Po wyrównaniu otrzymujemy funkcję w postaci: g (x) = x + 1 3 + 1 .
Możemy przybliżyć te dane za pomocą zależności liniowej y = a x + b, obliczając odpowiednie parametry. W tym celu będziemy musieli zastosować tzw. metodę najmniejszych kwadratów. Będziesz także musiał wykonać rysunek, aby sprawdzić, która linia najlepiej pasuje do danych eksperymentalnych.
Yandex.RTB R-A-339285-1
Czym dokładnie jest OLS (metoda najmniejszych kwadratów)
Najważniejsze, co musimy zrobić, to znaleźć takie współczynniki zależności liniowej, przy których wartość funkcji dwóch zmiennych F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 będzie równa najmniejszy. Inaczej mówiąc, dla pewnych wartości a i b suma kwadratów odchyleń prezentowanych danych od wynikowej prostej będzie miała wartość minimalną. Takie jest znaczenie metody najmniejszych kwadratów. Aby rozwiązać przykład, wystarczy znaleźć ekstremum funkcji dwóch zmiennych.
Jak wyprowadzać wzory na obliczanie współczynników
Aby wyprowadzić wzory na obliczanie współczynników, należy utworzyć i rozwiązać układ równań z dwiema zmiennymi. W tym celu obliczamy pochodne cząstkowe wyrażenia F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 względem aib i przyrównujemy je do 0.
δ fa (a, b) δ za = 0 δ fa (a, b) δ b = 0 ⇔ - 2 ∑ ja = 1 n (y ja - (a x ja + b)) x ja = 0 - 2 ∑ ja = 1 n ( y ja - (a x ja + b)) = 0 ⇔ za ∑ ja = 1 n x ja 2 + b ∑ ja = 1 n x ja = ∑ ja = 1 n x ja y ja za ∑ ja = 1 n x ja + ∑ ja = 1 n b = ∑ ja = 1 n y ja ⇔ a ∑ ja = 1 n x ja 2 + b ∑ ja = 1 n x ja = ∑ ja = 1 n x ja y ja za ∑ ja = 1 n x ja + n b = ∑ ja = 1 n y ja
Aby rozwiązać układ równań, można zastosować dowolne metody, na przykład podstawienie lub metodę Cramera. W rezultacie powinniśmy mieć wzory, które można wykorzystać do obliczenia współczynników metodą najmniejszych kwadratów.
n ∑ ja = 1 n x ja y ja - ∑ ja = 1 n x ja ∑ ja = 1 n y ja n ∑ ja = 1 n - ∑ ja = 1 n x ja 2 b = ∑ ja = 1 n y ja - za ∑ ja = 1 n x ja n
Obliczyliśmy wartości zmiennych, przy których działa funkcja
F (a , b) = ∑ i = 1 n (y i - (a x ja + b)) 2 przyjmie wartość minimalną. W trzecim akapicie udowodnimy, dlaczego jest właśnie tak.
Jest to zastosowanie w praktyce metody najmniejszych kwadratów. Jego wzór, za pomocą którego znajduje się parametr a, zawiera ∑ i = 1 n x i, ∑ i = 1 n y i, ∑ i = 1 n x i y i, ∑ i = 1 n x i 2 oraz parametr
n – oznacza ilość danych doświadczalnych. Radzimy obliczyć każdą kwotę osobno. Wartość współczynnika b oblicza się bezpośrednio po a.
Wróćmy do pierwotnego przykładu.
Przykład 1
Tutaj mamy n równe pięć. Aby ułatwić obliczenie wymaganych kwot zawartych we wzorach współczynników, wypełnijmy tabelę.
| ja = 1 | ja=2 | ja=3 | ja=4 | ja=5 | ∑ ja = 1 5 | |
| x ja | 0 | 1 | 2 | 4 | 5 | 12 |
| tak, ja | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Rozwiązanie
Czwarty wiersz obejmuje dane uzyskane przez pomnożenie wartości z drugiego wiersza przez wartości trzeciego dla każdego osobnika, tj. Piąta linia zawiera dane z drugiej, podniesione do kwadratu. Ostatnia kolumna pokazuje sumy wartości poszczególnych wierszy.
Użyjmy metody najmniejszych kwadratów do obliczenia potrzebnych współczynników a i b. Aby to zrobić, podstaw wymagane wartości z ostatniej kolumny i oblicz kwoty:
n ∑ ja = 1 n x ja y ja - ∑ ja = 1 n x ja ∑ ja = 1 n y ja n ∑ ja = 1 n - ∑ ja = 1 n x ja 2 b = ∑ ja = 1 n y ja - za ∑ ja = 1 n x ja n ⇒ za = 5 33, 8 - 12 12, 9 5 46 - 12 2 b = 12, 9 - za 12 5 ⇒ za ≈ 0, 165 b ≈ 2, 184
Okazuje się, że wymagana aproksymująca linia prosta będzie wyglądać jak y = 0, 165 x + 2, 184. Teraz musimy określić, która linia lepiej przybliży dane - g (x) = x + 1 3 + 1 lub 0, 165 x + 2, 184. Oszacujmy metodą najmniejszych kwadratów.
Aby obliczyć błąd, musimy znaleźć sumę kwadratów odchyleń danych od prostych σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 i σ 2 = ∑ i = 1 n (y i - g (x i)) 2, minimalna wartość będzie odpowiadać bardziej odpowiedniej linii.
