Статистические расчеты содержания влаги
контрольная работа
2. Уравнение тренда на основе линейной зависимости.
2.1. Основные элементы временного ряда.
Можно построить эконометрическую модель, используя два типа исходных данных:
Данные, характеризующие совокупность различных объектов в определённый момент времени.
Данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными. Модели, построенные на основе второго типа данных, называются временными рядами.
Временной ряд - это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
Факторы, формирующие тенденцию ряда.
Факторы, формирующие циклические колебания ряда.
Случайные факторы.
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы.
Во-первых, большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 1. показан временной ряд, содержащий возрастающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года. При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка, а также с фазой бизнес цикла, в которой находится экономика страны. На рис. 2. представлен временной ряд, содержащий только сезонную компоненту.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень базируется как сумма среднего уровня ряда и некоторой случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведён на рис. 3.
Очевидно, что реальные данные не следуют полностью из каких-либо описанных моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью.
2.2. Автокорреляция уровней временного ряда.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией. Количественно её можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми во времени.
Одна из рабочих формул для расчёта коэффициента корреляции имеет вид:
r xy = (x j - x ) * (y j - y ) .
(x j -x) 2 * (y j -y) 2
В качестве переменной x мы рассмотрим ряд y 2 , y 3 , ... y t ; в качестве переменной y рассмотрим ряд y 1 , y 2 , ... y t -1 . Тогда данная формула примет вид:
r 1 = (y t - y 1 ) * (y t-1 - y 2 ) ; где y 1 = y t ; y 2 = y t-1 .
(y t -y 1) 2 * (y t-1 -y 2) 2 n - 1 n - 1
Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка. Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается.
Свойства коэффициента автокорреляции:
Во-первых, он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной тенденции.
Во-вторых, по знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда.
Последовательность коэффициентов автокорреляции уровней первого, второго, и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости её значений от величины лага называется коррелограммой. Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а, следовательно, и лаг, при котором связь между текущим и предыдущим уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка t, ряд содержит циклические колебания с периодичностью в t моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать вывод: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
2.3. Моделирование тенденции временного ряда.
Одним из наиболее распространённых способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Т.к. зависимость от времени может принимать разные формы, для её формализации можно использовать различные виды функции. Для построения трендов чаще всего применяются следующие функции:
Линейный тренд: y t = a + b*t ;
Гипербола:y t = a + b/t ;
Экспоненциальный тренд: y t = e a + b * t ;
Тренд в форме степенной функции: y t = a*t ;
Парабола: y t = a + b 1 *t + b 2 *t 2 + ... + b k *t k ;
Параметры каждого из этих трендов можно определить методом наименьших квадратов, используя в качестве независимой переменной время t = 1, 2, ... ,n , а в качестве зависимой переменной - фактические уровни временного ряда y t . Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
Существует несколько способов определения типа тенденции. К числу наиболее распространённых способов относятся качественный анализ изучаемого процесса, построение и визуальный анализ графика зависимости уровней ряда от времени, расчёт некоторых основных показателей динамики. В этих же целях можно использовать и коэффициенты автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляция первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Если временной ряд имеет линейную тенденцию, то его соседние уровни y t и y t -1 тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит не6линейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации R и выбора уравнения тренда с максимальным значением скорректированного коэффициента детерминации.
Высокие значения коэффициентов автокорреляции первого, второго и третьего порядков свидетельствуют о том, что ряд содержит тенденцию. Приблизительно равные значения коэффициентов автокорреляции по уровням этого ряда и по логарифмам уровней позволяют сделать следующий вывод: если ряд содержит нелинейную тенденцию, то она выражена в неявной форме. Поэтому для моделирования его тенденции в равной мере целесообразно использовать и линейную, и нелинейную функции, например степенной или экспоненциальный тренд. Для выявления наилучшего уравнения тренда необходимо определить параметры основных видов трендов.
Наиболее простую экономическую интерпретацию имеют параметры линейного и экспоненциального трендов. Параметры линейного тренда:
a - начальный уровень временного ряда в момент времени t = 0;
b - средний за период абсолютный прирост уровней ряда.
Расчётные по линейному тренду значения уровней временного ряда определяются двумя способами. Во-первых, можно последовательно подставлять в найденное уравнение тренда значения t = 1, 2, ..., n. Во-вторых, в соответствии с интерпретацией параметров линейного тренда каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста.
