = 3 2 = 9 {\displaystyle ^{2}=3^{2}=9}
(x 2 {\displaystyle (x_{2}} - x̅) 2 = 1 2 = 1 {\displaystyle ^{2}=1^{2}=1}
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Вы нашли квадрат разности - x̅) 2 {\displaystyle ^{2}} для каждого значения в выборке.
- В нашем примере:
-
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
- В нашем примере: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = s 2 = 166 6 − 1 = {\displaystyle s^{2}={\frac {166}{6-1}}=} 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Вычисление дисперсии совокупности
-
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
x 1 = 5 {\displaystyle x_{1}=5}
x 2 = 5 {\displaystyle x_{2}=5}
x 3 = 8 {\displaystyle x_{3}=8}
x 4 = 12 {\displaystyle x_{4}=12}
x 5 = 15 {\displaystyle x_{5}=15}
x 6 = 18 {\displaystyle x_{6}=18}
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
-
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
- σ 2 {\displaystyle ^{2}} = (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n
- σ 2 {\displaystyle ^{2}} – дисперсия совокупности (читается как «сигма в квадрате»). Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в совокупности.
- Σ – знак суммы. То есть из каждого значения x i {\displaystyle x_{i}} нужно вычесть μ, возвести в квадрат, а затем сложить полученные результаты.
- μ – среднее значение совокупности.
- n – количество значений в генеральной совокупности.
-
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = 5 + 5 + 8 + 12 + 15 + 18 6 {\displaystyle {\frac {5+5+8+12+15+18}{6}}} = 10,5
-
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере:
x 1 {\displaystyle x_{1}} - μ = 5 - 10,5 = -5,5
x 2 {\displaystyle x_{2}} - μ = 5 - 10,5 = -5,5
x 3 {\displaystyle x_{3}} - μ = 8 - 10,5 = -2,5
x 4 {\displaystyle x_{4}} - μ = 12 - 10,5 = 1,5
x 5 {\displaystyle x_{5}} - μ = 15 - 10,5 = 4,5
x 6 {\displaystyle x_{6}} - μ = 18 - 10,5 = 7,5
- В нашем примере:
-
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) 2 {\displaystyle ^{2}} = 30,25
(-5,5) 2 {\displaystyle ^{2}} , где x n {\displaystyle x_{n}} – последнее значение в генеральной совокупности. - Для вычисления среднего значения полученных результатов нужно найти их сумму и разделить ее на n:(( x 1 {\displaystyle x_{1}} - μ) 2 {\displaystyle ^{2}} + ( x 2 {\displaystyle x_{2}} - μ) 2 {\displaystyle ^{2}} + ... + ( x n {\displaystyle x_{n}} - μ) 2 {\displaystyle ^{2}} ) / n
- Теперь запишем приведенное объяснение с использованием переменных: (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n и получим формулу для вычисления дисперсии совокупности.
- В нашем примере:
Дисперсия в статистике находится как индивидуальных значений признака в квадрате от . В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. (для несгруппированных данных) вычисляется по формуле:
2. Взвешенная дисперсия (для вариационного ряда):
 где n — частота (повторяемость фактора Х)
где n — частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию
 Построим интервальную группировку. Определим размах интервала по формуле:
Построим интервальную группировку. Определим размах интервала по формуле:
![]() где X max– максимальное значение группировочного признака;
где X max– максимальное значение группировочного признака;
X min–минимальное значение группировочного признака;
n – количество интервалов:
Принимаем n=5. Шаг равен: h = (192 — 159)/ 5 = 6,6
Составим интервальную группировку
 Для дальнейших расчетов построим вспомогательную таблицу:
Для дальнейших расчетов построим вспомогательную таблицу:
 X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:
 Определим дисперсию по формуле:
Определим дисперсию по формуле:
Формулу дисперсии можно преобразовать так:
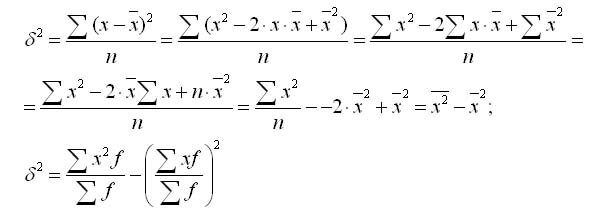
Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии , вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i - величина интервала;
А - условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
m1 — квадрат момента первого порядка;
m2 — момент второго порядка
(если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi - групповая средняя;
ni - число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную , т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Правило сложения дисперсии в статистике
Согласно правилу сложения дисперсий общая дисперсия равна сумме средней из внутригрупповых и межгрупповых дисперсий:
![]()
Смысл этого правила заключается в том, что общая дисперсия, которая возникает под влиянием всех факторов, равняется сумме дисперсий, которые возникают под влиянием всех прочих факторов, и дисперсии, возникающей за счет фактора группировки.