σ 1 = ∑ ja = 1 n (y ja - (a x ja + b ja)) 2 = = ∑ ja = 1 5 (y ja - (0, 165 x ja + 2, 184)) 2 ≈ 0, 019 σ 2 = ∑ ja = 1 n (y ja - g (x ja)) 2 = = ∑ ja = 1 5 (y ja - (x ja + 1 3 + 1)) 2 ≈ 0,096
Odpowiedź: ponieważ σ 1< σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0,165 x + 2,184.
Metodę najmniejszych kwadratów wyraźnie pokazano na ilustracji graficznej. Linia czerwona oznacza linię prostą g (x) = x + 1 3 + 1, linia niebieska oznacza y = 0, 165 x + 2, 184. Oryginalne dane są oznaczone różowymi kropkami.
Wyjaśnijmy, dlaczego potrzebne są dokładnie tego typu przybliżenia.
Można je stosować w zadaniach wymagających wygładzenia danych, a także tam, gdzie dane muszą być interpolowane lub ekstrapolowane. Przykładowo w omówionym powyżej problemie można znaleźć wartość obserwowanej wielkości y przy x = 3 lub przy x = 6. Takim przykładom poświęciliśmy osobny artykuł.
Dowód metody OLS
Aby funkcja przy obliczaniu a i b przyjmowała wartość minimalną konieczne jest, aby w danym punkcie macierz postaci kwadratowej różniczki funkcji postaci F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 jest dodatnio określone. Pokażemy Ci jak to powinno wyglądać.
Przykład 2
Różniczkę drugiego rzędu mamy w postaci:
re 2 fa (a; b) = δ 2 fa (a; b) δ za 2 re 2 a + 2 δ 2 fa (a; b) δ a δ b re za re b + δ 2 fa (a; b) δ b 2 d 2 b
Rozwiązanie
δ 2 fa (a ; b) δ za 2 = δ δ fa (a ; b) δ za δ a = = δ - 2 ∑ ja = 1 n (y ja - (a x ja + b)) x ja δ a = 2 ∑ ja = 1 n (x i) 2 δ 2 fa (a; b) δ a δ b = δ δ fa (a; b) δ a δ b = = δ - 2 ∑ ja = 1 n (y ja - (a x ja + b) ) x ja δ b = 2 ∑ ja = 1 n x ja δ 2 fa (a ; b) δ b 2 = δ δ fa (a ; b) δ b δ b = δ - 2 ∑ ja = 1 n (y ja - (a x ja + b)) δ b = 2 ∑ ja = 1 n (1) = 2 n
Innymi słowy, możemy to zapisać w ten sposób: d 2 F (a ; b) = 2 ∑ i = 1 n (x i) 2 d 2 a + 2 2 ∑ x i i = 1 n re a re b + (2 n) d 2 b.
Otrzymaliśmy macierz postaci kwadratowej M = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x ja 2 ∑ i = 1 n x ja 2 n .
W takim przypadku wartości poszczególnych elementów nie ulegną zmianie w zależności od aib. Czy ta macierz jest dodatnio określona? Aby odpowiedzieć na to pytanie, sprawdźmy, czy jego drobne kątowe są dodatnie.
Obliczamy moll kątowy pierwszego rzędu: 2 ∑ i = 1 n (x i) 2 > 0 . Ponieważ punkty x i nie pokrywają się, nierówność jest ścisła. Będziemy o tym pamiętać w dalszych obliczeniach.
Obliczamy moll kątowy drugiego rzędu:
re mi t (M) = 2 ∑ ja = 1 n (x ja) 2 2 ∑ ja = 1 n x ja 2 ∑ ja = 1 n x ja 2 n = 4 n ∑ ja = 1 n (x ja) 2 - ∑ ja = 1 n x ja 2
Następnie przystępujemy do udowodnienia nierówności n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 za pomocą indukcji matematycznej.
- Sprawdźmy, czy ta nierówność jest prawdziwa dla dowolnego n. Weźmy 2 i obliczmy:
2 ∑ ja = 1 2 (x ja) 2 - ∑ ja = 1 2 x ja 2 = 2 x 1 2 + x 2 2 - x 1 + x 2 2 = = x 1 2 - 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
Otrzymaliśmy poprawną równość (jeśli wartości x 1 i x 2 nie pokrywają się).
- Załóżmy, że nierówność ta będzie prawdziwa dla n, tj. n ∑ ja = 1 n (x i) 2 - ∑ ja = 1 n x ja 2 > 0 – prawda.
- Teraz udowodnimy ważność dla n + 1, tj. że (n + 1) ∑ ja = 1 n + 1 (x i) 2 - ∑ ja = 1 n + 1 x ja 2 > 0, jeśli n ∑ ja = 1 n (x i) 2 - ∑ ja = 1 n x ja 2 > 0 .