Задача №1
Десять человек различного возраста имеют следующие параметры:
1. Определить результативный признак.
Рассчитаем зависимость роста от возраста:
Фактор (X): возраст.
Результативный признак (Y): рост.
a*x + b*x 2 = x*y
10*a + 248*b = 1812
248*a + 6492*b = 45023
a = 1812 - 248*b => 1812 - 248*b *248 + 6492*b = 45023
r = x*y - ( x* y)/n = 45023 - (248*1812)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(328444 - 1812 2 /10)
r = 0.44 - прямая умеренная связь
r 2 = 0.19 - рост на 19% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.19 * (10 - 2) = 1.78
F табл = 5.32
F cp < F табл =>
Рассчитаем зависимость веса от возраста:
Фактор (X): возраст.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 248*b = 753
248*a + 6492*b = 18856
a = 753 - 248*b => 1812 - 248*b *248 + 6492*b = 18856
r = x*y - ( x* y)/n = 18856 - (248*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(56967 - 753 2 /10)
r = 0.6 - заметная прямая связь
r 2 = 0.36 - вес на 36% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.36 * (10 - 2) = 4.5
F табл = 5.32
F cp < F табл => нулевая гипотеза подтвердилась, уравнение статистически незначимо.
Рассчитаем зависимость веса от роста:
Фактор (X): рост.
Результативный признак (Y): вес.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 1812*b = 753
1812*a + 328444*b = 136562
a = 753 - 1812*b => 753 - 1812*b *1812 + 328444*b = 136562
r = x*y - ( x* y)/n = 136562 - (1812*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (328444 - 1812 2 /10)*(56967 - 753 2 /10)
r = 0.69 - заметная прямая связь
r 2 = 0.47 - вес на 47% зависит от роста
x = 1812/10 = 181.2
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.47 * (10 - 2) = 7.1
F табл = 5.32
F cp > F табл => нулевая гипотеза не подтвердилась, уравнение имеет экономический смысл.
Тест Стьюдента:
Рассчитаем случайные ошибки:
.
m a = (y - y x ) 2 * x 2 .
n - 2 n*(x -x) 2
m b = (y - y x ) 2 / (n - 2)
m r = 1 - r 2
m a = 138.19 * 328444 = 72
m b = 138.19 / (10 - 2) = 1
m r = 1 - 0.47 = 0.26
t a = a/m a = 120/72 = 1.67
t b = b/m b = 1.08/1 = 1.08
t r = r/m r = 0.69/0.26 = 2.65
t табл = 2.3
Для расчёта доверительного интервала рассчитаем предельную ошибку:
a = t табл - t a = 2.3 - 1.67 = 0.63
b = t табл - t b = 2.3 - 1.08 = 1.22
r = t табл - t r = 2.3 - 2.65 = -0.35
Рассчитаем доверительные интервалы:
a = a a = -121.03 119.77
b = b b = -0.14 2.3
r = r r = 0.34 1.04
Задача №2
При контрольной выборочной проверке процента влажности почвы фермерских хозяйств региона получены следующие данные:
1. С вероятностью 0.95 и 0.99 установить предел, в котором находится средний процент содержания влаги.
2. Сделать выводы.
Генеральная средняя: x = x = 31.1 = 3.8875
Генеральная дисперсия: 2 = (x - x ) 2 = 1.8875 = 0.1261
n 8 .
Средняя квадратическая стандартная ошибка: x = 2 = 0.1261 = 0.126
Предельная ошибка выборки: x = t* x
Из таблицы значений t-критерия Стьюдента:
Для вероятности 0.95, предельная ошибка выборки:
x = 2.4469*0.126 = 0.308
Для вероятности 0.99, предельная ошибка выборки:
x = 3.7074*0.126 = 0.467
Доверительные интервалы:
Предел среднего процента содержания влаги с вероятностью 0.95:
Верхний центральный показатель некоторой линейной системы
Пусть дана система (2) и - ее решение. Рассмотрим семейство функций, Определение 5 : Функция R (t) называется верхней для системы (2), если она ограничена, измерима и осуществляет оценку, Где - норма матрицы Коши линейной системы...
Дифференциальное исчисление
Исходя из определения производной сформулируем следующее правило нахождения производной функции в точке: Чтобы вычислить производную функции f(x) в точке x0 нужно: 1) Найти f(x) - f(x0); 2) составить разностное отношение; 3) вычислить предел...