Пользуясь формулой сложения дисперсий, можно определить по двум известным дисперсиям третью неизвестную, а также судить о силе влияния группировочного признака.
Свойства дисперсии
1. Если все значения признака уменьшить (увеличить) на одну и ту же постоянную величину, то дисперсия от этого не изменится.
2. Если все значения признака уменьшить (увеличить) в одно и то же число раз n, то дисперсия соответственно уменьшится (увеличить) в n^2 раз.
Пусть производится п независимых испытаний, в каждом из которых вероятность появления события А постоянна. Чему равна дисперсия числа появлений события в этих испытаниях? Ответ на этот вопрос дает следующая теорема.
Теорема. Дисперсия числа появлений события А в п независимых испытаниях, в каждом из которых вероятность р появления события постоянна, равна произведению числа испытаний на вероятности появления и непоявления события в одном испытании:
D (X ) = npq.
Доказательство. Рассмотрим случайную величину X - число появлений события А в п независимых испытаниях. Очевидно, общее число появлений события в этих испытаниях равно сумме появлений события в отдельных испытаниях:
X = Х 1 + X 2 + …+ Х п,
где Х 1 - число наступлений события в первом испытании, Х 2 - во втором, ..., Х п - в п- м.
Величины Х 1 , Х 2 , ..., Х п взаимно независимы, так как исход каждого испытания не зависит от исходов остальных, поэтому мы вправе воспользоваться следствием 1 (см. § 5):
D (X ) = D (X 1) + D (X 2)+ ...+D (Х п ). (*)
Вычислим дисперсию X 1 по формуле
D (X 1)=M ( )- [M (X 1)] 2 . (**)
Величина Х 1 -число появлений события А в первом испытании, поэтому (см. гл. VII, § 2, пример 2) М (Х 1)=р .
Найдем математическое ожидание величины , которая может принимать только два значения, а именно: 1 2 c вероятностью р и О 2 с вероятностью q:
M ( )= 1 2 *p+ 0 2 *q=p.
Подставляя найденные результаты в соотношение (**), имеем
D (X 1)=p-p 2 =p (1-p )=pq
Очевидно, дисперсия каждой из остальных случайных величин также равна pq. Заменив каждое слагаемое правой части (*) через pq, окончательно получим
D (X ) = npq.
Замечание. Так как величина X распределена по биномиальному закону, то доказанную теорему можно сформулировать и так: дисперсия биномиального распределения с параметрами п и р равна произведению npq.
Пример. Производятся 10 независимых испытаний, в каждом из которых вероятность появления события равна 0,6. Найти дисперсию случайной величины X -числа появлений события в этих испытаниях.
Решение. По условию, n =10, р = 0,6. Очевидно, вероятность непоявления события
q = 1- 0, 6 = 0, 4.
Искомая дисперсия
D (X ) = npq = 10 0, 6 0, 4 = 2, 4.
Среднее квадратическое отклонение
Для оценки рассеяния возможных значений случайной величины вокруг ее среднего значения кроме дисперсии служат и некоторые другие характеристики. К их числу относится среднее квадратическое отклонение.