Obliczamy:
(n + 1) ∑ ja = 1 n + 1 (x i) 2 - ∑ ja = 1 n + 1 x ja 2 = = (n + 1) ∑ ja = 1 n (x i) 2 + x n + 1 2 - ∑ ja = 1 n x ja + x n + 1 2 = = n ∑ ja = 1 n (x ja) 2 + n x n + 1 2 + ∑ ja = 1 n (x ja) 2 + x n + 1 2 - - ∑ ja = 1 n x ja 2 + 2 x n + 1 ∑ ja = 1 n x ja + x n + 1 2 = = ∑ ja = 1 n (x ja) 2 - ∑ ja = 1 n x ja 2 + n x n + 1 2 - x n + 1 ∑ ja = 1 n x ja + ∑ ja = 1 n (x ja) 2 = = ∑ ja = 1 n (x i) 2 - ∑ ja = 1 n x ja 2 + x n + 1 2 - 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 - 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 - 2 x n + 1 x 1 + x n 2 = = n ∑ ja = 1 n (x ja) 2 - ∑ ja = 1 n x ja 2 + + (x n + 1 - x 1) 2 + (x n + 1 - x 2) 2 + . . . + (x n - 1 - x n) 2 > 0
Wyrażenie ujęte w nawiasy klamrowe będzie większe od 0 (w oparciu o to, co założyliśmy w kroku 2), a pozostałe wyrazy będą większe od 0, ponieważ wszystkie są kwadratami liczb. Udowodniliśmy nierówność.
Odpowiedź: znalezione a i b będą odpowiadać najmniejszej wartości funkcji F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2, co oznacza, że są to wymagane parametry metody najmniejszych kwadratów (LSM).
Jeśli zauważysz błąd w tekście, zaznacz go i naciśnij Ctrl+Enter
Metoda najmniejszych kwadratów wykorzystywane do estymacji parametrów równania regresji.Jedną z metod badania stochastycznych zależności między cechami jest analiza regresji.
Analiza regresji polega na wyprowadzeniu równania regresji, za pomocą którego wyznaczana jest średnia wartość zmiennej losowej (atrybut wyniku), jeśli znana jest wartość innej (lub innych) zmiennych (atrybutów czynników). Obejmuje następujące kroki:
- wybór formy połączenia (rodzaj równania regresji analitycznej);
- estymacja parametrów równania;
- ocena jakości analitycznego równania regresji.
W przypadku liniowej zależności parami równanie regresji będzie miało postać: y i =a+b·x i +u i . Parametry aib tego równania są szacowane na podstawie danych statystycznych x i y z obserwacji. Wynikiem takiej oceny jest równanie: , gdzie , to estymaty parametrów a i b, to wartość wynikowego atrybutu (zmiennej) otrzymana z równania regresji (wartość obliczona).
Najczęściej używany do szacowania parametrów metoda najmniejszych kwadratów (LSM).
Metoda najmniejszych kwadratów zapewnia najlepsze (spójne, efektywne i bezstronne) oszacowania parametrów równania regresji. Ale tylko wtedy, gdy zostaną spełnione pewne założenia dotyczące składnika losowego (u) i zmiennej niezależnej (x) (patrz założenia OLS).
Problem estymacji parametrów równania pary liniowej metodą najmniejszych kwadratów wygląda następująco: otrzymać takie oszacowania parametrów , , przy których suma kwadratów odchyleń rzeczywistych wartości charakterystyki wypadkowej – y i od obliczonych wartości – jest minimalna.
Formalnie Test OLS można zapisać w ten sposób:  .
.
Klasyfikacja metod najmniejszych kwadratów
- Metoda najmniejszych kwadratów.
- Metoda największej wiarygodności (dla normalnego klasycznego modelu regresji liniowej postuluje się normalność reszt regresji).
- Uogólnioną metodę najmniejszych kwadratów OLS stosuje się w przypadku autokorelacji błędów oraz w przypadku heteroskedastyczności.
- Metoda ważonych najmniejszych kwadratów (szczególny przypadek OLS z resztami heteroskedastycznymi).
Zilustrujmy tę kwestię klasyczna metoda najmniejszych kwadratów w formie graficznej. W tym celu skonstruujemy wykres punktowy na podstawie danych obserwacyjnych (x i, y i, i=1;n) w prostokątnym układzie współrzędnych (taki wykres punktowy nazywany jest polem korelacji). Spróbujmy wybrać linię prostą najbliższą punktom pola korelacji. Zgodnie z metodą najmniejszych kwadratów linię dobiera się w taki sposób, aby suma kwadratów odległości pionowych pomiędzy punktami pola korelacji a tą prostą była minimalna. 
Zapis matematyczny tego problemu:  .
.
Wartości y i oraz x i =1...n są nam znane, są to dane obserwacyjne. W funkcji S reprezentują stałe. Zmienne w tej funkcji są wymaganymi oszacowaniami parametrów - , . Aby znaleźć minimum funkcji dwóch zmiennych, należy obliczyć pochodne cząstkowe tej funkcji dla każdego z parametrów i przyrównać je do zera, tj. 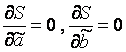 .
.
W rezultacie otrzymujemy układ 2 normalnych równań liniowych: 
Rozwiązując ten układ, znajdujemy wymagane oszacowania parametrów: 
Poprawność wyliczenia parametrów równania regresji można sprawdzić porównując wielkości (mogą wystąpić pewne rozbieżności ze względu na zaokrąglenia obliczeń).
Aby obliczyć szacunki parametrów, możesz zbudować tabelę 1.