Дифференциальное исчисление
Исходя из определения производной...
Инвариантные подгруппы бипримарных групп
В заметке (1) исправлена ошибка, допущенная Бернсайдом в работе (2). А именно в (3) доказано, что группа порядка, где и - различные простые числа и, либо обладает характеристической -подгруппой порядка...
Использование современной компьютерной техники и программного обеспечения для решения прикладной задачи из инженерно-буровой практики
Зная значения коэффициентов а0, а1 и а2 можно найти значений y` по формуле, в нашем случае. Различие между экспериментальными и теоретическими данными невелико. Полученные данные позволяет нам найти зависимость, 5...
Линейная сложность циклотомических последовательностей
Пусть последовательность четвертого порядка, то есть, тогда, согласно лемме 1.1, она формируется по правилу: (2.1) Заметим, что правило (2.1) задает последовательность только тогда, когда...
Математическая модель цифрового устройства игры "Крестики-нолики" с человеком
Игровое поле игры в крестики-нолики может быть представлено в виде сетки, состоящей из строк и столбцов. Каждый элемент сетки может находиться в трех состояниях: пустое (начальное), отмечено крестиком, отмечено ноликом...
Методы отсечения
Среди совокупности п неделимых предметов, каждый i-и (i=1,2,…, п) из которых обладает по i-й характеристике показателем и полезностью найти такой набор, который позволяет максимизировать эффективность использования ресурсов величины...
Приближенное решение алгебраических и трансцендентных уравнений. Метод Ньютона
Информация о предыдущих приближениях корня используется для нахождения последующих приближений не только в методе касательных. В качестве примера другого такого метода мы приведём метод...
Статистические расчеты содержания влаги
Практические задачи: 1. Десять человек различного возраста имеют следующие параметры: Возраст, лет 18 20 21 22 22 24 25 26 31 39 Рост, см 174 183 182 180 178 179 185 185 184 182 Вес, кг 65 73 69 74 77 75 78 84 79 79 1...
При использовании полиномов разных степеней оценка параметров уравнения тренда производится методом наименьших квадратов (МНК) точно так же, как оценки параметров уравнения регрессии на основе пространственных данных. В качестве зависимой переменной рассматриваются уровни динамического ряда, а в качестве независимой переменной – фактор времени t, который обычно выражается рядом натуральных чисел 1, 2, ..., п.
Оценка параметров нелинейных функций проводится МНК после линеаризации, т.е. приведения их к линейному виду. Рассмотрим применение МНК для некоторых нелинейных функций, которые не излагались подробно в главе, посвященной регрессии.
Для оценки параметров показательной кривой у = ab 1 или экспоненты у = е а+ы (либо у = ае ы) путем логарифмирования функции приводятся к линейному виду lny = ln a + t ln b или экспоненты: lny = a + bt. Далее строится система нормальных уравнений
Пример 5.1
Число зарегистрированных ДТП (на 100 000 человек населения) по Новгородской области за 2000–2008 гг. характеризуется данными:
Исходя из графика была выбрана показательная кривая / Для построения системы нормальных уравнений были рассчитаны вспомогательные величины

Система нормальных уравнений составила ![]()
Решая ее, получим значения
![]()
Соответственно имеем экспоненту или показательную кривую
За период с 2000 по 2008 г. число дорожно-транспортных происшествий возрастало в среднем ежегодно на 13,5%. Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9202. Следовательно, данный тренд объясняет 92% колеблемости уровней ряда и лишь 8% ее связаны со случайными факторами.
Некоторую специфику имеет оценка параметров кривых с насыщением: модификационной экспоненты, логистической кривой, кривой Гомперца, гиперболы вида По этим функциям должна быть сначала определена асимптота. Если она может быть задана исследователем на основе анализа временного ряда, то другие параметры могут быть оценены по МНК. В этих случаях данные функции приводятся к линейному виду. Рассмотрим оценку параметров этих кривых на отдельных примерах, начиная с модифицированной экспоненты.