Средним квадратическим отклонением случайной величины X называют квадратный корень из дисперсии:
Легко показать, что дисперсия имеет размерность, равную квадрату размерности случайной величины. Так как среднее квадратическое отклонение равно квадратному корню из дисперсии, то размерность s(X )совпадает сразмерностью X. Поэтому в тех случаях, когда желательно, чтобы оценка рассеяния имела размерность случайной величины, вычисляют среднее квадратическое отклонение, а не дисперсию. Например, если X выражается влинейных метрах, то а (X )будет выражаться также влинейных метрах, a D (X )- в квадратных метрах.
Пример. Случайная величина X задана законом распределения
| X | |||
| p | 0, 1 | 0, 4 | 0, 5 |
Найти среднее квадратическое отклонение s(X ).
Решение. Найдем математическое ожидание X:
М (Х ) = 2* 0, 1 + 3* 0, 4+ 10* 0, 5 = 6, 4.
Найдем математическое ожидание X 2 :
М (Х 2) = 2 2 * 0, 1+ 3 2 * 0, 4+ 10 2 * 0, 5 = 54.
Найдем дисперсию:
D (X )= М (X 2) - [М (X )] 2 = 54 - 6, 4 2 = 13, 04.
Искомое среднее квадратическое отклонение
s(X)= =
Среднее квадратическое отклонение суммы взаимно независимых случайных величин
Пусть известны средние квадратические отклонения нескольких взаимно независимых случайных величин. Как найти среднее квадратическое отклонение суммы этих величин? Ответ на этот вопрос дает следующая теорема.
Это разность математического ожидания квадрата случайной величины и квадрата ее мат ожидания.
D(X)=M(X^2)-M^2(X)
Дисперсия характеризует степень рассеяния значение случайной величины относительно ее мат ожидания. Если все значения тесно сконцентрированы около ее мат ожидания и больше отклонения от мат ожид, то такая случайная величина имеет малую дисперсию, а если рассеяны и велика вероятность больших отклонений от М, то случ величина имеет большую дисперсию.
Свойства:
1.Дисперсия постоянно равна 0 D(C)=0
2.Дисперсия произведения случ величины на постоянную С равна произ десперсии случ велич Х на квадрат постоянной D(CX)=C^2D(X)
3.Если случ велич X and Y независимы, дисперсия их суммы (разности) равна сумме дисперсий
D(X Y)=D(X)+D(Y)
4.Дисперсия случ велич не изменится если к ней прибавить постоянную
Теорема:
Дисперсия числа появление соб А в n независимых испытаниях в каждом из которых вероятность появления соб постоянна и равна p, равна произведению числа испытания на вероятность появления и вероятности непоявления соб в одном испытании
Среднее квадратичское отклонение.
Средним квадрат отклонением случайной величины Х называется арифметический корень из дисперсия
Непрерывные случайные величины. Функция распределения вероятностей и ее свойства.
Случайная величина, значение которой заполняет некоторый промежуток, называется непрерывной .
Промежутки могут быть конечными, полубесконечными или бесконечными.
Функция распред св.
Способы задания ДСВ неприменимы для непрерывной. В этой связи вводиться понятие функции распределение вероятностей.
Функция распределения называют функцию F(x) определяющую для каждого значения х вероятность того что случ велич Х примет значение меньшее х т.е
Функция распределения ДСВ принимающие значение (x1,x2,x3) с вероятностью (p1,p2,p3) определяется
Так, например функция распределения биномиального распределения определяется формулой: ![]()
Случайную величину называют непрерывной, если ее функция распределения есть непрерывная, частично-дифференцируемая функция с непрерывной производной.
Свойства:
1.значение функции принадлежит
2. функция распределения есть неубывающая функция F(x2) 3.Вероятность того что случайная величина X примет значение заключенное в интервале (α,β) равна приращению функции распределения на этом интервале P(α Следствие. Вероятность того что случ велич примет одно значение равно 0. 4.Если все возможные значение случ велич Х принадлежит (a,b) то F(x)=0 при x a и F(x)=1 при x b 5.Вероятность того, что случ велич Х примет значение большее чем x равно разности между единицей и функцией распределения