Znak współczynnika regresji b wskazuje kierunek zależności (jeśli b > 0, zależność jest bezpośrednia, jeśli b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formalnie wartość parametru a jest średnią wartością y przy x równym zero. Jeśli współczynnik atrybutu nie ma i nie może mieć wartości zerowej, to powyższa interpretacja parametru a nie ma sensu.
Ocena bliskości związku między cechami
przeprowadzono przy użyciu współczynnika korelacji par liniowych - r x,y. Można to obliczyć korzystając ze wzoru:  . Dodatkowo współczynnik korelacji par liniowych można wyznaczyć poprzez współczynnik regresji b:
. Dodatkowo współczynnik korelacji par liniowych można wyznaczyć poprzez współczynnik regresji b:  .
.
Zakres dopuszczalnych wartości współczynnika korelacji pary liniowej wynosi od –1 do +1. Znak współczynnika korelacji wskazuje kierunek zależności. Jeżeli rx, y >0, to połączenie jest bezpośrednie; jeśli rx, y<0, то связь обратная.
Jeśli współczynnik ten jest bliski jedności, wówczas zależność między cechami można interpretować jako dość bliską liniową. Jeżeli jego moduł jest równy jeden ê r x , y ê =1, to zależność między cechami ma charakter liniowy funkcyjny. Jeżeli cechy x i y są liniowo niezależne, to r x,y jest bliskie 0.
Aby obliczyć r x, y, możesz także skorzystać z tabeli 1.
Tabela 1
| N obserwacji | x ja | tak, ja | x i ∙y i | ||
| 1 | x 1 | y 1 | x 1 y 1 | ||
| 2 | x 2 | y 2 | x 2 y 2 | ||
| ... | |||||
| N | x rz | y n | x n y n | ||
| Suma kolumny | ∑x | ∑ r | ∑xy | ||
| Średnia wartość |
|
|
 ,
,
gdzie d 2 jest wariancją y wyjaśnioną równaniem regresji;
e 2 - resztowa (niewyjaśniona równaniem regresji) wariancja y;
s 2 y - całkowita (całkowita) wariancja y.
Współczynnik determinacji charakteryzuje udział zmienności (rozproszenia) wynikowej cechy y wyjaśnionej regresją (a w konsekwencji współczynnikiem x) w całkowitej zmienności (rozproszeniu) y. Współczynnik determinacji R 2 yx przyjmuje wartości od 0 do 1. Odpowiednio wartość 1-R 2 yx charakteryzuje proporcję wariancji y spowodowaną wpływem innych czynników nieuwzględnionych w modelu i błędami specyfikacji.
W przypadku sparowanej regresji liniowej R 2 yx = r 2 yx.
Jest szeroko stosowana w ekonometrii w postaci jasnej interpretacji ekonomicznej jej parametrów.
Regresja liniowa sprowadza się do znalezienia równania postaci
Lub 
Równanie postaci  pozwala na podstawie określonych wartości parametrów X mają teoretyczne wartości wynikowej charakterystyki, zastępując w niej rzeczywiste wartości współczynnika X.
pozwala na podstawie określonych wartości parametrów X mają teoretyczne wartości wynikowej charakterystyki, zastępując w niej rzeczywiste wartości współczynnika X.
Konstrukcja regresji liniowej sprowadza się do oszacowania jej parametrów - A I V. Oszacowania parametrów regresji liniowej można znaleźć różnymi metodami.
Klasyczne podejście do szacowania parametrów regresji liniowej opiera się na metoda najmniejszych kwadratów(MNC).
Metoda najmniejszych kwadratów pozwala na otrzymanie takich estymatorów parametrów A I V, przy czym suma kwadratów odchyleń rzeczywistych wartości wynikowej charakterystyki (y) z obliczonego (teoretycznego) minimum:

Aby znaleźć minimum funkcji, należy obliczyć pochodne cząstkowe każdego z parametrów A I B i ustaw je na zero.
Oznaczmy  przez S, wówczas:
przez S, wówczas:

Przekształcając wzór, otrzymujemy następujący układ równań normalnych do szacowania parametrów A I V:

Rozwiązując układ równań normalnych (3.5) metodą sekwencyjnej eliminacji zmiennych lub metodą wyznaczników, znajdujemy wymagane oszacowania parametrów A I V.
Parametr V zwany współczynnikiem regresji. Jego wartość pokazuje średnią zmianę wyniku przy zmianie współczynnika o jedną jednostkę.
Równanie regresji jest zawsze uzupełniane wskaźnikiem bliskości połączenia. W przypadku stosowania regresji liniowej takim wskaźnikiem jest współczynnik korelacji liniowej. Istnieją różne modyfikacje wzoru na współczynnik korelacji liniowej. Niektóre z nich podano poniżej:

Jak wiadomo, współczynnik korelacji liniowej mieści się w granicach: -1 ≤ ≤ 1.
Aby ocenić jakość wyboru funkcji liniowej, oblicza się kwadrat
Liniowy współczynnik korelacji tzw współczynnik determinacji. Współczynnik determinacji charakteryzuje proporcję wariancji wynikowej cechy y, wyjaśnione przez regresję, w całkowitej wariancji wynikowej cechy:

Zatem wartość 1 charakteryzuje udział wariancji y, spowodowane wpływem innych czynników nieuwzględnionych w modelu.