Пример 5.2
Уровень механизации труда (в %) характеризуется динамическим рядом (табл. 5.2)
Таблица 5.2. Расчет параметров модифицированной экспоненты у = с ab" t
|
У = с-у |
|||||||
Так как уровень механизации труда не может превышать 100%, то имеется объективно заданная верхняя асимптота с = 100. Для оценки параметров а и b приведем рассматриваемую функцию к линейному виду ; обозначим (с-у) через Y и прологарифмируем:
![]()
Для нашего примера, исходя из данных итоговой строки табл. 3, имеем систему уравнений
![]()
Решив ее, получим ln а = 3,06311; ln b = -0,19744. Соответственно потенцируя, получим: т.е. уравнение .
Если перейти от Y к исходным уровням ряда, уравнение модифицированной экспоненты составит , где параметр показывает средний коэффициент снижения уровня использования ручного труда за 1998–2005 гг. Расчетные значения у, т.е. могут быть найдены путем подстановки в уравнение 0,8208" соответствующих значений t. Либо на основе уравнения In 7= 3,06311 – 0,19744 г при компьютерной обработке определяется In У и далее 100 – е 1пу. Так, при t = 8 In Y = = 1,48363 и 100 – e1"48363 = 100 – 4,40892 = 95,59108 = 95,6 (см. последнюю графу таблицы). Ввиду некоторой смещенности оценок (так как МНК применяется к логарифмам) Ху, Ф Ху, хотя в примере эти величины достаточно близки друг другу.
Если асимптота с не задана, то оценка параметров модифицированной экспоненты усложняется. В этих случаях могут использоваться разные методы оценивания: метод трех сумм, метод трех точек , с помощью регрессии , метод Брианта . Рассмотрим применение метода регрессии для оценки параметров модифицированной экспоненты вида у = с – ab c.
Пример 5.3
В таблице представлены данные о расходах предприятия на рекламу за 10 мес. года.
Таблица 5.3. Данные о расходах предприятия на рекламу за 10 мес. года (в тыс. руб.)
Найдем по нашему ряду цепные абсолютные приростыг и представим их через параметры нашей функции, T.e.z = c-ab" – с + ab"~ l = ab" 1 (1 – b). Известно, что для модифицированной экспоненты логарифм абсолютных приростов линейно зависит от фактора времени t. Следовательно, можно записать, что lnz = Ιηα + (f – 1) lnb + ln(l – b). Обозначим Ιηα + ln(l – b) через d. Тогда lnz = d + (t- 1) lnb, т.е. линейное в логарифмах уравнение. Применяя МНК, получим оценки параметров d, lnb, а соответственно и параметра Ь. В рассматриваемом примере на основании граф табл. 5.3 lnz и (t – 1) было найдено уравнение регрессии: lnz = 4,519641 – 0,20882 (t – 1). Исходя из него получаем lnb = -0,20882; b = 0,811538. 4,519641 = In a + In (1 – b) = In [α (1 – b)]. Тогда α (1 – b) = e4,519641, откуда параметра =91,80264/(1-0,811538) = 487,1145.
Далее можно найти оценку параметра с как среднее значение из величин с = у + ab", найденных для каждого месяца (см. последнюю графу табл. 5.3). Предельная величина расходов на рекламу составит 516,4 тыс. руб. Искомое уравнение тренда примет вид
Рассмотренный метод применим, если абсолютные приросты – величины положительные. Если же некоторые приросты окажутся меньше нуля, то нужно проводить сглаживание уровней временного ряда методом скользящей средней.
Для логистической кривой Перла – Рида аналогично параметры а и b могут быть найдены МНК, если асимптота с задана. Тогда данная функция преобразовывается в линейную из логарифмов ![]() обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
Для логистической кривой вида параметры а и b могут быть оценены МНК, если асимптота с задана, так как в этом случае функция линеаризуема: ; обозначим через Y величину и прологарифмируем: Далее, применяя МНК, оцениваем параметры а и b.
При практических расчетах значение верхней асимптоты логистической кривой может быть определено исходя из существа развития явления, различного рода ограничений для его роста (нормативы потребления, законодательные акты), а также графически.
Если верхняя асимптота не задана, то для оценки параметров могут использоваться разные методы: Фишера, Юла, Родса, Нейра и др. Сравнительная оценка и обзор этих методов изложены в работе E. М. Четыркина .
Покажем на примере расчет параметров логистической кривой по методу Фишера.
Пример 5.4
Производство продукции характеризуется данными, представленными в табл. 5.4.