Pytania do samokontroli
1. Istota metody najmniejszych kwadratów?
2. Ile zmiennych dostarcza regresja parami?
3. Jaki współczynnik decyduje o bliskości powiązania pomiędzy zmianami?
4. W jakich granicach wyznacza się współczynnik determinacji?
5. Estymacja parametru b w analizie korelacji-regresji?
1. Christopher Dougherty. Wprowadzenie do ekonometrii. - M.: INFRA - M, 2001 - 402 s.
2. SA Borodich. Ekonometria. Mińsk LLC „Nowa wiedza” 2001.
3. RU Rachmetowa Krótki kurs ekonometrii. Instruktaż. Ałmaty. 2004. -78p.
4. I.I. Eliseeva Ekonometria. - M.: „Finanse i statystyka”, 2002
5. Miesięcznik informacyjno-analityczny.
Nieliniowe modele ekonomiczne. Modele regresji nieliniowej. Transformacja zmiennych.
Nieliniowe modele ekonomiczne..
Transformacja zmiennych.
Współczynnik elastyczności.
Jeśli istnieją nieliniowe zależności między zjawiskami gospodarczymi, wówczas wyraża się je za pomocą odpowiednich funkcji nieliniowych: na przykład hiperbola równoboczna  ,
parabole drugiego stopnia
,
parabole drugiego stopnia  itd.
itd.
Istnieją dwie klasy regresji nieliniowych:
1. Regresje nieliniowe w stosunku do zmiennych objaśniających uwzględnionych w analizie, ale liniowe w stosunku do oszacowanych parametrów, np.:
Wielomiany różnych stopni - ![]() , ;
, ;
Hiperbola równoboczna - ;
Funkcja semilogarytmiczna - .
2. Regresje, które są nieliniowe w szacowanych parametrach, na przykład:
Moc - ;
Demonstracyjne - ;
Wykładniczy - .
Całkowita suma kwadratów odchyleń poszczególnych wartości wynikowej charakterystyki Na od średniej wartości jest spowodowane wpływem wielu przyczyn. Warunkowo podzielmy cały zestaw powodów na dwie grupy: badany czynnik x I inne czynniki.
Jeśli czynnik nie ma wpływu na wynik, wówczas linia regresji na wykresie jest równoległa do osi Oh I 
Wtedy cała wariancja wynikowej charakterystyki wynika z wpływu innych czynników, a całkowita suma kwadratów odchyleń będzie pokrywać się z resztą. Jeśli inne czynniki nie wpływają na wynik, to jesteś związany Z X funkcjonalnie, a reszta suma kwadratów wynosi zero. W tym przypadku suma kwadratów odchyleń wyjaśniona regresją jest taka sama, jak całkowita suma kwadratów.
Ponieważ nie wszystkie punkty pola korelacji leżą na linii regresji, ich rozproszenie zawsze następuje w wyniku wpływu czynnika X, czyli regresja Na Przez X, i spowodowane innymi przyczynami (niewyjaśniona zmienność). Przydatność linii regresji do prognozowania zależy od tego, jaka część całkowitej zmienności cechy Na wyjaśnia wyjaśnioną zmienność
Oczywiście, jeśli suma kwadratów odchyleń spowodowanych regresją jest większa niż suma kwadratów reszt, to równanie regresji jest istotne statystycznie i współczynnik X ma istotny wpływ na wynik ty
, tj. z liczbą swobody niezależnych zmian cechy. Liczba stopni swobody jest powiązana z liczbą jednostek populacji n i liczbą wyznaczonych z niej stałych. W odniesieniu do badanego problemu liczba stopni swobody powinna wskazywać, od ilu niezależnych odchyleń P
Ocenę znaczenia równania regresji jako całości podano za pomocą F-Kryterium Fishera. W tym przypadku stawia się hipotezę zerową, że współczynnik regresji jest równy zeru, tj. b = 0, a zatem współczynnik X nie ma wpływu na wynik ty
Natychmiastowe obliczenie testu F poprzedzone jest analizą wariancji. Centralne miejsce w nim zajmuje rozkład całkowitej sumy kwadratów odchyleń zmiennej Na od wartości średniej Na na dwie części – „wyjaśnioną” i „niewyjaśnioną”:
 - całkowita suma kwadratów odchyleń;
- całkowita suma kwadratów odchyleń;
 - suma kwadratów odchyleń wyjaśnionych regresją;
- suma kwadratów odchyleń wyjaśnionych regresją;
 - resztowa suma kwadratów odchyleń.
- resztowa suma kwadratów odchyleń.
Dowolna suma kwadratów odchyleń jest powiązana z liczbą stopni swobody , tj. z liczbą swobody niezależnych zmian cechy. Liczba stopni swobody jest powiązana z liczbą jednostek populacji N i z wyznaczoną na tej podstawie liczbą stałych. W odniesieniu do badanego problemu liczba stopni swobody powinna wskazywać, od ilu niezależnych odchyleń P wymagane do utworzenia danej sumy kwadratów.
Dyspersja na stopień swobodyD.