Таблица 5.4. Расчет параметров логистической кривой
Метод Фишера основан на определении производной для логистической кривой. Дифференцируя данную функцию по t, получим уравнение
Обозначим темп прироста логистической кривой через . Тогда , т.е. для z,
имеем линейную функцию с параметрами а
и . Чтобы найти решение, необходимо оценить z,. Предполагая, что интервалы между уровнями в ряду динамики равны, Фишер предложил приближенно оценивать в виде уравнения , где п
- 1. Для нашего примера значения z, представлены в графе 3 табл. 5.4. Далее применяем МНК к уравнению: , т.е. строим регрессию z(оту(, беря данные от t = 2 до f = 8. Уравнение регрессии запишется в виде Исходя из него находим параметры а и с для логистической кривой. Параметр а =
0,806. Данное уравнение статистически значимо: F-критерий равен 689,6; R
2 = 0,996. Соответственно для него значимы и параметры: f-критерий для параметра а
равен 47,2 и для параметра – равен -26,2. Так как , то и ![]() т.е. верхняя асимптота производства продукции составляет 403 ед.
т.е. верхняя асимптота производства продукции составляет 403 ед.
После того, как найдены параметры а и с, находим параметр b . Для этого функциюпредставим как Обозначим через Y выражение в левой части равенства, т.е..-Тогда имеем уравнение Прологарифмируем его:. В этом уравнении свободным членом является In Ь. Его можно определить из первого уравнения системы нормальных уравнений, а именно Для нашего примера имеем уравнение . Соответственно Таким образом, логистическая кривая запишется в виде
![]()
Теоретические значения данной функции представлены в графе 6 табл. 5.4 (найдены путем подстановки соответствующих значений t). Они достаточно близко подходят к исходным данным: коэффициент корреляции между ними равен 0,999; ввиду того, что в расчетах использовались логарифмы. Если предположить, что предельное значение объема производства продукции равно 400 ед., т.е. применить МНК к уравнению , то получим и b = =67,5; параметр а при компьютерной обработке определяется как -а = -0,8. Соответственно уравнение тренда запишется в виде . Результаты двух уравнений достаточно близки.
Параметры кривой Гомперца также могут быть оценены МНК, если асимптота с задана, так как в этом случае данная функция сводима к линейному виду Прологарифмировав ее, получим уравнение .
Вторично прологарифмировав, получим уравнение ![]() , Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
, Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
При практическом применении кривой Гомперца могут возникнуть некоторые сложности по динамическому ряду с повышающейся тенденцией. В этом случае задается верхняя асимптота с и логарифмы При повторном логарифмировании в расчетах используются лишь положительные значения Продемонстрируем возможность оценки параметров кривой Гомперца с верхней асимптотой на примере динамики по предприятию товарных запасов на начало каждого месяца (тыс. долл.).
Таблица 5.5. Расчет параметров кривой Гомперца
Является тренд . Одним из наиболее популярных способов моделирования тенденции временного ряда является нахождение аналитической функции, характеризующей зависимость уровней ряда от времени. Этот способ называется аналитическим выравниванием временного ряда.
Зависимость показателя от времени может принимать разные формы, поэтому находят различные функции: линейную, гиперболу, экспоненту, степенную функцию, полиномы различных степеней. Временной ряд исследуют аналогично линейной регрессии.
Параметры любого тренда можно определить обычным методом наименьших квадратов, используя в качестве фактора время t = 1, 2,…, n, а в качестве зависимой переменной используют уровни временного ряда. Для нелинейных трендов сначала проводят процедуру линеаризации.
К числу наиболее распространенных способов определения типа тенденции относят качественный анализ изучаемого ряда , построение и анализ графика зависимости уровней ряда от времени, расчет основных показателей динамики. В этих же целях можно часто используют и .
Линейный тренд
Тип тенденции определяют путем сравнения коэффициентов автокорреляции первого порядка. Если временной ряд имеет линейный тренд, то его соседние уровни yt и yt-1 тесно коррелируют. В таком случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть максимальный. Если временной ряд содержит нелинейную тенденцию, то чем сильнее выделена нелинейная тенденция во временном ряду, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит , можно осуществить перебором основных видов тренда, расчета по каждому уравнению коэффициента корреляции и выбора уравнения тренда с максимальным значением коэффициента.
Параметры тренда
Наиболее простую интерпретацию имеют параметры экспоненциального и линейного трендов.
Параметры линейного тренда интерпретируют так: а — исходный уровень временного ряда в момент времени t = 0; b - средний за период абсолютный прирост уровней рада.
Параметры экспоненциального тренда имеют такую интерпретацию. Параметр а - это исходный уровень временного ряда в момент времени t = 0. Величина exp(b) - это средний в расчете на единицу времени коэффициент роста уровней ряда.
По аналогии с линейной моделью расчетные значения уровней рада по экспоненциальному тренду можно определить путем подстановки в уравнение тренда значений времени t = 1,2,…, n, либо в соответствии с интерпретацией параметров экспоненциального тренда: каждый последующий уровень такого ряда есть произведение предыдущего уровня на соответствующий коэффициент роста
При наличии неявной нелинейной тенденции нужно дополнять описанные выше методы выбора лучшего уравнения тренда качественным анализом динамики изучаемого показателя, для того, чтобы избежать ошибок спецификации при выборе вида тренда. Качественный анализ предполагает изучение проблем возможного наличия в исследуемом ряду поворотных точек и изменения темпов прироста, начиная с определенного момента времени под влиянием ряда факторов, и т. д. В том случае если уравнение тренда выбрано неправильно при больших значениях t, результаты прогнозирования динамики временного ряда с использованием исследуемого уравнения будут недостоверными по причине ошибки спецификации.
Иллюстрация возможного появления ошибки спецификации приведем на рисунке
Если оптимальной формой тренда является парабола, в то время как на самом деле имеет место линейная тенденция, то при больших t парабола и линейная функция естественно будут по разному описывать тенденцию в уровнях ряда.
Тренд (от англ. trend - тенденция ) - это долговременная тенденция изменения исследуемого временного ряда. Тренды могут быть описаны различными уравнениями - линейными, логарифмическими, степенными и так далее. Фактический тип тренда устанавливают на основе подбора его функциональной модели статистическими методами либо сглаживанием исходного временного ряда.
Тренд в экономике - это направление преимущественного движения показателей. Обычно рассматривается в рамках технического анализа, где подразумевают направленность движения цен или значений индексов. Чарльз Доу отмечал, что при восходящем тренде последующий пик на графике должен быть выше предыдущих, при нисходящем тренде последующие спады на графике должны быть ниже предыдущих.
|
Различают следующие их виды:
Выделяют тренды восходящий (бычий), нисходящий (медвежий) и боковой (флэт). На графике часто рисуют линию тренда, которая на восходящем тренде соединяет две или более впадины цены (линия находится под графиком, визуально его поддерживая и поддталкивая вверх), а на нисходящем тренде соединяет два или более пика цены (линия находится над графиком, визуально его ограничивая и придавливая вниз). Трендовые линии являются линиями поддержки (для восходящего тренда) и сопротивления (для нисходящего тренда). Понятия «бычий» и «медвежий» используются по аналогии с понятиями . Типы тренда
Методы оценки трендаПараметрическиеРассматривают временной ряд как гладкую функцию от t: Xt = f(t),t = 1…n;. При этом сначала выявляют один либо несколько допустимых типов функций f(t); затем различными методами (например, МНК) оценивают параметры этих функций, после чего на основе проверки критериев адекватности выбирают окончательную модель тренда. Важное значение для практических приложений имеют линеаризуемые тренды, то есть тренды, приводимые к линейному виду относительно параметров использованием тех или иных алгебраических преобразований. НепараметрическиеЭто разные методы сглаживания исходного временного ряда - скользящие средние (простая, взвешенная), экспоненциальное сглаживание. Эти методы применяются как для оценки тренда, так и для прогнозирования. Они полезны в случае, когда для оценки тренда не удается подобрать подходящую функцию. Линии трендаТрендовые линии широко используются в техническом анализе. На данный момент существует множество методов их построения и интерпретации. Линия тренда - это прямая линия, соединяющая как минимум два пика цен на графике движения курса валюты (актива). Также нужно отметить, что в пределах развития основного тренда идущего по одной линии, может формироваться множество второстепенных трендов, формирующихся по дополнительным трендовым линиям. Трендовые линии могут пробиваться ценной также как уровни поддержки и сопротивления. Показывая этим окончания текущего тренда. Существует три вида линий тренда: 1.Восходящая - строится по минимумам волн восходящего тренда и выступает в роли линии поддержки. На рисунке показана восходящая линия тренда и нижние точки, по которым она была построена 2.Нисходящая - строится по вершинам волн медвежьего тренда и выступающая в роли линии сопротивления.