Współczynniki F (test F): 

Jeśli hipoteza zerowa jest prawdziwa, to wariancja czynnikowa i resztowa nie różnią się od siebie. W przypadku H 0 konieczne jest obalenie, aby dyspersja współczynników kilkakrotnie przekraczała dyspersję resztkową. Angielski statystyk Snedekor opracował tabele wartości krytycznych F-zależności na różnych poziomach istotności hipotezy zerowej i różnych liczbach stopni swobody. Wartość tabeli F-kryterium to maksymalna wartość stosunku wariancji, jaka może wystąpić w przypadku rozbieżności losowej dla danego poziomu prawdopodobieństwa wystąpienia hipotezy zerowej. Obliczona wartość F-relacje uważa się za wiarygodne, jeśli o jest większe niż w tabeli.
W tym przypadku hipoteza zerowa o braku związku między znakami zostaje odrzucona i wyciągany jest wniosek na temat znaczenia tego związku: Fakt F > tabela F H0 zostaje odrzucony.
Jeśli wartość jest mniejsza niż w tabeli Fakt F ‹, tabela F, to prawdopodobieństwo hipotezy zerowej jest wyższe od określonego poziomu i nie można jej odrzucić bez poważnego ryzyka wyciągnięcia błędnego wniosku o istnieniu związku. W tym przypadku równanie regresji uważa się za nieistotne statystycznie. Ale on nie odbiega.
Błąd standardowy współczynnika regresji
Aby ocenić istotność współczynnika regresji, porównuje się jego wartość z błędem standardowym, czyli wyznacza się wartość rzeczywistą T-Test studenta:  którą następnie porównuje się z wartością z tabeli na określonym poziomie istotności i liczbie stopni swobody ( N- 2).
którą następnie porównuje się z wartością z tabeli na określonym poziomie istotności i liczbie stopni swobody ( N- 2).
Standardowy błąd parametru A:

Istotność współczynnika korelacji liniowej sprawdza się na podstawie wielkości błędu Współczynnik korelacji t r:


Całkowita wariancja cechy X: 
Wielokrotna regresja liniowa
Budowa modelu
Regresja wielokrotna reprezentuje regresję efektywnej cechy z dwoma lub więcej czynnikami, tj. modelem postaci

Regresja może dać dobre wyniki w modelowaniu, jeśli pominąć wpływ innych czynników wpływających na przedmiot badań. Zachowania poszczególnych zmiennych ekonomicznych nie da się kontrolować, tzn. nie da się zapewnić równości wszystkich pozostałych warunków oceny wpływu jednego badanego czynnika. W takim przypadku należy spróbować zidentyfikować wpływ innych czynników, wprowadzając je do modelu, czyli skonstruować równanie regresji wielokrotnej: y = a+b 1 x 1 +b 2 +…+b p x p + .
Głównym celem regresji wielokrotnej jest zbudowanie modelu z dużą liczbą czynników, przy jednoczesnym określeniu wpływu każdego z nich z osobna, a także ich łącznego wpływu na modelowany wskaźnik. Specyfikacja modelu obejmuje dwa zakresy zagadnień: dobór czynników oraz wybór rodzaju równania regresji
Metoda najmniejszych kwadratów
Metoda najmniejszych kwadratów ( OLS, OLS, zwykła metoda najmniejszych kwadratów) - jedna z podstawowych metod analizy regresji służąca do estymacji nieznanych parametrów modeli regresji na podstawie przykładowych danych. Metoda polega na minimalizacji sumy kwadratów reszt regresji.
Należy zauważyć, że samą metodę najmniejszych kwadratów można nazwać metodą rozwiązywania problemu w dowolnym obszarze, jeśli rozwiązanie leży lub spełnia jakieś kryterium minimalizacji sumy kwadratów niektórych funkcji wymaganych zmiennych. Zatem metodę najmniejszych kwadratów można zastosować także do przybliżonego przedstawienia (aproksymacji) danej funkcji przez inne (prostsze) funkcje, gdy znajdziemy zbiór wielkości spełniających równania lub ograniczenia, których liczba przekracza liczbę tych wielkości itp.
Esencja MNC
Niech zostanie podany jakiś (parametryczny) model probabilistycznej (regresji) zależności pomiędzy (objaśnioną) zmienną y i wiele czynników (zmiennych objaśniających) X
gdzie jest wektorem nieznanych parametrów modelu
- losowy błąd modelu.Niech będą też przykładowe obserwacje wartości tych zmiennych. Niech będzie numerem obserwacji (). Następnie są wartości zmiennych w obserwacji. Następnie dla zadanych wartości parametrów b można obliczyć teoretyczne (modelowe) wartości zmiennej objaśnianej y:
Wielkość reszt zależy od wartości parametrów b.
Istotą metody najmniejszych kwadratów (zwykłej, klasycznej) jest znalezienie parametrów b, dla których suma kwadratów reszt (ang. Pozostała suma kwadratów) będzie minimalne:
W ogólnym przypadku problem ten można rozwiązać metodami optymalizacji numerycznej (minimalizacji). W tym przypadku o tym mówią nieliniowa metoda najmniejszych kwadratów(NLS lub NLLS – angielski) Nieliniowa metoda najmniejszych kwadratów). W wielu przypadkach możliwe jest otrzymanie rozwiązania analitycznego. Aby rozwiązać problem minimalizacji, należy znaleźć punkty stacjonarne funkcji, różniczkując ją ze względu na nieznane parametry b, przyrównując pochodne do zera i rozwiązując otrzymany układ równań:
Jeśli błędy losowe modelu mają rozkład normalny, mają tę samą wariancję i są nieskorelowane, oszacowania parametrów OLS są takie same jak oszacowania największej wiarygodności (MLM).