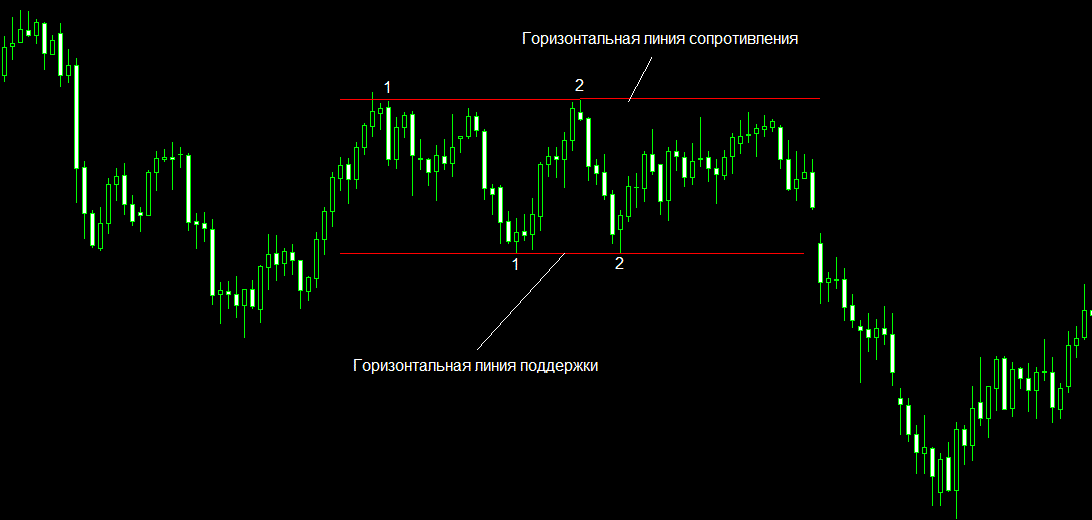
На рисунке показана нисходящая линия тренда и верхние точки, по которым она была построена 3.Горизонтальная - соединяет равные по значению максимумы или минимумы, которые зачастую поочередно меняют один одного. Такая линия рисуется при горизонтальном движении - флэте. Выступает одновременно в роли горизонтальны линий поддержки и сопротивления.
На рисунке показаны горизонтальные линии тренда и верхние/нижние точки, по которым они были построены Линии тренда классифицируются по степени важности при помощи четырех показателей:
Трендовая линия является актуальной до тех пор, пока цена не пробивает ее в противоположную текущему тренду сторону. Показывая тем самым окончание текущего тренда. |

ПРИМЕР . Статистическое изучение динамики численности населения.
С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
Метод аналитического выравнивания а) Линейное уравнение тренда имеет вид y = bt + a 1. Находим параметры уравнения методом наименьших квадратов . Используем способ отсчета времени от условного начала. Система уравнений МНК для линейного тренда имеет вид: a 0 n + a 1 ∑t = ∑y a 0 ∑t + a 1 ∑t 2 = ∑y t
Для наших данных система уравнений примет вид: 10a 0 + 0a 1 = 10400 0a 0 + 330a 1 = -4038 Из первого уравнения выражаем а 0 и подставим во второе уравнение Получаем a 0 = -12.236, a 1 = 1040 Уравнение тренда: y = -12.236 t + 1040
Оценим
качество уравнения тренда с помощью
ошибки абсолютной аппроксимации.
Ошибка
аппроксимации в пределах 5%-7% свидетельствует
о хорошем подборе уравнения тренда к
исходным данным.![]()
б) выравнивание по параболе Уравнение тренда имеет вид y = at 2 + bt + c 1. Находим параметры уравнения методом наименьших квадратов. Система уравнений МНК: a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
Для наших данных система уравнений имеет вид 10a 0 + 0a 1 + 330a 2 = 10400 0a 0 + 330a 1 + 0a 2 = -4038 330a 0 + 0a 1 + 19338a 2 = 353824 Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5 Уравнение тренда: y = 1.258t 2 -12.236t+998.5
Ошибка
аппроксимации для параболического
уравнения тренда.
![]() Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный
прогноз.
Определим среднеквадратическую
ошибку прогнозируемого показателя.
![]() m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
![]() L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)
L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)