OLS w przypadku modelu liniowego
Niech zależność regresji będzie liniowa:
Pozwalać y jest wektorem kolumnowym obserwacji zmiennej objaśnianej i jest macierzą obserwacji czynnikowych (wiersze macierzy są wektorami wartości czynników w danej obserwacji, kolumny są wektorem wartości danego czynnika we wszystkich obserwacjach). Reprezentacja macierzowa modelu liniowego to:
Wtedy wektor oszacowań zmiennej objaśnianej i wektor reszt regresji będą równe
W związku z tym suma kwadratów reszt regresji będzie równa
Różniczkując tę funkcję względem wektora parametrów i przyrównując pochodne do zera, otrzymujemy układ równań (w postaci macierzowej):
.Rozwiązanie tego układu równań daje ogólny wzór na szacunki metodą najmniejszych kwadratów dla modelu liniowego:
Dla celów analitycznych przydatna jest druga reprezentacja tego wzoru. Jeśli w modelu regresji data wyśrodkowany, wówczas w tej reprezentacji pierwsza macierz ma znaczenie przykładowej macierzy kowariancji czynników, a druga jest wektorem kowariancji czynników ze zmienną zależną. Jeśli dodatkowo dane są również znormalizowany do MSE (czyli ostatecznie standaryzowane), wówczas pierwsza macierz ma znaczenie przykładowej macierzy korelacji czynników, drugi wektor - wektor przykładowych korelacji czynników ze zmienną zależną.
Ważna właściwość szacunków OLS dla modeli ze stałą- linia skonstruowanej regresji przechodzi przez środek ciężkości danych próbnych, czyli spełniona jest równość:
W szczególności w skrajnym przypadku, gdy jedynym regresorem jest stała, stwierdzamy, że estymacja OLS jedynego parametru (samej stałej) jest równa średniej wartości zmiennej objaśnianej. Oznacza to, że średnia arytmetyczna, znana ze swoich dobrych własności z praw wielkich liczb, jest jednocześnie estymacją metodą najmniejszych kwadratów – spełnia kryterium minimalnej sumy kwadratów odchyleń od niej.
Przykład: najprostsza regresja (parami).
W przypadku sparowanej regresji liniowej wzory obliczeniowe są uproszczone (można obejść się bez algebry macierzowej):
Własności estymatorów OLS
Przede wszystkim zauważamy, że w przypadku modeli liniowych estymatory OLS są estymatorami liniowymi, jak wynika z powyższego wzoru. Dla obiektywnych estymatorów OLS konieczne i wystarczające jest spełnienie najważniejszego warunku analizy regresji: matematyczne oczekiwanie błędu losowego, uzależnione od czynników, musi być równe zero. Warunek ten jest w szczególności spełniony, jeżeli
- matematyczne oczekiwanie błędów losowych wynosi zero, oraz
- czynniki i błędy losowe są niezależnymi zmiennymi losowymi.
Warunek drugi – warunek egzogeniczności czynników – jest zasadniczy. Jeśli ta właściwość nie jest spełniona, możemy założyć, że prawie wszystkie szacunki będą wyjątkowo niezadowalające: nie będą nawet spójne (to znaczy nawet bardzo duża ilość danych nie pozwala nam w tym przypadku uzyskać szacunków wysokiej jakości) ). W klasycznym przypadku przyjmuje się mocniejsze założenie o determinizmie czynników, w przeciwieństwie do błędu losowego, co automatycznie oznacza, że warunek egzogeniczności jest spełniony. W ogólnym przypadku, dla spójności estymatorów wystarczy spełnienie warunku egzogeniczności wraz ze zbieżnością macierzy do jakiejś macierzy nieosobliwej w miarę zwiększania się liczebności próby do nieskończoności.
Aby oprócz spójności i bezstronności estymacje metodą (zwykłych) najmniejszych kwadratów były także efektywne (najlepsze w klasie estymatorów liniowych nieobciążonych), muszą zostać spełnione dodatkowe właściwości błędu losowego:
Założenia te można sformułować dla macierzy kowariancji wektora błędu losowego
Model liniowy spełniający te warunki nazywa się klasyczny. Szacunki OLS dla klasycznej regresji liniowej są bezstronnymi, spójnymi i najbardziej efektywnymi estymacjami w klasie wszystkich liniowych nieobciążonych estymatorów (w literaturze angielskiej czasami używany jest skrót NIEBIESKI (Najlepszy liniowy estymator bez podstawy) - najlepsze liniowe, nieobciążone oszacowanie; w literaturze rosyjskiej częściej przytacza się twierdzenie Gaussa-Markowa). Jak łatwo wykazać, macierz kowariancji wektora oszacowań współczynników będzie równa:
Uogólnione OLS
Metoda najmniejszych kwadratów pozwala na szerokie uogólnienia. Zamiast minimalizować sumę kwadratów reszt, można zminimalizować pewną dodatnio określoną postać kwadratową wektora reszt, gdzie jest pewna symetryczna macierz dodatnich określonych wag. Szczególnym przypadkiem tego podejścia są konwencjonalne metody najmniejszych kwadratów, gdzie macierz wag jest proporcjonalna do macierzy jednostkowej. Jak wiadomo z teorii macierzy symetrycznych (lub operatorów), dla takich macierzy następuje rozkład. W związku z tym określony funkcjonał można przedstawić w następujący sposób, to znaczy funkcjonał ten można przedstawić jako sumę kwadratów niektórych przekształconych „reszt”. Można zatem wyróżnić klasę metod najmniejszych kwadratów – metody LS (ang. Least Squares).
Udowodniono (twierdzenie Aitkena), że dla uogólnionego modelu regresji liniowej (w którym nie nakłada się ograniczeń na macierz kowariancji błędów losowych) najbardziej efektywne (w klasie liniowych estymatorów nieobciążonych) są tzw. estymaty. uogólnione najmniejsze kwadraty (GLS – uogólnione najmniejsze kwadraty)- metoda LS z macierzą wag równą macierzy odwrotnej kowariancji błędów losowych: .
Można wykazać, że wzór na estymatory GLS parametrów modelu liniowego ma postać
Macierz kowariancji tych szacunków będzie odpowiednio równa
Tak naprawdę istota OLS polega na pewnej (liniowej) transformacji (P) danych pierwotnych i zastosowaniu zwykłego OLS do danych przekształconych. Celem tej transformacji jest to, że dla przekształconych danych błędy losowe spełniają już klasyczne założenia.
Ważony OLS
W przypadku diagonalnej macierzy wag (a więc i macierzy kowariancji błędów losowych) mamy do czynienia z tzw. ważoną metodą najmniejszych kwadratów (WLS). W tym przypadku suma ważona kwadratów reszt modelu jest minimalizowana, czyli każda obserwacja otrzymuje „wagę” odwrotnie proporcjonalną do wariancji błędu losowego w tej obserwacji: . W rzeczywistości dane są przekształcane poprzez ważenie obserwacji (podzielenie przez kwotę proporcjonalną do oszacowanego odchylenia standardowego błędów losowych), a do danych ważonych stosuje się zwykły OLS.
Kilka szczególnych przypadków wykorzystania MNC w praktyce
Aproksymacja zależności liniowej
Rozważmy przypadek, gdy w wyniku badania zależności pewnej wielkości skalarnej od pewnej wielkości skalarnej (może to być na przykład zależność napięcia od natężenia prądu: , gdzie jest wartością stałą, rezystancja przewodnik) przeprowadzono pomiary tych wielkości, w wyniku czego otrzymano wartości i odpowiadające im wartości. Dane pomiarowe należy zapisać w tabeli.
Tabela. Wyniki pomiarów.
| Pomiar nr. | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
Pytanie brzmi: jaką wartość współczynnika można wybrać, aby najlepiej opisać zależność? Według metody najmniejszych kwadratów wartość ta powinna być taka, aby suma kwadratów odchyleń wartości od wartości
był minimalny
Suma kwadratów odchyleń ma jedno ekstremum – minimum, co pozwala nam zastosować ten wzór. Znajdźmy z tego wzoru wartość współczynnika. Aby to zrobić, przekształcamy jego lewą stronę w następujący sposób:
Ostatni wzór pozwala nam znaleźć wartość współczynnika, czyli to, co było wymagane w zadaniu.
Fabuła
Do początków XIX wieku. naukowcy nie mieli pewnych zasad rozwiązywania układu równań, w którym liczba niewiadomych jest mniejsza niż liczba równań; Do tego czasu stosowano techniki prywatne, zależne od rodzaju równań i dowcipu kalkulatorów, dlatego różne kalkulatory, bazując na tych samych danych obserwacyjnych, dochodziły do różnych wniosków. Gauss (1795) jako pierwszy zastosował tę metodę, a Legendre (1805) niezależnie odkrył ją i opublikował pod jej współczesną nazwą (francuską. Méthode des moindres quarrés ) . Laplace powiązał tę metodę z teorią prawdopodobieństwa, a amerykański matematyk Adrain (1808) rozważał jej zastosowania w teorii prawdopodobieństwa. Metoda ta była szeroko rozpowszechniona i udoskonalona dzięki dalszym badaniom Encke, Bessela, Hansena i innych.
Alternatywne zastosowania OLS
Ideę metody najmniejszych kwadratów można zastosować także w innych przypadkach niezwiązanych bezpośrednio z analizą regresji. Faktem jest, że suma kwadratów jest jedną z najczęstszych miar bliskości wektorów (metryka euklidesowa w przestrzeniach skończenie wymiarowych).
Jednym z zastosowań jest „rozwiązanie” układów równań liniowych, w których liczba równań jest większa niż liczba zmiennych
gdzie macierz nie jest kwadratowa, ale prostokątna.
Taki układ równań w ogólnym przypadku nie ma rozwiązania (jeśli ranga jest rzeczywiście większa niż liczba zmiennych). Zatem układ ten można „rozwiązać” jedynie w sensie doboru takiego wektora, aby zminimalizować „odległość” pomiędzy wektorami a . Można w tym celu zastosować kryterium minimalizacji sumy kwadratów różnic pomiędzy lewą i prawą stroną równań układu, tj. Łatwo pokazać, że rozwiązanie tego problemu minimalizacji prowadzi do rozwiązania następującego układu równań